
Kuberbetes 核心组件(一)
0 参考资料
课程:《云原生训练营》
书籍:《Kubernetes源码剖析》、《深入浅出Kuberbetes》
Kubernetes官网文档:https://kubernetes.io/zh-cn/docs/home/
代码走读:https://cncamp.notion.site/kubernetes-8a9d48ee26284b3c8ddf9de4c62ea895
1 Kube-APIServer
1.1 概述
kube-apiserver是Kubernetes最重要的核心组件之一,主要提供以下的功能:
- 提供集群管理的REST API接口,包括 认证授权、数据校验、集群状态变更等
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过API Server查询或修改数据,只有API Server才直接操作etcd)
1.1.1 Kubernetes Pod资源创建流程
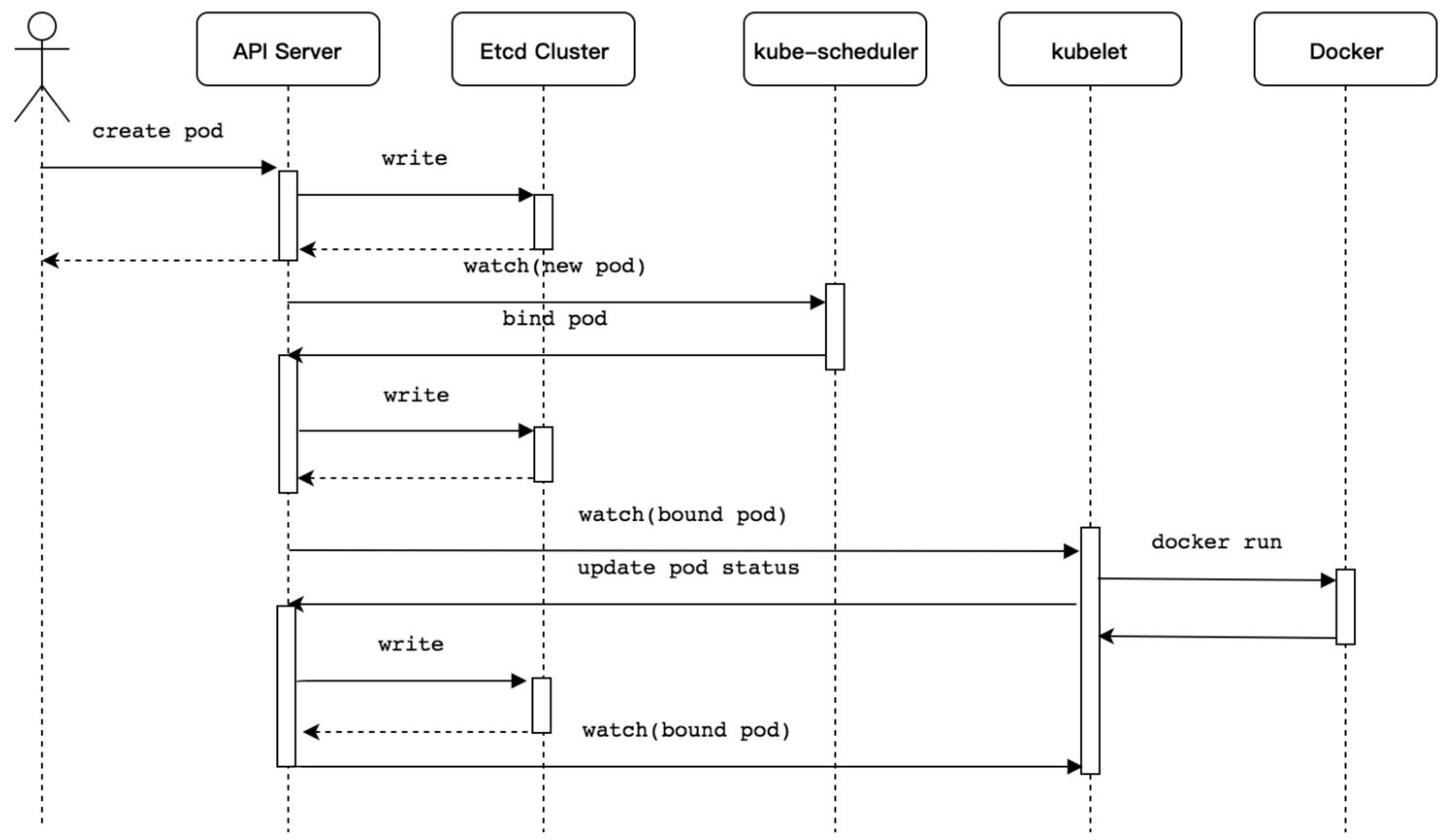
Kubernetes Pod资源对象创建流程介绍如下:
- 使用kubectl工具向Kubernetes API Server发起创建Pod资源对象的请求。
- Kubernetes API Server验证请求并将其持久保存到Etcd集群中。
- Kubernetes API Server基于Watch机制通知kube-scheduler调度器。
- kube-scheduler调度器根据预选和优选调度算法为Pod资源对象选择最优的节点并通知Kubernetes API Server。
- Kubernetes API Server将最优节点持久保存到Etcd集群中。
- Kubernetes API Server通知最优节点上的kubelet组件。
- kubelet组件在所在的节点上通过与容器进程交互创建容器。
- kubelet组件将容器状态上报至Kubernetes API Server。
- Kubernetes API Server将容器状态持久保存到Etcd集群中。
1.2 访问控制概览
Kubernetes API的每个请求都会经过多阶段的访问控制之后才会接受,包括认证、授权、准入控制等。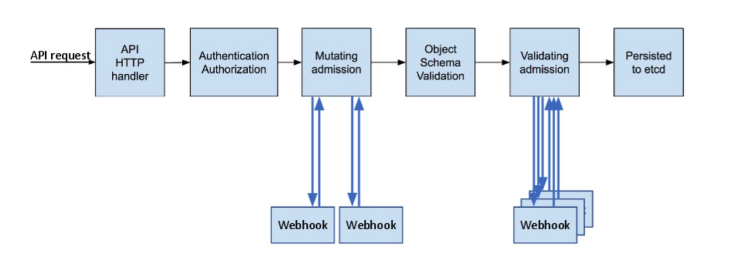
访问控制的细节: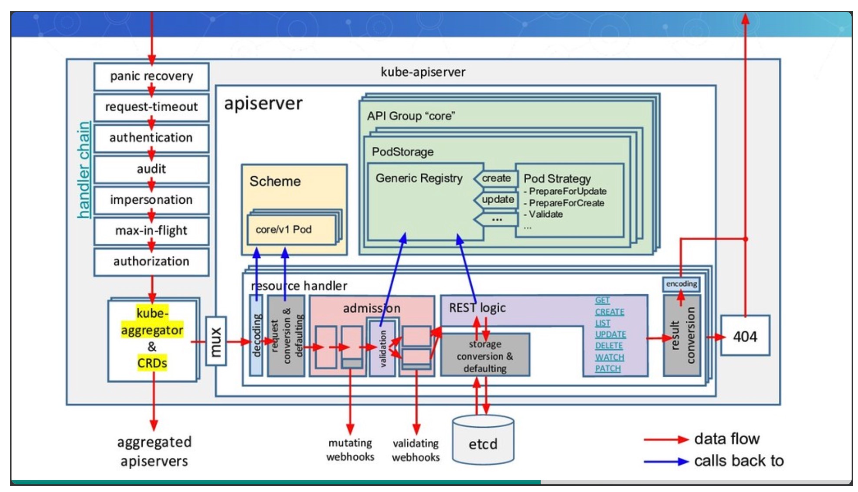
1.3 kube-apiserver 中的认证
1.3.1 认证方式
kube-apiserver 具有的的认证方式如下:
- X509证书
使用X509客户端证书只需要API Server启动时配置–client-ca-file=SOMEFILE。在证书认证时,其CN域用作用户名,而组织机构域则用作group名。
- 静态Token文件
使用静态Token文件认证只需要API Server启动时配置–token-auth-file=SOMEFILE。
该文件为csv格式,每行至少包括三列token,username,user id,如:token,user,uid,"group1,group2,group3”
- 引导Token
- 为了支持平滑地启动引导新的集群,Kubernetes 包含了一种动态管理的持有者令牌类型, 称作 启动引导令牌(Bootstrap Token)。
- 这些令牌以 Secret 的形式保存在 kube-system 名字空间中,可以被动态管理和创建。
- 控制器管理器包含的 TokenCleaner 控制器能够在启动引导令牌过期时将其删除。
- 在使用kubeadm部署Kubernetes时,可通过kubeadm token list命令查询。
- ServiceAccount
ServiceAccount是Kubernetes自动生成的,并会自动挂载到容器的/run/secrets/kubernetes.io/serviceaccount目录中。在kubernetes内部的组件,会使用此方式,在启动时组件时直接挂载 serviceaccount 。
- Webhook 令牌身份认证
通过Webhook的方式,可以接入第三方认证服务,认证通过后,把结果返回给 kube-apiserver,这样可以复用项目中已有的认证方式。
- –authentication-token-webhook-config-file 指向一个配置文件,其中描述 如何访问远程的 Webhook 服务。
- –authentication-token-webhook-cache-ttl 用来设定身份认证决定的缓存时间。 默认时长为 2 分钟。
- OpenID
OAuth 2.0的认证机制
1.3.2 基于webhook集成认证服务
参考项目: https://github.com/cncamp/101/tree/master/module6/authn-webhook
1.3.2.1 构建符合kubernetes规范的认证服务
需要依照kubernetes规范,构建认证服务,用来认证 tokenreview request
构建认证服务: 认证服务需要提供如下的规范:
- URL:http://authn.example.com/authenticate
- Method: POST
- Input:
- Output:
1.3.2.2 操作步骤
- Start authservice
1 | make build |
- Create webhook config
1 | mkdir -p /etc/config |
- Backup old apiserver
1 | cp /etc/kubernetes/manifests/kube-apiserver.yaml ~/kube-apiserver.yaml |
- Update apiserver configuration to enable webhook
1 | cp specs/kube-apiserver.yaml /etc/kubernetes/manifests/kube-apiserver.yaml |
- Create a personal access token in github and put your github personal access token to kubeconfig
1 | vi ~/.kube/config |
1 | - name: baihl |
- Get pods by baihl
1 | kubectl get po --user baihl |
- Reset the env
1 | cp ~/kube-apiserver.yaml /etc/kubernetes/manifests/kube-apiserver.yaml |
