背景 说明:
Kernel版本:4.14
ARM64处理器,Contex-A53,双核
使用工具:Source Insight 3.5, Visio
1. 概述 RCU, Read-Copy-Update,是Linux内核中的一种同步机制。RCU常被描述为读写锁的替代品,它的特点是读者并不需要直接与写者进行同步,读者与写者也能并发的执行。RCU的目标就是最大程度来减少读者侧的开销,因此也常用于对读者性能要求高的场景。
优点:
读者侧开销很少、不需要获取任何锁,不需要执行原子指令或者内存屏障;
没有死锁问题;
没有优先级反转的问题;
没有内存泄露的危险问题;
很好的实时延迟;
缺点:
写者的同步开销比较大,写者之间需要互斥处理;
使用上比其他同步机制复杂;
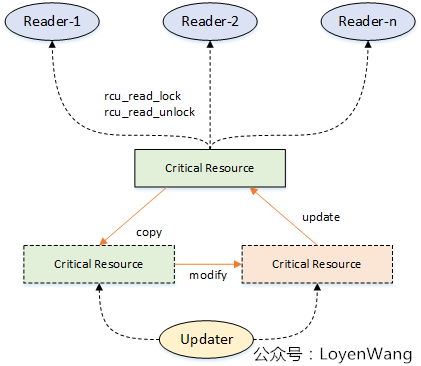
来一张图片来描述下大体的操作吧:
多个读者可以并发访问临界资源,同时使用rcu_read_lock/rcu_read_unlock来标定临界区;
写者(updater)在更新临界资源的时候,拷贝一份副本作为基础进行修改,当所有读者离开临界区后,把指向旧临界资源的指针指向更新后的副本,并对旧资源进行回收处理;
图中只显示一个写者,当存在多个写者的时候,需要在写者之间进行互斥处理;
上述的描述比较简单,RCU的实现很复杂。本文先对RCU来一个初印象,并结合接口进行实例分析,后续文章再逐层深入到背后的实现原理。开始吧!
2. RCU基础 2.1 RCU基本要素 RCU的基本思想是将更新Update操作分为两个部分:1)Removal移除;2)Reclamation回收。kfree)。
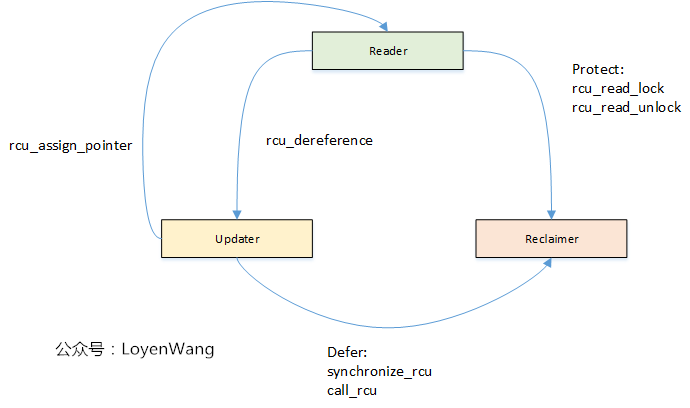
因此,从功能上分为以下三个基本的要素:Reader/Updater/Reclaimer,三者之间的交互如下图:
Reader
使用rcu_read_lock和rcu_read_unlock来界定读者的临界区,访问受RCU保护的数据时,需要始终在该临界区域内访问;
在访问受保护的数据之前,需要使用rcu_dereference来获取RCU-protected指针;
当使用不可抢占的RCU时,rcu_read_lock/rcu_read_unlock之间不能使用可以睡眠的代码;
Updater
多个Updater更新数据时,需要使用互斥机制进行保护;
Updater使用rcu_assign_pointer来移除旧的指针指向,指向更新后的临界资源;
Updater使用synchronize_rcu或call_rcu来启动Reclaimer,对旧的临界资源进行回收,其中synchronize_rcu表示同步等待回收,call_rcu表示异步回收;
Reclaimer
Reclaimer回收的是旧的临界资源;
为了确保没有读者正在访问要回收的临界资源,Reclaimer需要等待所有的读者退出临界区,这个等待的时间叫做宽限期(Grace Period);
2.2 RCU三个基本机制 用来提供上述描述的功能,RCU基于三种机制来实现。
2.2.1 Publish-Subscribe Mechanism 订阅机制是个什么概念,来张图:
Updater与Reader类似于Publisher和Subsriber的关系;Updater更新内容后调用接口进行发布,Reader调用接口读取发布内容;
那么这种订阅机制,需要做点什么来保证呢?来看一段伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 1 struct foo { 2 int a; 3 int b; 4 int c; 5 }; 6 struct foo *gp =NULL ; 7 8 9 10 p = kmalloc(sizeof (*p), GFP_KERNEL);11 p->a = 1 ;12 p->b = 2 ;13 p->c = 3 ;14 gp = p;15 16 17 p = gp;18 if (p != NULL ) {19 do_something_with(p->a, p->b, p->c);20 }
乍一看似乎问题不大,Updater进行赋值更新,Reader进行读取和其他处理。然而,由于存在编译乱序和执行乱序的问题,上述代码的执行顺序不见得就是代码的顺序,比如在某些架构(DEC Alpha)中,读者的操作部分,可能在p赋值之前就操作了do_something_with()。
为了解决这个问题,Linux提供了rcu_assign_pointer/rcu_dereference宏来确保执行顺序,Linux内核也基于rcu_assign_pointer/rcu_dereference宏进行了更高层的封装,比如list, hlist,因此,在内核中有三种被RCU保护的场景:1)指针;2)list链表;3)hlist哈希链表。
针对这三种场景,Publish-Subscribe接口如下表:
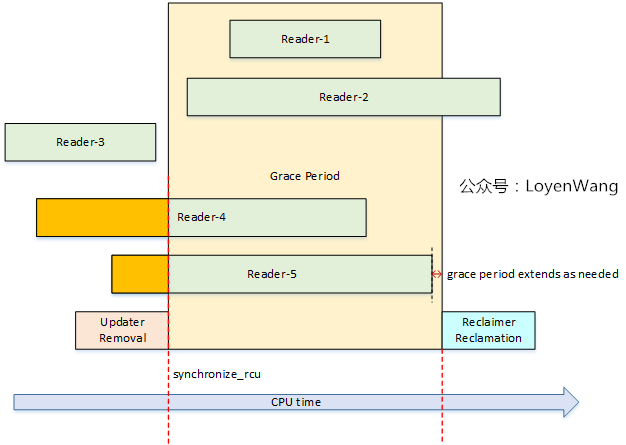