1.3.2.3 代码示例
1 | package main |
编译Makefile:
1 | build: |
1.3.2.4 修改 kube-apiserver.yaml
增加如下配置:
1 | --authentication-token-webhook-config-file=/etc/config/webhook-config.json |
apiserver保证把所有收到的请求中的token信息,发送给认证服务进行验证。
--authentication-token-webhook-config-file指向一个配置文件,其中描述 如何访问远程的 Webhook 服务。--authentication-token-webhook-cache-ttl用来设定身份认证决定的缓存时间。 默认时长为 2 分钟。
webhook-config.json 文件如下:
1 | { |
文件中指定了认证服务的地址为:http://192.168.34.2:3000/authenticate
配置文件需要mount 进 Pod中,否则 kube-apiserver 启动时读不到。
1.4 kube-apiserver 中的鉴权
1.4.1 概述
鉴权主要用于对集群资源的访问控制,通过检查请求包含的相关属性值,与相对应的访问策略相比较,API请求必须满足某些策略才能被处理。跟认证类似,Kubernetes也支持多种授权机制,并支持同时开启多个授权插件(只要有一个验证通过即 可)。如果授权成功,则用户的请求会发送到准入控制模块做进一步的请求验证;对于授权失败的请求则返回HTTP 403。
Kubernetes授权仅处理以下的请求属性:
- user, group, extra
- API、请求方法(如get、post、update、patch和delete)和请求路径(如/api)
- 请求资源和子资源
- Namespace
- API Group
Kubernetes支持以下授权插件:
- ABAC
- RBAC
- Webhook
- Node
1.4.2 RBAC vs ABAC
ABAC(Attribute Based Access Control)本来是不错的概念,但是在 Kubernetes 中的实现比较 难于管理和理解,而且需要对 Master 所在节点的 SSH 和文件系统权限,要使得对授权的变更成 功生效,还需要重新启动 API Server。
而 RBAC 的授权策略可以利用 kubectl 或者 Kubernetes API 直接进行配置。RBAC 可以授权给用户, 让用户有权进行授权管理,这样就可以无需接触节点,直接进行授权管理。RBAC 在 Kubernetes 中被映射为 API 资源和操作。
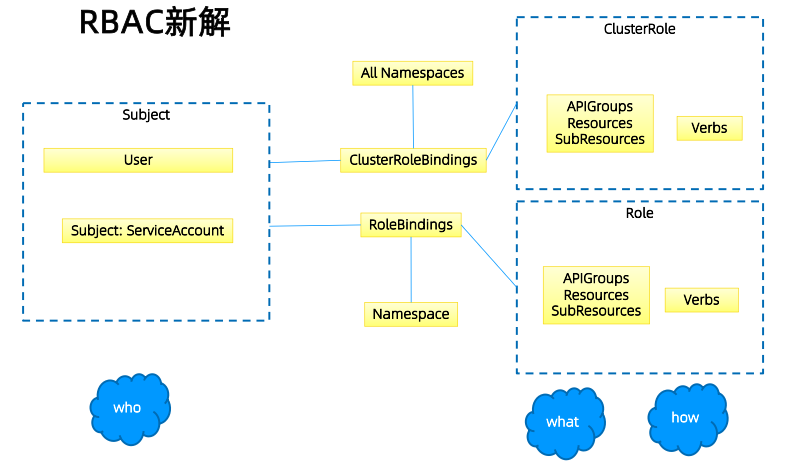
1.4.3 Role 和 ClusterRole
Role(角色)是一系列权限的集合,例如一个角色可以包含读取 Pod 的权限和列出 Pod 的权限。 Role只能用来给某个特定namespace中的资源作鉴权,对多namespace和集群级的资源或者是非资源类的API(如/healthz)使用ClusterRole。
1.4.4 binding
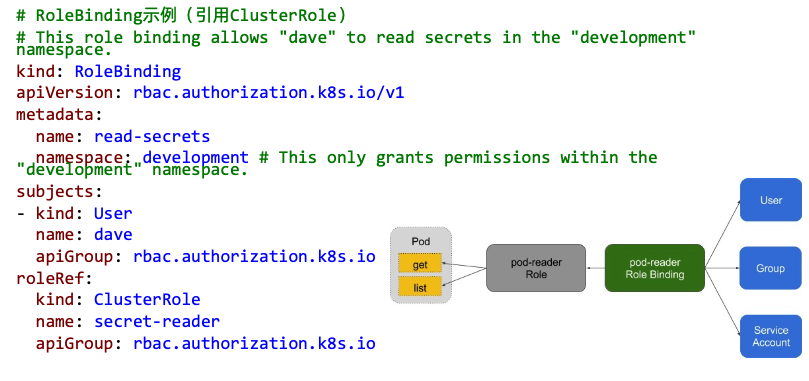
1.4.5 账户/组的管理
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。
它包含若干 主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用。 组的概念:
- 当与外部认证系统对接时,用户信息(UserInfo)可包含Group信息,授权可针对用户群组
- 当对ServiceAccount授权时,Group代表某个Namespace下的所有ServiceAccount
针对群组授权: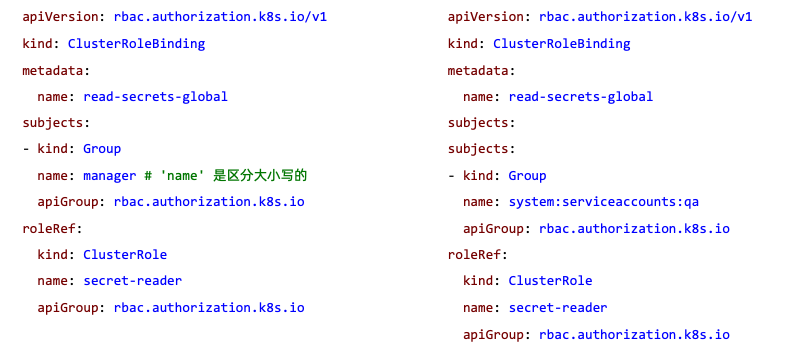
1.4.6 规划系统角色



1.5 准入
1.5.1 准入控制
准入控制(Admission Control)在授权后对请求做进一步的验证或添加默认参数。不同于授权 和认证只关心请求的用户和操作,准入控制还处理请求的内容,并且仅对创建、更新、删除或连 接(如代理)等有效,而对读操作无效。
准入控制支持同时开启多个插件,它们依次调用,只有全部插件都通过的请求才可以放过进入系统。
kube-apiserver大概分为如下两种准入控制器:
- 变更准入控制器(Mutating Admission Controller): 用于变更信息,能够修改用户提交的资源对象信息。
- 验证准入控制器(Validating Admission Controller): 用于身份验证,能够验证用户提交的资源对象信息。
准入控制插件:
- AlwaysAdmit: 接受所有请求。
- AlwaysPullImages: 总是拉取最新镜像。在多租户场景下非常有用。
- DenyEscalatingExec: 禁止特权容器的exec和attach操作。
- ImagePolicyWebhook: 通过webhook决定image策略,需要同时配置–admission-control- config-file
- ServiceAccount:自动创建默认ServiceAccount,并确保Pod引用的ServiceAccount已经存在 SecurityContextDeny:拒绝包含非法SecurityContext配置的容器
- ResourceQuota:限制Pod的请求不会超过配额,需要在namespace中创建一个 ResourceQuota对象
- LimitRanger:为Pod设置默认资源请求和限制,需要在namespace中创建一个LimitRange对 象
- InitialResources:根据镜像的历史使用记录,为容器设置默认资源请求和限制
- NamespaceLifecycle:确保处于termination状态的namespace不再接收新的对象创建请求, 并拒绝请求不存在的namespace
- DefaultStorageClass:为PVC设置默认StorageClass DefaultTolerationSeconds:设置Pod的默认forgiveness toleration为5分钟 PodSecurityPolicy:使用Pod Security Policies时必须开启
- NodeRestriction:限制kubelet仅可访问node、endpoint、pod、service以及secret、 configmap、PV和PVC等相关的资源
1.5.2 示例:配额管理
资源有限,如何限定某个用户有多少资源?
方案:
- 预定义每个Namespace的ResourceQuota,并把spec保存为configmap
- 用户可以创建多少个Pod:BestEffortPod、QoSPod
- 用户可以创建多少个Service
- 用户可以创建多少个ingress
- 用户可以创建多少个service VIP
- 创建ResourceQuota Controller
- 监控namespace创建事件,当namespace创建时,在该namespace创建对应的ResourceQuota对象
- apiserver中开启ResourceQuota的admission plugin
1.5.3 准入控制插件的开发
除默认的准入控制插件以外,Kubernetes预留了准入控制插件的扩展点,用户可自定义准入控制 插件实现自定义准入功能。
MutatingWebhookConfiguration:变形插件,支持对准入对象的修改ValidatingWebhookConfiguration:校验插件,只能对准入对象合法性进行校验,不能修改
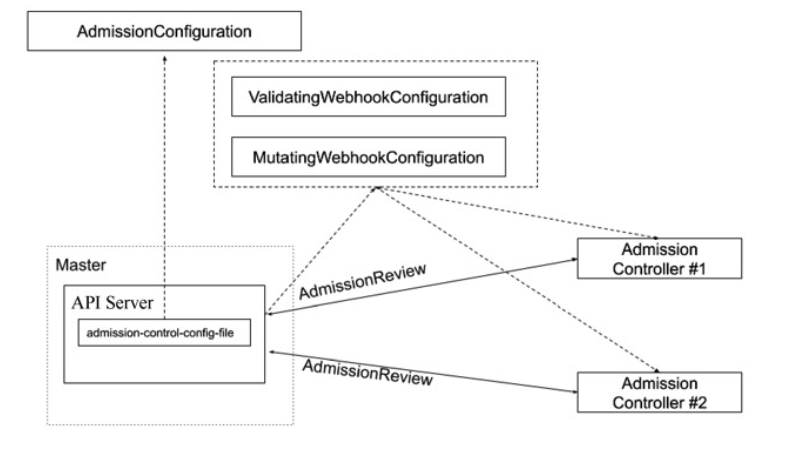
准入控制:
为资源增加自定义属性:
作为多租户集群方案中的一环,需要在namespace的准入控制中,获取用户信息,并将用户信息更新的namespace的annotation。
只有当namespace中有有效用户信息时,才可以在namespace创建时,自动绑定用户权限,namespace才可用。
示例项目: https://github.com/cncamp/admission-controller-webhook-demo
测试流程:
- Clone admission demo
1 | git clone https://github.com/cncamp/admission-controller-webhook-demo.git |
- Deploy webhook
1 | cd admission-controller-webhook-demo/ |
- Check webhook status
1 | k get deployment.apps/webhook-server -n webhook-demo |
- Create demo pod and verify
1 | kubectl create -f examples/pod-with-defaults.yaml |
1.6 kube-apiserver 源码剖析
使用 k8s 相关 sdk 做二次开发时,经常用到 apimachinery、api、client-go 这三个库,具体介绍如下:
- apimachinery 是最基础的库,包括核心的数据结构,比如 Scheme、Group、Version、Kind、Resource,以及排列组合出来的 常用的GVK、GV、GK、GVR等等,再就是编码、解码等操作
- api 库,这个库依赖 apimachinery,提供了k8s的内置资源,以及注册到 Scheme 的接口,这些资源比如:Pod、Service、Deployment、Namespace
- client-go 库,这个库依赖前两个库,提供了访问k8s 内置资源的sdk,最常用的就是 clientSet。底层通过 http 请求访问k8s 的 api-server,从etcd获取资源信息
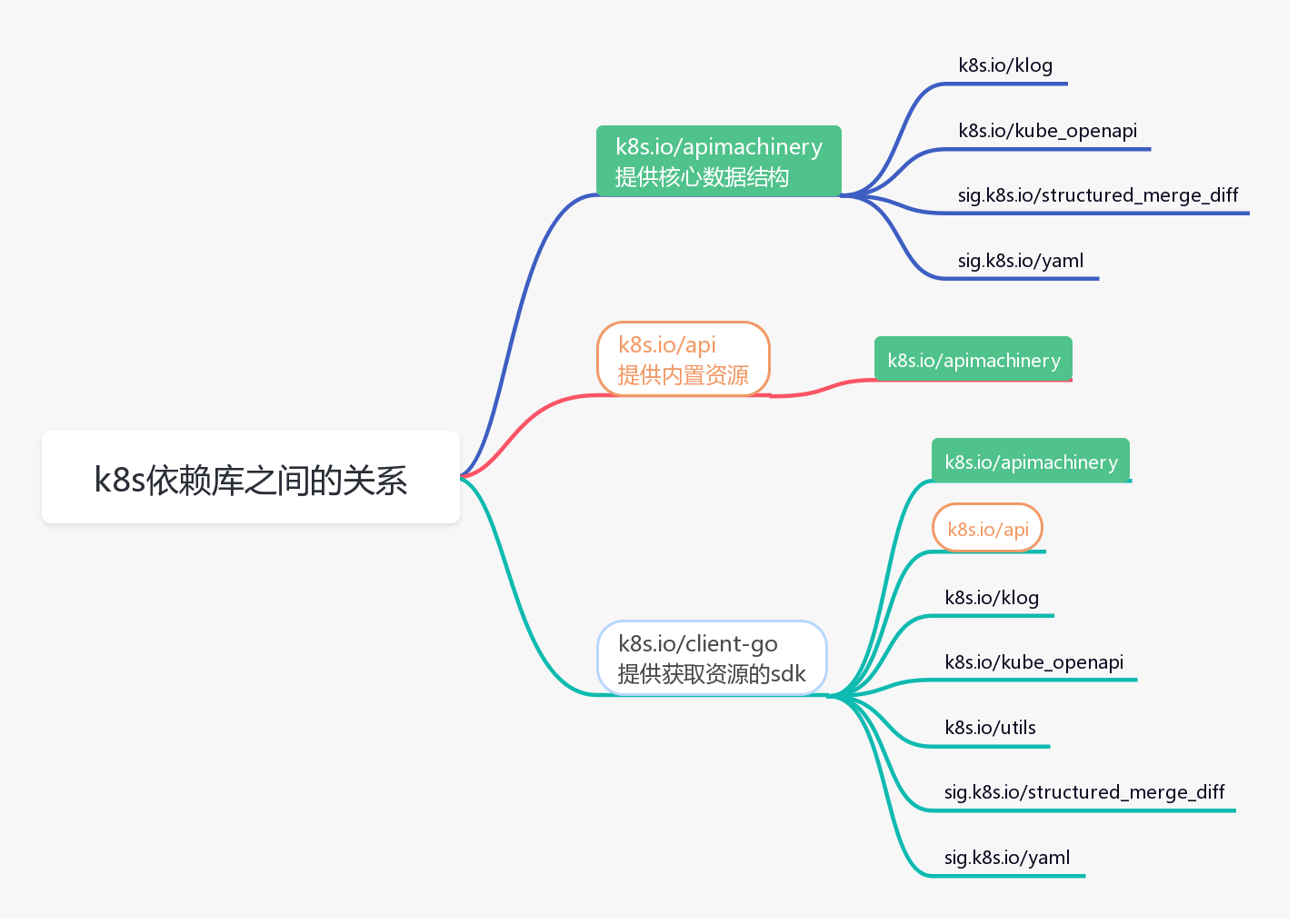
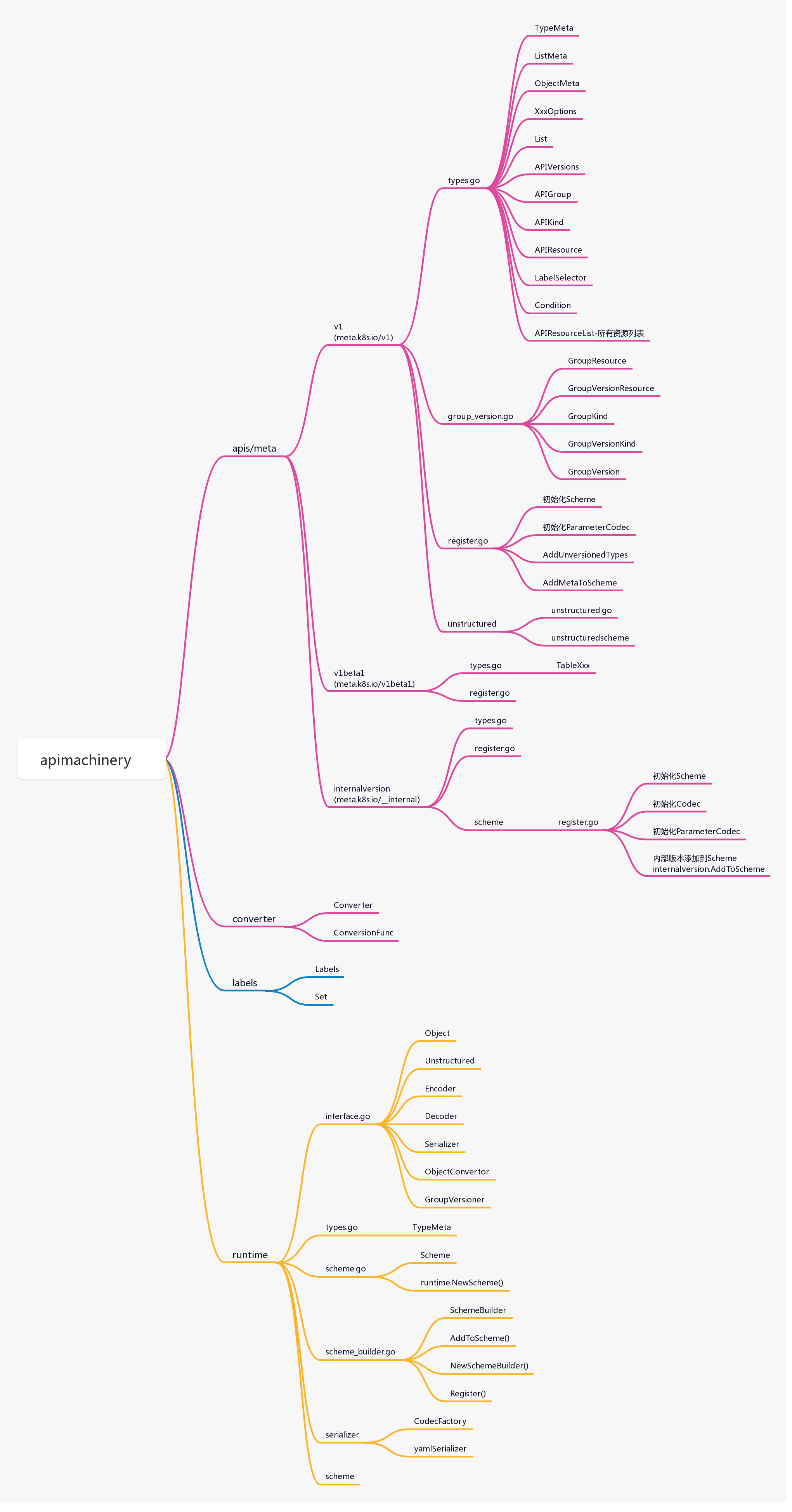
1.6.1 apimachinery
apimachinery提供k8s最核心的数据结构。
1.6.2 api
api 库提供了k8s的内置资源,以及注册到 Scheme 的接口,这些资源比如:Pod、Service、Deployment、Namespace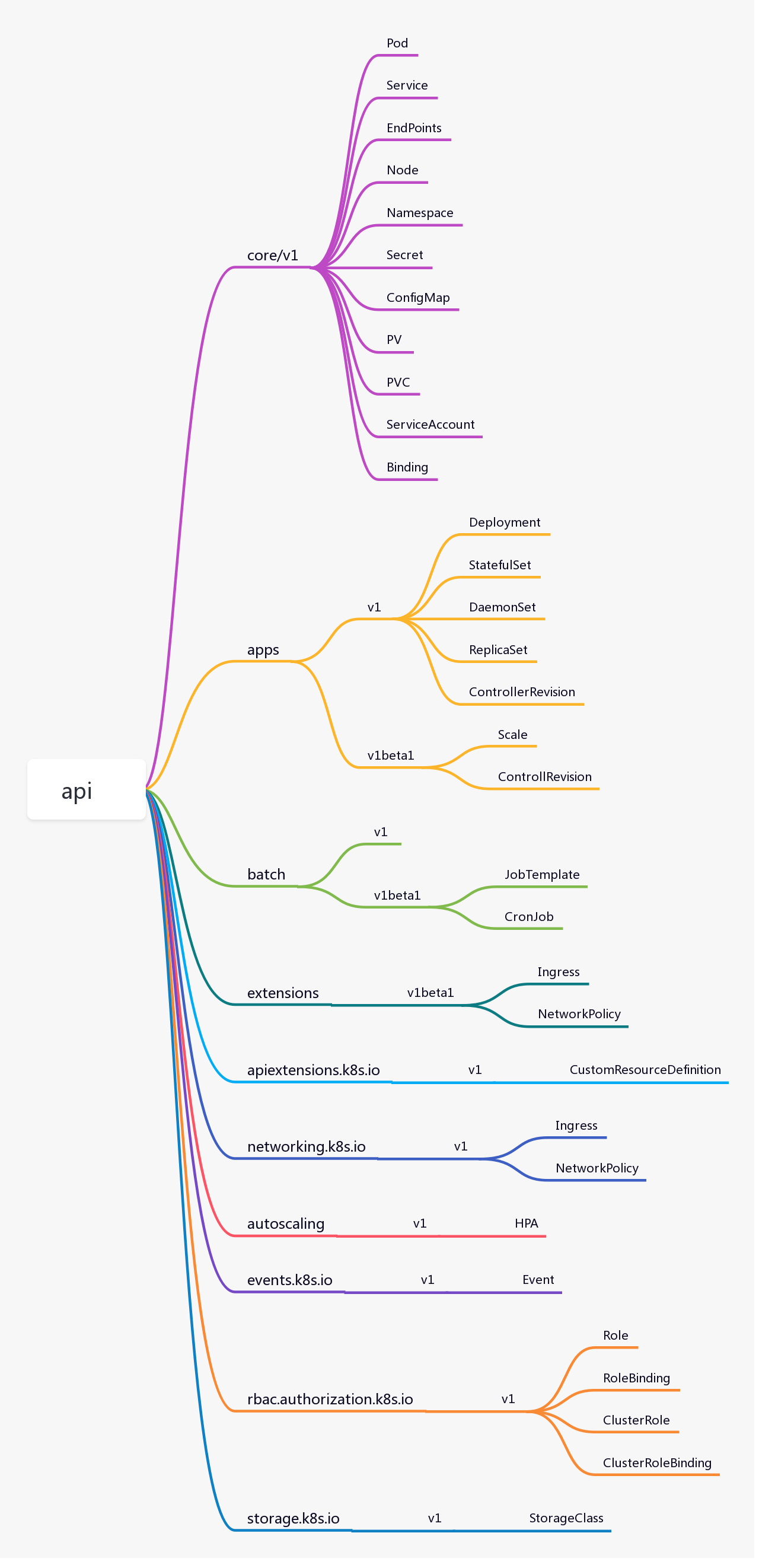
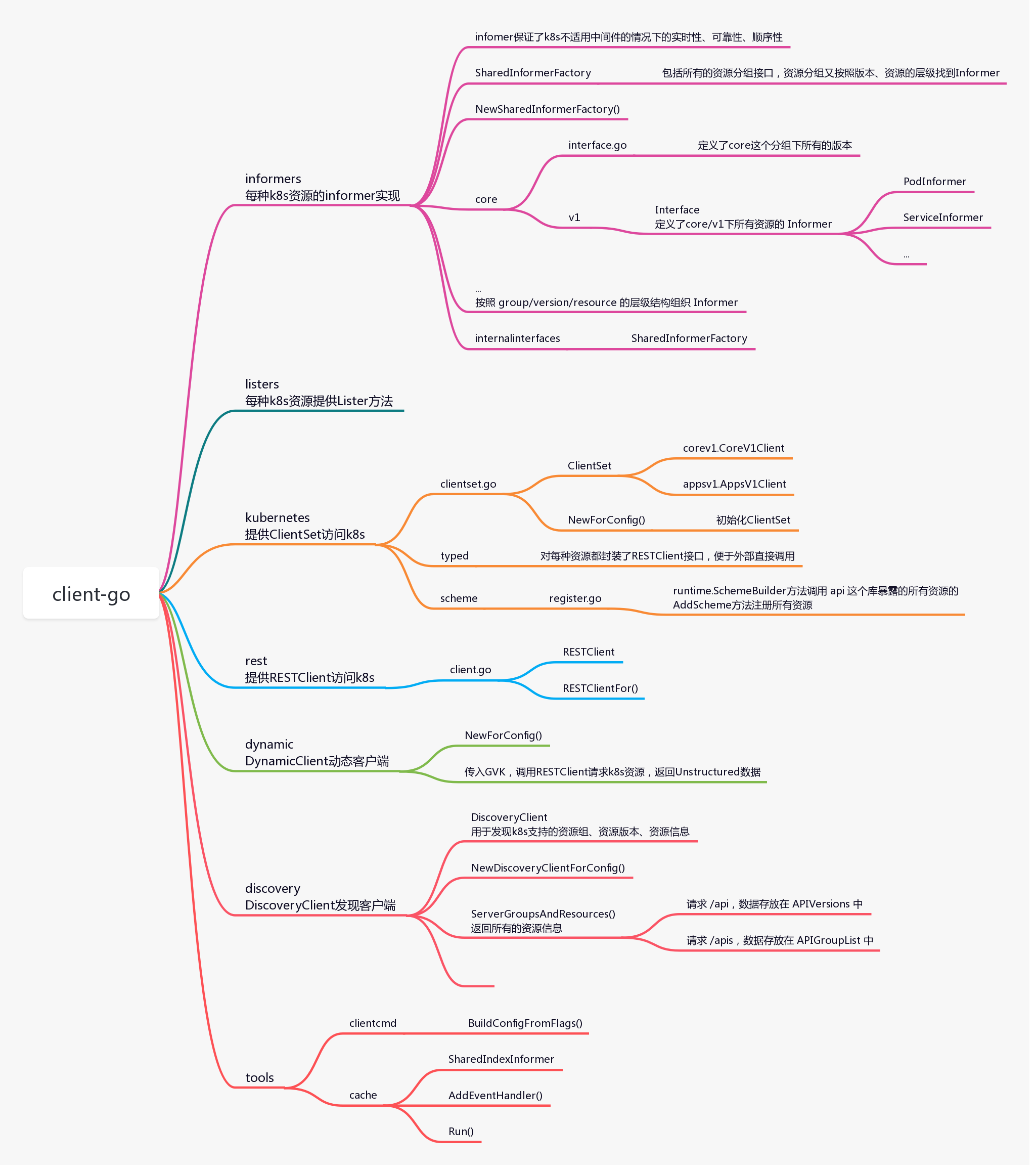
1.6.3 client-go
client-go 库访问k8s 内置资源的sdk,最常用的就是 clientSet。底层通过 http 请求访问k8s 的 api-server,从etcd获取资源信息。
2 调度器和控制器
2.0 参考资料
2.1 kube-scheduler
kube-scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配Node 的 Pod,然后根据调度策略为这些 Pod 分配节点 (更新 Pod 的 NodeName 字段)。调度器需要充分考虑诸多的因素:
- 公平调度
- 资源高效利用
- Qos
- affinity 和 anti-affinity;
- 数据本地化 (data locality);
- 内部负载干扰 (inter-workload interference )
- deadlines
kube-scheduler 调度分为两个阶段,predicate 和 priority:
- predicate:过滤不符合条件的节点