2.2.2 Wait For Pre-Existing RCU Readers to Complete Reclaimer需要对旧的临界资源进行回收,那么问题来了,什么时候进行呢?因此RCU需要提供一种机制来确保之前的RCU读者全部都已经完成,也就是退出了rcu_read_lock/rcu_read_unlock标定的临界区后,才能进行回收处理。
图中Readers和Updater并发执行;
当Updater执行Removal操作后,调用synchronize_rcu,标志着更新结束并开始进入回收阶段;
在synchronize_rcu调用后,此时可能还有新的读者来读取临界资源(更新后的内容),但是,Grace Period只等待Pre-Existing的读者,也就是在图中的Reader-4, Reader-5。只要这些之前就存在的RCU读者退出临界区后,意味着宽限期的结束,因此就进行回收处理工作了;
synchronize_rcu并不是在最后一个Pre-ExistingRCU读者离开临界区后立马就返回,它可能存在一个调度延迟;
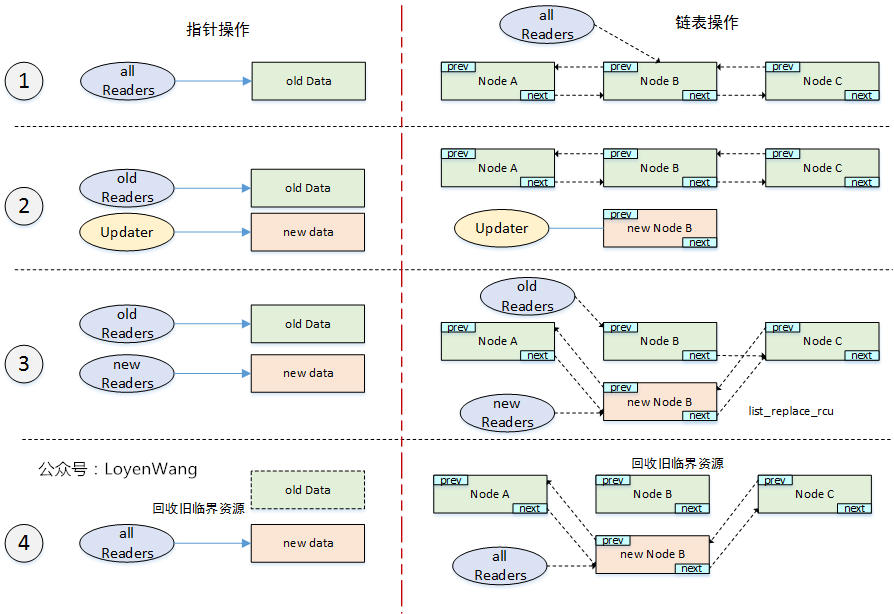
2.2.3 Maintain Multiple Versions of Recently Updated Objects 从2.2.2节可以看出,在Updater进行更新后,在Reclaimer进行回收之前,是会存在新旧两个版本的临界资源的,只有在synchronize_rcu返回后,Reclaimer对旧的临界资源进行回收,最后剩下一个版本。显然,在有多个Updater时,临界资源的版本会更多。
还是来张图吧,分别以指针和链表为例:
调用synchronize_rcu开始为临界点,分别维护不同版本的临界资源;
等到Reclaimer回收旧版本资源后,最终归一统;
3. RCU示例分析 是时候来一波fucking sample code了。
整体的代码逻辑:
构造四个内核线程,两个内核线程测试指针的RCU保护操作,两个内核线程用于测试链表的RCU保护操作;
在回收的时候,分别用了synchronize_rcu同步回收和call_rcu异步回收两种机制;
为了简化代码,基本的容错判断都已经省略了;
没有考虑多个Updater的机制,因此,也省略掉了Updater之间的互斥操作;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 #include <linux/module.h> #include <linux/init.h> #include <linux/slab.h> #include <linux/kthread.h> #include <linux/rcupdate.h> #include <linux/delay.h> struct foo { int a; int b; int c; struct rcu_head rcu ; struct list_head list ; }; static struct foo *g_pfoo =NULL ;LIST_HEAD(g_rcu_list); struct task_struct *rcu_reader_t ;struct task_struct *rcu_updater_t ;struct task_struct *rcu_reader_list_t ;struct task_struct *rcu_updater_list_t ;static int rcu_reader (void *data) { struct foo *p =NULL ; int cnt = 100 ; while (cnt--) { msleep(100 ); rcu_read_lock(); p = rcu_dereference(g_pfoo); pr_info("%s: a = %d, b = %d, c = %d\n" , __func__, p->a, p->b, p->c); rcu_read_unlock(); } return 0 ; } static void rcu_reclaimer (struct rcu_head *rh) { struct foo *p =struct foo, rcu); pr_info("%s: a = %d, b = %d, c = %d\n" , __func__, p->a, p->b, p->c); kfree(p); } static int rcu_updater (void *data) { int value = 1 ; int cnt = 100 ; while (cnt--) { struct foo *old ; struct foo *new =struct foo *)kzalloc(sizeof (struct foo), GFP_KERNEL); msleep(200 ); old = g_pfoo; *new = *g_pfoo; new->a = value; new->b = value + 1 ; new->c = value + 2 ; rcu_assign_pointer(g_pfoo, new); pr_info("%s: a = %d, b = %d, c = %d\n" , __func__, new->a, new->b, new->c); call_rcu(&old->rcu, rcu_reclaimer); value++; } return 0 ; } static int rcu_reader_list (void *data) { struct foo *p =NULL ; int cnt = 100 ; while (cnt--) { msleep(100 ); rcu_read_lock(); list_for_each_entry_rcu(p, &g_rcu_list, list ) { pr_info("%s: a = %d, b = %d, c = %d\n" , __func__, p->a, p->b, p->c); } rcu_read_unlock(); } return 0 ; } static int rcu_updater_list (void *data) { int cnt = 100 ; int value = 1000 ; while (cnt--) { msleep(100 ); struct foo *p =struct foo, list ); struct foo *q =struct foo *)kzalloc(sizeof (struct foo), GFP_KERNEL); *q = *p; q->a = value; q->b = value + 1 ; q->c = value + 2 ; list_replace_rcu(&p->list , &q->list ); pr_info("%s: a = %d, b = %d, c = %d\n" , __func__, q->a, q->b, q->c); synchronize_rcu(); kfree(p); value++; } return 0 ; } static int rcu_test_init (void ) { struct foo *p ; rcu_reader_t = kthread_run(rcu_reader, NULL , "rcu_reader" ); rcu_updater_t = kthread_run(rcu_updater, NULL , "rcu_updater" ); rcu_reader_list_t = kthread_run(rcu_reader_list, NULL , "rcu_reader_list" ); rcu_updater_list_t = kthread_run(rcu_updater_list, NULL , "rcu_updater_list" ); g_pfoo = (struct foo *)kzalloc(sizeof (struct foo), GFP_KERNEL); p = (struct foo *)kzalloc(sizeof (struct foo), GFP_KERNEL); list_add_rcu(&p->list , &g_rcu_list); return 0 ; } static void rcu_test_exit (void ) { kfree(g_pfoo); kfree(list_first_or_null_rcu(&g_rcu_list, struct foo, list )); kthread_stop(rcu_reader_t ); kthread_stop(rcu_updater_t ); kthread_stop(rcu_reader_list_t ); kthread_stop(rcu_updater_list_t ); } module_init(rcu_test_init); module_exit(rcu_test_exit); MODULE_AUTHOR("Loyen" ); MODULE_LICENSE("GPL" );
为了证明没有骗人,贴出在开发板上运行的输出log,如下图:
4. API介绍 4.1 核心API 下边的这些接口,不能更核心了。
1 2 3 4 5 a. rcu_read_lock() b. rcu_read_unlock() c. synchronize_rcu() / call_rcu() d. rcu_assign_pointer() e. rcu_dereference()
4.2 其他相关API 基于核心的API,扩展了其他相关的API,如下,不再详述:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 RCU list traversal:: list_entry_rcu list_entry_lockless list_first_entry_rcu list_next_rcu list_for_each_entry_rcu list_for_each_entry_continue_rcu list_for_each_entry_from_rcu list_first_or_null_rcu list_next_or_null_rcu hlist_first_rcu hlist_next_rcu hlist_pprev_rcu