- priority:优先级排序,选择优先级最高的节点
调度器每次只调度一个Pod资源对象,为每一个Pod资源对象寻找合适节点的过程是一个调度周期
kube-scheduler组件的启动流程如图: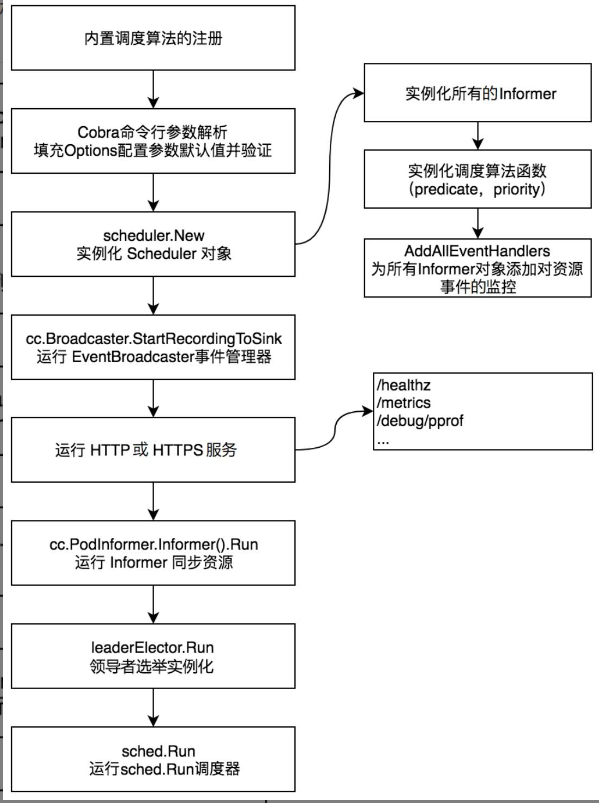
在kube-scheduler组件的启动流程中,代码逻辑可分为8个步骤,分别介绍如下:
- 内置调度算法的注册。
- Cobra命令行参数解析。
- 实例化Scheduler对象。
- 运行EventBroadcaster事件管理器。
- 运行HTTP或HTTPS服务。
- 运行Informer同步资源。
- 领导者选举实例化。
- 运行 sched.Run 调度器
2.1.1 Predicates 策略


Predicates Plugin 的工作原理:
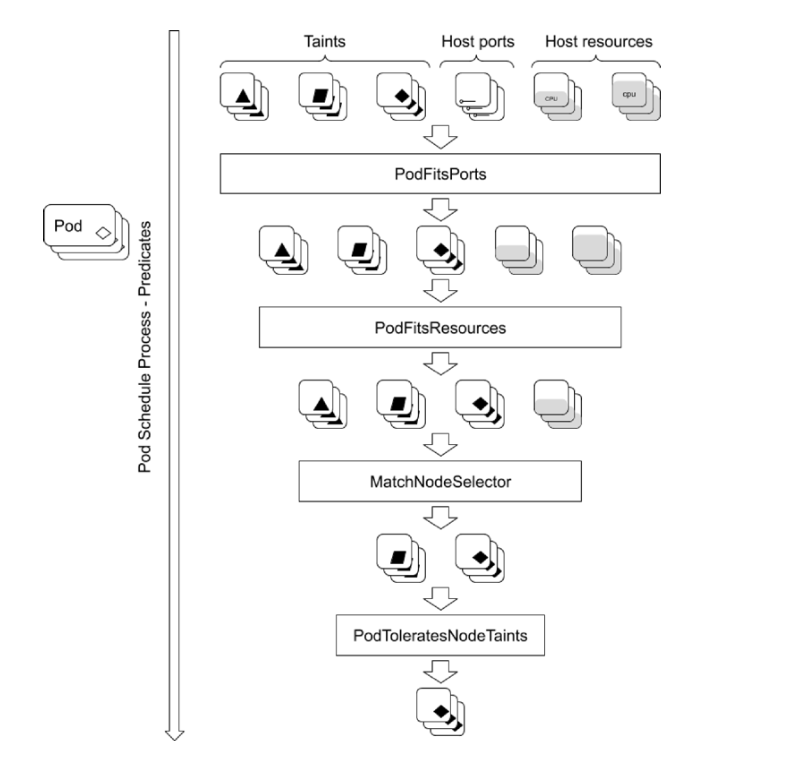
- 刚开始是一个可供选择的Node集合
- 顺序执行所有 Predicates plugin,逐渐过滤掉不满足条件的 Node
- 最后剩下满足条件的Node,再对这些 Node 继续判定
2.1.2 Priorities 策略
Priorities 会采取各种指标,对 Node进行打分并排序,为所有Node排一个优先级,最后把需要调度的Pod与优先级最高的Node进行bind。

- 资源需求
- CPU
- requests:Kubernetes调度Pod时,会判断当前节点正在运行的Pod的CPU Request的总和,再加上当前调度Pod的CPU request,计算其是否超过节点的CPU的可分配资源
- limits:配置cgroups以限制资源上限
- 内存
- requests:判断节点的剩余内存是否满足Pod的内存请求量,以确定是否可以将Pod调度到该节点
- limits:配置 cgroup 以限制资源上限
- 磁盘资源需求
容器临时存储 (ephemeralstorage)包含日志和可写层数据,可以通过定义Pod Spec中的limits.ephemeral-storage和requests.ephemeral-storage来申请。
Pod调度完成后,计算节点对临时存储的限制不是基于CGroup的,而是由kubelet定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对Pod进行驱逐。
- Init Container 的资源需求
当kube-scheduler调度带有多个init容器的Pod时,只计算cpu.request最多的init容器,而不是计算所有的init容器总和。
由于多个init容器按顺序执行,并且执行完成立即退出,所以申请最多的资源init容器中的所需资源即可满足所有init容器需求。
kube-scheduler在计算该节点被占用的资源时,init容器的资源依然会被纳入计算。因为init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起Sandbox重建时。
2.1.3 Pod 调度到指定 Node上
- 可以通过 nodeSelector、nodeAffinity、podAffinity 以及Taints 和 tolerations 等来将 Pod 调度到需要的 Node上。
- 也可以通过设置 nodeName 参数,将 Pod 调度到指定node 节点上。
- 比如,使用 nodeSelector,首先给 Node 加上标签
kubectl label nodes <your-node-name> disktype=ssd - 接着,指定该 Pod 只想运行在带有
disktype=ssd标签的Node 上。
nodeSelector的使用: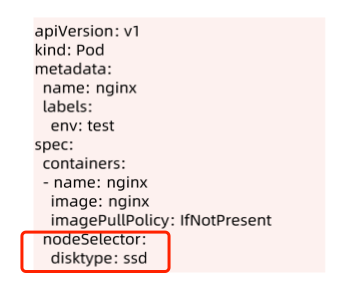
2.1.4 NodeAffinity
反亲和性(Anti-Affinity): 允许将一个业务的Pod资源对象的多副本实例调度到不同的节点上,以实现高可用性。
NodeAffinity 目前支持两种:requiredDuringSchedulinglgnoredDuringExecution 和preferredDuringSchedulinglgnoredDuringExecution,分别代表必须满足条件和优选条件。比如下面的例子代表调度到包含标签 Kubernetes.io/e2e-az-name 并且值为 e2e-az1 或e2e-az2 的Node 上,并且优选还带有标签 another-node-label-key=another-node-label-value 的 Node。
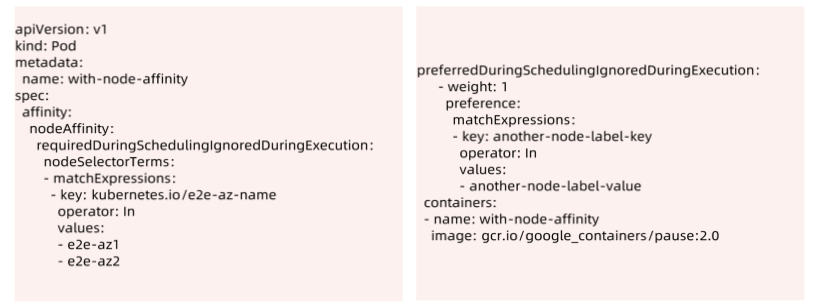
2.1.5 PodeAffinity
podAffinity 基于 Pod 的标签来选择 Node,仅调度到满足条件 Pod 所在的 Node 上,支持podAffinity 和 podAntiAffinity。以下面的例子为例:如果一个“Node 所在 Zone 中包含至少一个带有 security=S1 标签且运行中的 Pod”,那么可以调度到该 Node,不调度到“包含至少一个带有 security=S2 标签且运行中 Pod”的 Node 上。
podAffinity示例:

kube-scheduler调度器自动为Pod资源对象选择全局最优或局部最优节点(即节点的硬件资源足够多、节点负载足够小等)。在生产环境中,一般希望能够更多地干预、控制Pod资源对象的调度策略,例如,将不需要依赖GPU硬件资源的Pod资源对象分配给没有GPU硬件资源的节点,将需要依赖GPU硬件资源的Pod资源对象分配给具有GPU硬件资源的节点,或者如果两个业务联系得很紧密,则可以将它们调度到同一个节点上,以减少因网络传输而带来的性能损耗等问题。
开发者只需要在这些节点上打上相应的标签,然后调度器就可以通过标签进行Pod资源对象的调度了。这种调度策略被称为亲和性和反亲和性调度,分别介绍如下:
- 亲和性(Affinity): 用于多业务就近部署,例如允许将两个业务的Pod资源对象尽可能地调度到同一个节点上。
- 反亲和性(Anti-Affinity): 允许将一个业务的Pod资源对象的多副本实例调度到不同的节点上,以实现高可用性。
2.1.6 Taints 和 Tolerations
Taints 和 Tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 Taint 应用于 Node 上,而Toleration 则应用于 Pod 上。
目前支持的 Taint 类型:
- NoSchedule:新的 Pod 不调度到该 Node 上,不影响正在运行的 Pod;
- PreferNoSchedule:soft 版的 NoSchedule,尽量不调度到该 Node 上
- NoExecute: 新的 Pod 不调度到该 Node上,并且删除 (evict) 已在运行的 Pod。Pod 可以增加一个预留时间 (tolerationSeconds)
然而,当 Pod 的Tolerations 匹配 Node 的所有 Taints 的时候可以调度到该 Node 上;当 Pod 是已经运行的时候,也不会被删除 (evicted)。另外对于 NoExecute,如果 Pod 增加了一个tolerationSeconds,则会在该时间之后才删除 Pod。
多租户 Kubernetes 集群-计算资源隔离方案:
2.1.7 优先级和抢占机制
从 v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。开启方法为:
- apiserver 配置
--feature-gates=PodPriority=true和--runtimeconfig=scheduling.k8s.io/v1alpha1=true - kube-scheduler 配置
--feature-gates=PodPriority=true
PriorityClass:
在指定 Pod 的优先级之前需要先定义一个 PriorityClass (非 namespace 资源),如: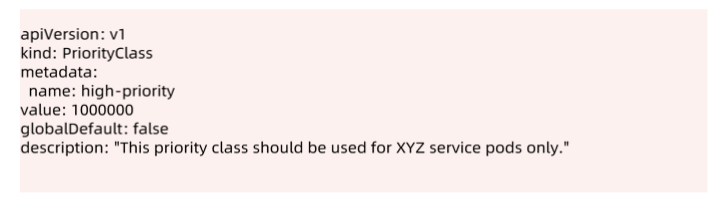
为Pod设置priority:
Pod资源对象支持优先级(Priority)与抢占(Preempt)机制。当kube-scheduler调度器运行时,根据Pod资源对象的优先级进行调度,高优先级的Pod资源对象排在调度队列(SchedulingQueue)的前面,优先获得合适的节点(Node),然后为低优先级的Pod资源对象选择合适的节点。
当高优先级的Pod资源对象没有找到合适的节点时,调度器会尝试抢占低优先级的Pod资源对象的节点,抢占过程是将低优先级的Pod资源对象从所在的节点上驱逐走,使高优先级的Pod资源对象运行在该节点上,被驱逐走的低优先级的Pod资源对象会重新进入调度队列并等待再次选择合适的节点。
2.1.8 内置调度算法
kube-scheduler调度器默认提供了两类调度算法,分别是预选调度算法和优选调度算法,分别介绍如下。
- 预选调度算法: 检查节点是否符合运行“待调度Pod资源对象”的条件,如果符合条件,则将其加入可用节点列表。
- 优选调度算法: 为每一个可用节点计算出一个最终分数,kube-scheduler调度器会将分数最高的节点作为最优运行“待调度Pod资源对象”的节点。
2.1.9 多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过 podSpec,schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。
一些生产的经验:

调度器可以说是运营过程中稳定性最好的组件之一,基本没有太大的维护 effort。
2.2 Controller Manager
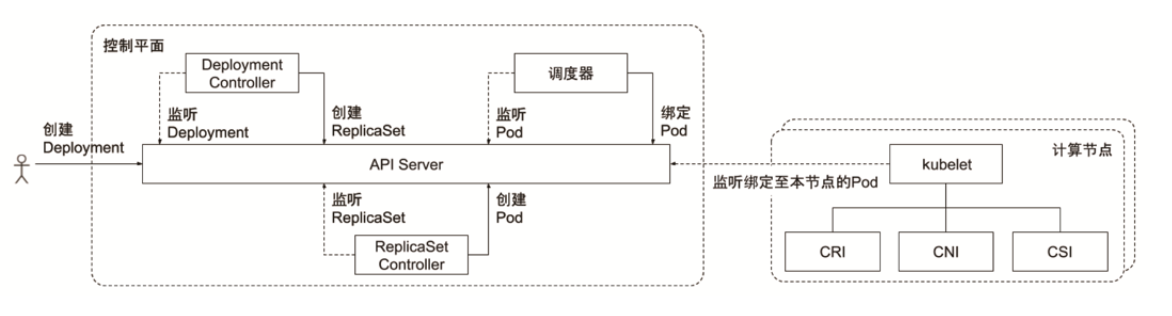
Controller Manager(管理控制器)负责管理Kubernetes集群中的节点(Node)、Pod副本、服务、端点(Endpoint)、命名空间(Namespace)、服务账户(ServiceAccount)、资源定额(ResourceQuota)等。例如,当某个节点意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