hlist_for_each_entry_rcu hlist_for_each_entry_rcu_bh hlist_for_each_entry_from_rcu hlist_for_each_entry_continue_rcu hlist_for_each_entry_continue_rcu_bh hlist_nulls_first_rcu hlist_nulls_for_each_entry_rcu hlist_bl_first_rcu hlist_bl_for_each_entry_rcu RCU pointer/list update:: rcu_assign_pointer list_add_rcu list_add_tail_rcu list_del_rcu list_replace_rcu hlist_add_behind_rcu hlist_add_before_rcu hlist_add_head_rcu hlist_add_tail_rcu hlist_del_rcu hlist_del_init_rcu hlist_replace_rcu list_splice_init_rcu list_splice_tail_init_rcu hlist_nulls_del_init_rcu hlist_nulls_del_rcu hlist_nulls_add_head_rcu hlist_bl_add_head_rcu hlist_bl_del_init_rcu hlist_bl_del_rcu hlist_bl_set_first_rcu RCU:: Critical sections Grace period Barrier rcu_read_lock synchronize_net rcu_barrier rcu_read_unlock synchronize_rcu rcu_dereference synchronize_rcu_expedited rcu_read_lock_held call_rcu rcu_dereference_check kfree_rcu rcu_dereference_protected bh:: Critical sections Grace period Barrier rcu_read_lock_bh call_rcu rcu_barrier rcu_read_unlock_bh synchronize_rcu [local_bh_disable] synchronize_rcu_expedited [and friends] rcu_dereference_bh rcu_dereference_bh_check rcu_dereference_bh_protected rcu_read_lock_bh_held sched:: Critical sections Grace period Barrier rcu_read_lock_sched call_rcu rcu_barrier rcu_read_unlock_sched synchronize_rcu [preempt_disable] synchronize_rcu_expedited [and friends] rcu_read_lock_sched_notrace rcu_read_unlock_sched_notrace rcu_dereference_sched rcu_dereference_sched_check rcu_dereference_sched_protected rcu_read_lock_sched_held SRCU:: Critical sections Grace period Barrier srcu_read_lock call_srcu srcu_barrier srcu_read_unlock synchronize_srcu srcu_dereference synchronize_srcu_expedited srcu_dereference_check srcu_read_lock_held SRCU: Initialization/cleanup:: DEFINE_SRCU DEFINE_STATIC_SRCU init_srcu_struct cleanup_srcu_struct All: lockdep-checked RCU-protected pointer access:: rcu_access_pointer rcu_dereference_raw RCU_LOCKDEP_WARN rcu_sleep_check RCU_NONIDLE
好吧,罗列这些API有点然并卵。
RCU这个神秘的面纱算是初步揭开了,再往里边扒衣服的话,就会显得有些难了,毕竟RCU背后的实现机制确实挺困难的。那么,问题来了,要不要做一个扒衣见君者呢,敬请关注吧。
参考 Documentation/RCU What is RCU, Fundamentally? What is RCU? Part 2: Usage RCU part 3: the RCU API Introduction to RCU