Controller Manager负责确保Kubernetes系统的实际状态收敛到所需状态,其默认提供了一些控制器(Controller),例如DeploymentControllers控制器、StatefulSet控制器、Namespace控制器及PersistentVolume控制器等,每个控制器通过kube-apiserver组件提供的接口实时监控整个集群每个资源对象的当前状态,当因发生各种故障而导致系统状态出现变化时,会尝试将系统状态修复到“期望状态”。
Controller Manager具备高可用性(即多实例同时运行),即基于Etcd集群上的分布式锁实现领导者选举机制,多实例同时运行,通过kube-apiserver提供的资源锁进行选举竞争。抢先获取锁的实例被称为Leader节点(即领导者节点),并运行kube-controller-manager组件的主逻辑;而未获取锁的实例被称为Candidate节点(即候选节点),运行时处于阻塞状态。在Leader节点因某些原因退出后,Candidate节点则通过领导者选举机制参与竞选,成为Leader节点后接替kube-controller-manager的工作。
2.2.1 控制器的工作流程
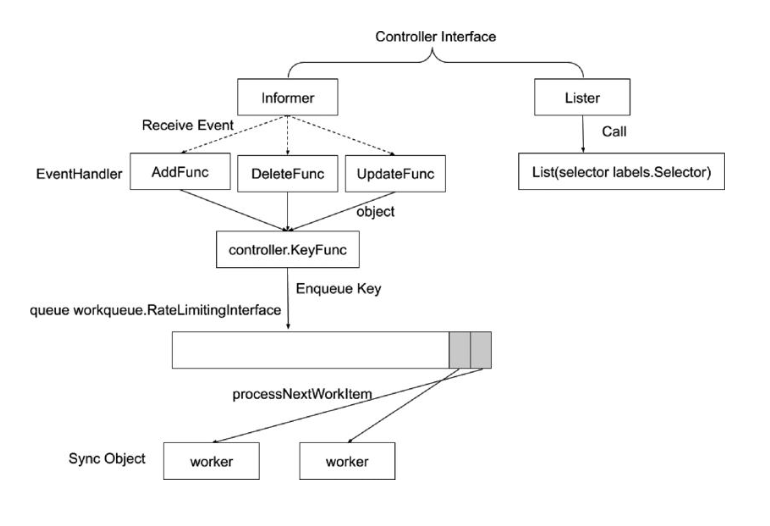
Informer 的内部机制:
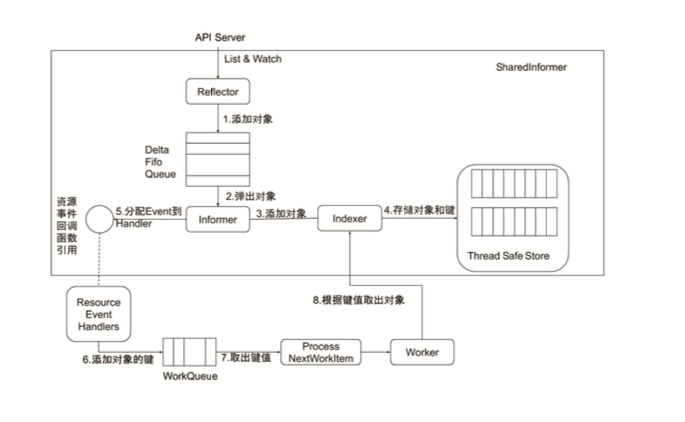
控制器的协同工作原理:
Controller-Manager 启动参数:
1 | ks exec -it kube-controller-manager-cadmin -- kube-controller-manager -h |
1 | Nodelifecycle controller flags: |
2.2.2 通用 Controller
- Job Controller:处理Job
- Pod AutoScaler:处理 Pod 的自动缩容/扩容
- RelicaSet:依据Replicaset Spec 创建Pod。
- Service Controller:为LoadBalancer type 的 service 创建 LB VIP
- ServiceAccount Controller:确保 serviceaccount 在当前 namespace 存在
- StatefulSet Controller:处理 statefulset 中的 pod
- Volume Controller:依据PV spec 创建 volume
- Resource quota Controller:在用户使用资源之后,更新状态
- Namespace Controller:保证 namespace 删除时,该namespace下的所有资源都先被删除
- Replication Controller:创建 RC 后, 负责创建 POD
- Node Controller:维护 node 状态,处理 evict 请求
- Daemon Controller:依据 damonset 创建 pod
- Deployment Controller:依据 deployment spec 创建 replicaset
- Endpoint Controller:依据 service spec 创建 endpoint,依据podip 更新 endpoint
- Garbage Controller:处理级联删除,比如 删除 deployment 的 同时 删除 replicaset 以及 pod
- CronJob Controller:处理 cronjob
2.2.3 Scheduler 和 Controller 高可用
在 kubernetes 中可以配置多个 Scheduler 和 Controller 保证高可用,但需要一个创建Pod的请求只能被一个Scheduler执行。所以需要增加一个 Leader Election(锁机制),只有竞争得到 ”锁“ 的Scheduler 才能执行。
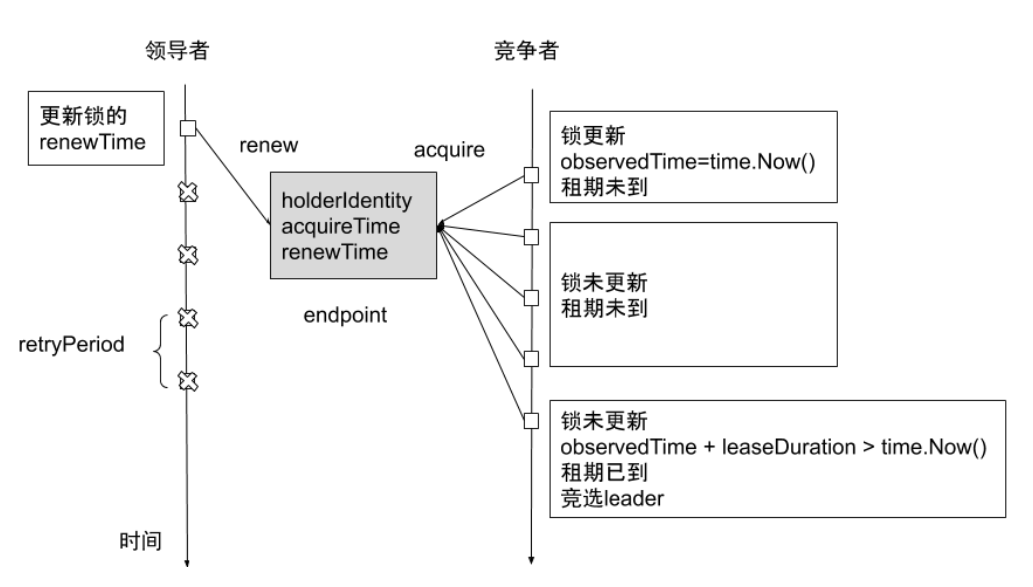
Leader Election:
Kubenetes 提供基于 configmap 和 endpoint 的 leader election 类库
Kubernetes 采用leader election 模式启动 component 后,会创建对应 endpoint,并把当前的leader 信息 annotate 到 endponit。
Endpoint 如下: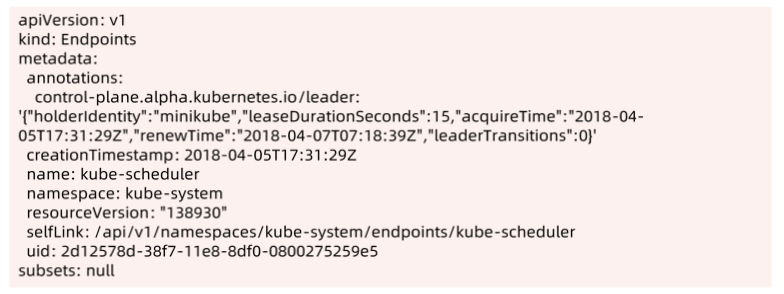
- holderIdentity:目前在执行的 Scheduler,其他Scheduler会持续查看这个值,如果为空,则把自己的名字写入,就得到了锁
- leaseDurationSeconds:保存时间 15s
- acquireTime:当前 Scheduler获取锁的时间。
- renewTime:竞争得到锁的Scheduler会时刻更新这个时间值,其他Scheduler会时刻检查 leaseDurationSeconds+acquireTime与 renewTime
- leaderTransitions:第几轮
3 Kubelet
3.1 kubelet 架构
3.1.1 kubelet 组件图
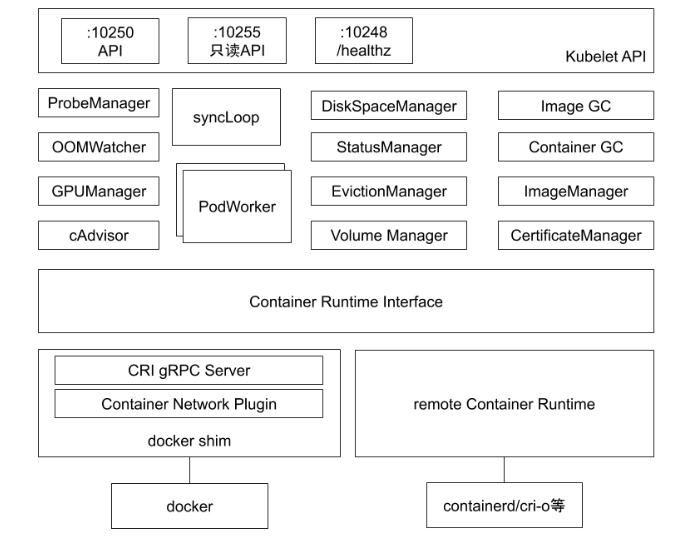
Kubelet实现了三种开放接口: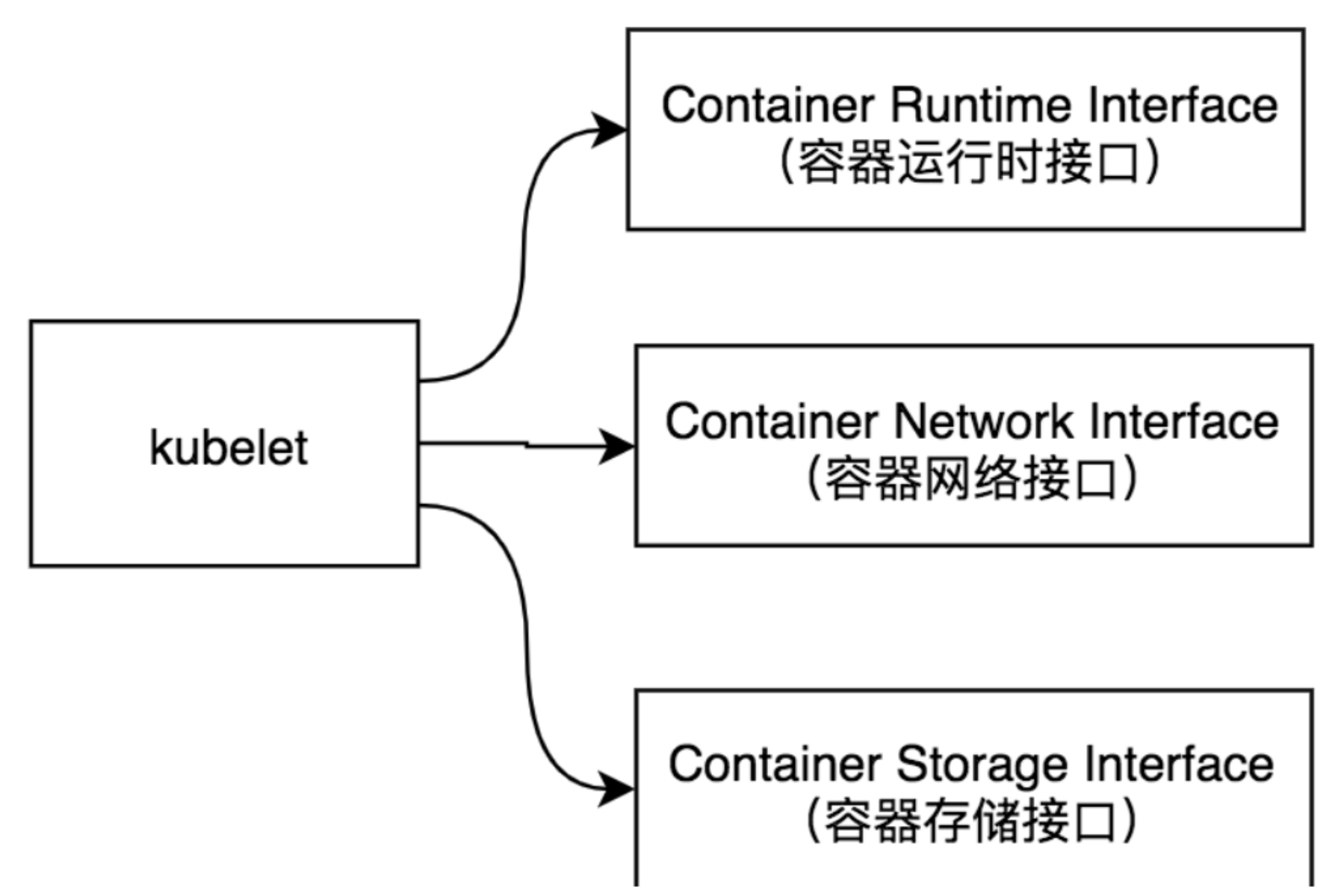
- Container Runtime Interface :简称CRI(容器运行时接口),提供容器运行时通用插件接口服务。CRI定义了容器和镜像服务的接口。CRI将kubelet组件与容器运行时进行解耦,将原来完全面向Pod级别的内部接口拆分成面向Sandbox和Container的gRPC接口,并将镜像管理和容器管理分离给不同的服务。
- Container Network Interface :简称CNI(容器网络接口),提供网络通用插件接口服务。CNI定义了Kubernetes网络插件的基础,容器创建时通过CNI插件配置网络。
- Container Storage Interface :简称CSI(容器存储接口),提供存储通用插件接口服务。CSI定义了容器存储卷标准规范,容器创建时通过CSI插件配置存储卷。
3.1.2 kubelet 管理 Pod 的核心流程
kubelet组件,用于管理节点,运行在每个Kubernetes节点上。kubelet组件用来接收、处理、上报kube-apiserver组件下发的任务。kubelet进程启动时会向kube-apiserver注册节点自身信息。它主要负责所在节点(Node)上的Pod资源对象的管理,例如Pod资源对象的创建、修改、监控、删除、驱逐及Pod生命周期管理等。
kubelet组件会定期监控所在节点的资源使用状态并上报给kube-apiserver组件,这些资源数据可以帮助kube-scheduler调度器为Pod资源对象预选节点。kubelet也会对所在节点的镜像和容器做清理工作,保证节点上的镜像不会占满磁盘空间、删除的容器释放相关资源。
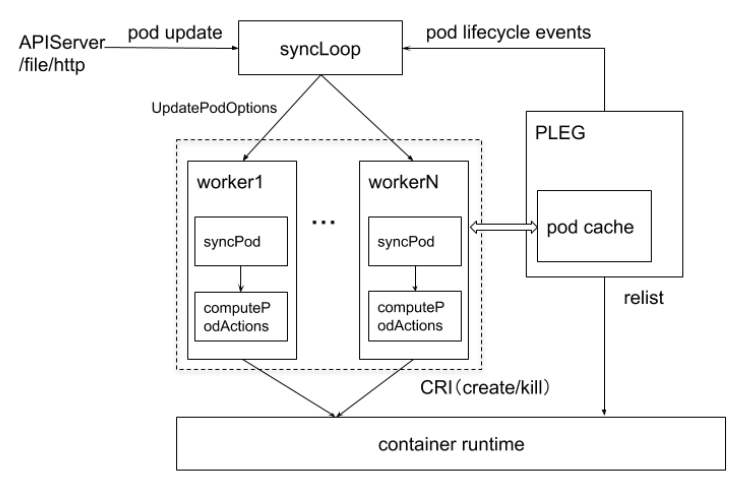
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口。
- 接收并执行 master 发来的指令;
- 管理 Pod 及 Pod 中的容器;
- 每个 kubelet 进程会在 APIServer 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源。
3.2 节点管理
节点管理主要是节点自注册和节点状态更新:
Kubelet 可以通过设置启动参数 –register-node 来确定是否向 API Server 注册自己;如果 Kubelet 没有选择自注册模式,则需要用户自己配置 Node 资源信息,同时需要告知Kubelet 集群上的 API Server 的位置;
Kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server 发送节点新消息,APIServer 在接收到新消息后,将信息写入 etcd。
3.3 Pod 管理
获取 Pod 清单:
- 文件:启动参数 –config 指定的配置目录下的文件(默认 /etc/Kubernetes/manifests/)。该文件每20秒重新检查一次 (可配置)。
- HTTP endpoint (URL) :启动参数–manifest-url 设置。每 20 秒检查一次这个端点 (可配置)。
- API Server: 通过 API Server 监听 etcd 目录,同步 Pod 清单。
- HTTP server: kubelet 侦听 HTTP 请求,并响应简单的 API 以提交新的 Pod 清单
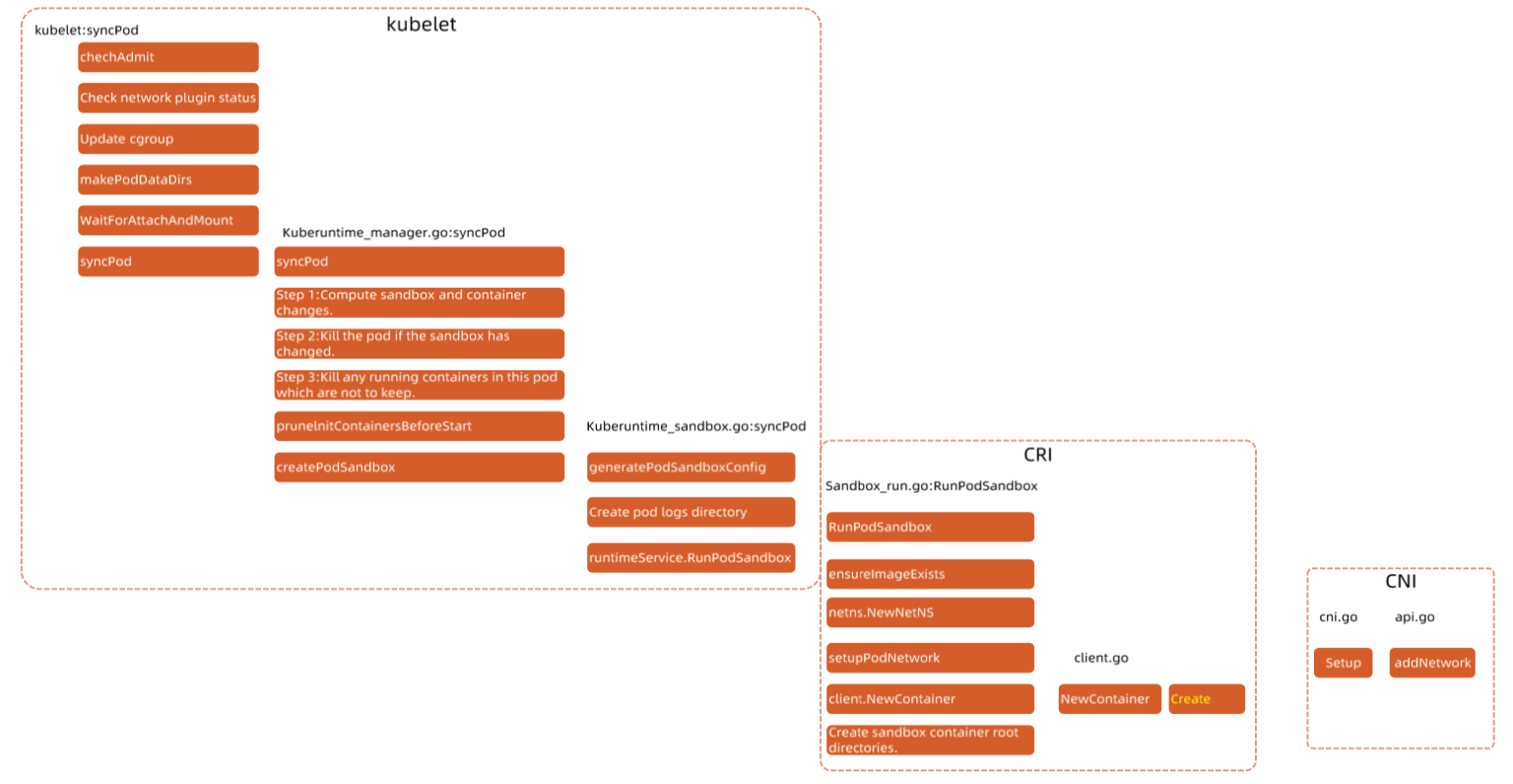
3.4 Pod 启动流程
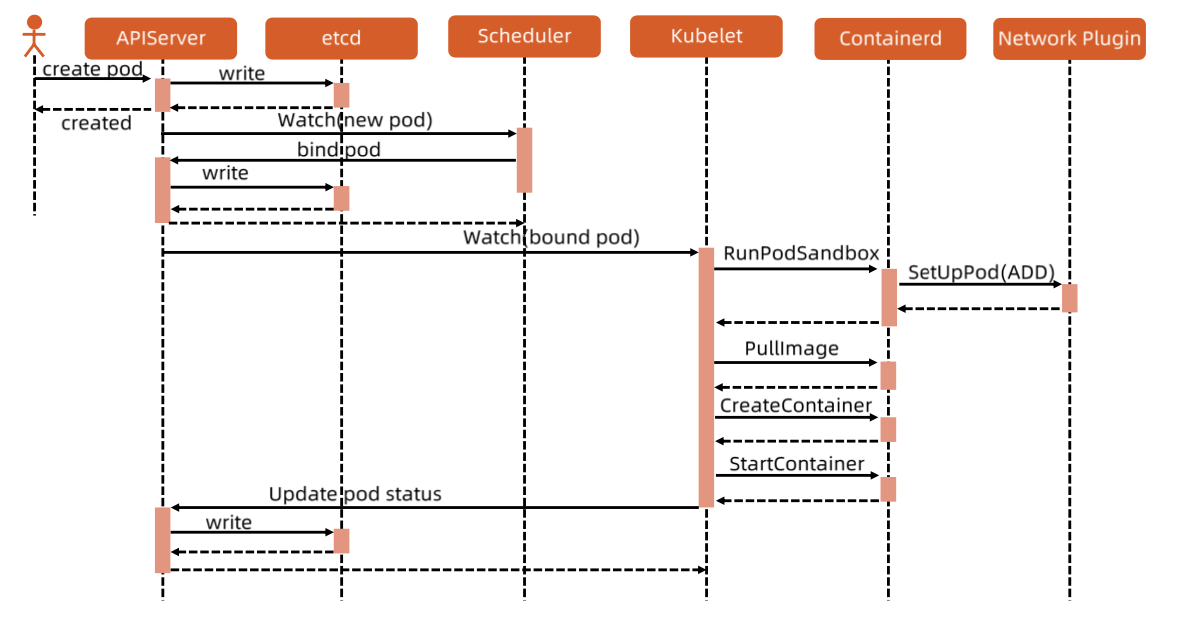
- 客户端 执行 kubectl 命令 创建 Pod
- APIServer 接收到请求,把配置写入etcd,则会返回给客户端,下边 kubernetes 内部开始执行创建流程,客户端可以查看 Pod 状态
- Scheduler 监听到 新的 Pod创建信息,开始执行 predicate 和 priority 策略,最终把 pod 和 node 进行 bind,并返回信息,apiserver把信息存入 etcd
- kubelet 监听到一个 bound pod 信息,需要在本node上创建pod,开始调用 containerd 的接口创建容器
- kubelet 调用 RunPodSanbox 创建一个 基础pause容器,pause容器没有业务流程,不占用 cpu 和内存,会配置基础网络环境(放到这里是保证,即使Pod中运行的业务功能出问题也不会导致基础环境不可用)
- kubelet 执行 pullimage、createContainer、StartContainer 等流程,开始创建业务容器和InitContainer
- kubelet 返回Pod 的信息,apiserver 写入etcd
通过 docker ps 命令查看容器,可以看到每一个 Pod 都有一个 pause 的容器
1 | 93b97bbb8750 /library/cke/kubernetes/pause:3.1 "/pause" 2 weeks ago Up 2 weeks |
流程图:
3.5 kube-proxy
kube-proxy组件,作为节点上的网络代理,运行在每个Kubernetes节点上。它监控kube-apiserver的服务和端点资源变化,并通过iptables/ipvs等配置负载均衡器,为一组Pod提供统一的TCP/UDP流量转发和负载均衡功能。
4 CRI
4.1 简介
容器运行时 (Container Runtime),运行于 Kubernetes (k8s) 集群的每个节点中,负责容器的整个生命周期。其中 Docker 是目前应用最广的。随着容器云的发展,越来越多的容器运行时涌现。为了解决这些容器运行时和 Kubernetes 的集成问题,在 Kubernetes 1.5版本中,社区推出了 CRI(Container Runtime Interface,容器运行时接口) 以支持更多的容器运行时。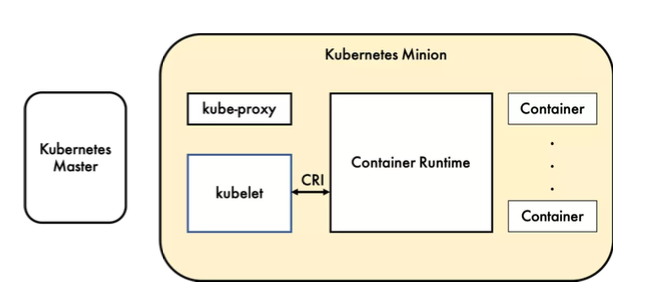
CRI是 Kubernetes 定义的一组 gRPC 服务。kubelet作为客户端,基于 gRPC 框架,通过 Socket和容器运行时通信。它包括两类服务: 镜像服务 (Image Service)和运行时服务 (Runtime Service),镜像服务 提供下载、检查和删除镜像的远程程序调用。 运行时服务 包含用于管理容器生命周期,以及与容器交互的调用 (exec / attach / port-forward)的远程程序调用。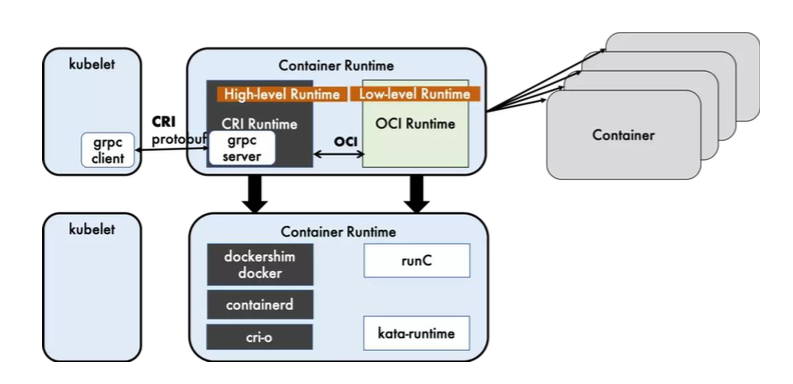
4.2 运行时层级
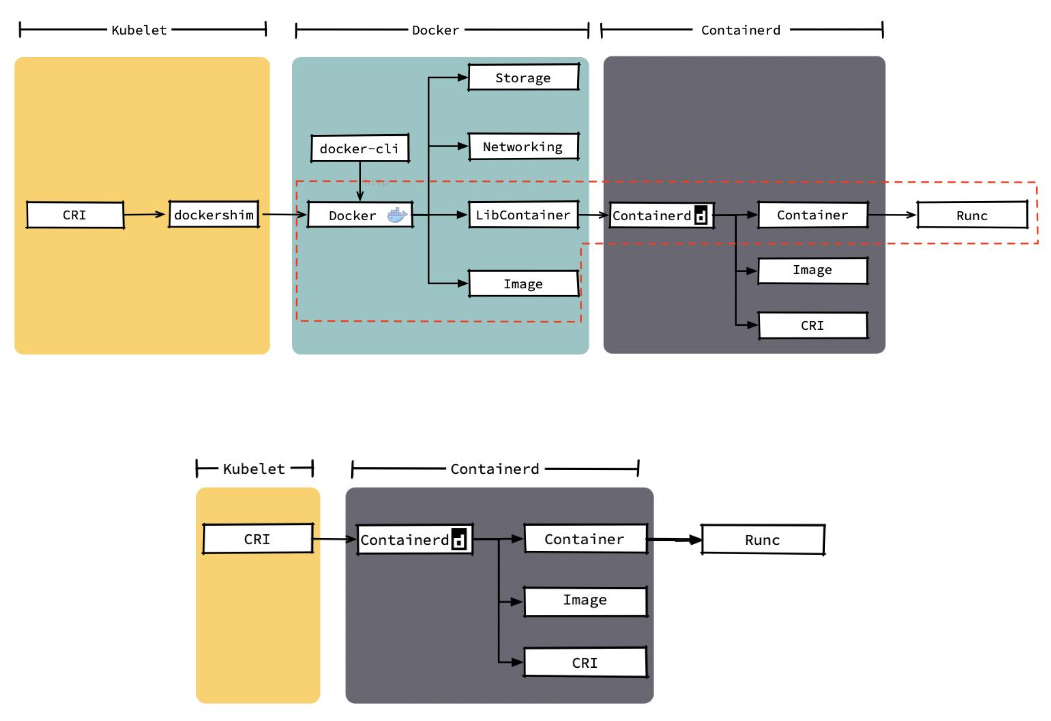
Dockershim,containerd 和 CRI- 都是遵循 CRI 的容器运行时,我们称他们为 高层级运行时( High-level Runtime )。
OCI (Open Container Initiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准包括 镜像规范 (Image Specification)和运行时规范(Runtime Specification)。镜像规范定义了 OCI 镜像的标准。高层级运行时将会下载一个 OCI 镜像,并把它解压成 OCI 运行时文件系统包 (filesystem bundle)。
运行时规范则描述了如何从 OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期。如何为新容器设置 命名空间 (namepsaces)和 控制组 (cgroups) ,以及挂载根文件系统等等操作,都是在这里定义的。它的一个参考实现是 runC 。我们称其为 低层级运行时 (Low-level Runtime) 。除 runC 以外,也有很多其他的运行时遵循 OCI 标准,例如 kata-runtime。
容器运行时是真正起删除和管理容器的组件。容器运行时可以分为高层和低层的运行时。高层运行时主要包括 Docke,containerd 和 CRI-0,低层的运行时,包含了 runc,kata,以及 qVisor。低层运行时 kata 和 gVisor 都还处于小规模落地或者实验阶段,其生态成熟度和使用案例都比较欠缺,所以除非有特殊的需求,否则 runc 几乎是必然的选择。因此在对容器运行时的选择上,主要是聚焦于上层运行时的选择。
Docker 内部关于容器运行时功能的核心组件是 containerd,后来 containerd 也可直接和 kubelet 通过 CRI 对接独立在 Kubemnetes 中使用。相对于 Docker 而言,containerd 减少了 Docker 所需的处理模块 Dockerd 和Docker-shim,并对 Docker 支持的存储驱动进行了优化,因此在容器的创建启动停止和删除,以及对镜像的拉取上,都具有性能上的优势。架构的简化同时也带来了维护的便利。当然 Docker 也具有很多 containerd 不具有的功能,例如支持 zfs 存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过 xfs_quota 来对容器的可写层进行大小限制等。尽管如此,containerd 目前也其本上能够满足容哭的众多管理需求所以将它作为运行时的也越来越多。
kubelet 和运行时的关系: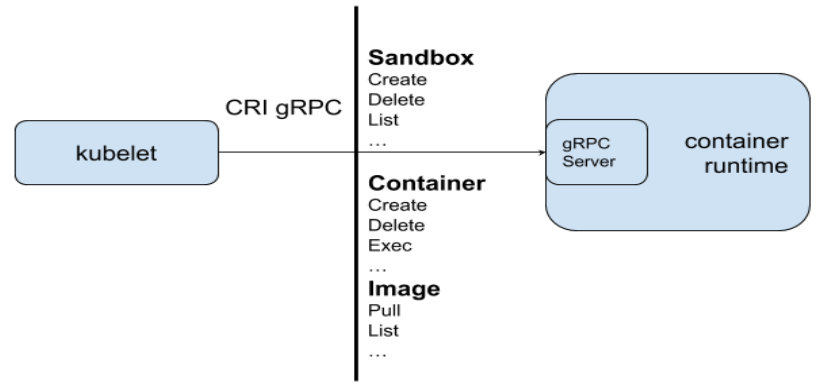
运行时相关接口: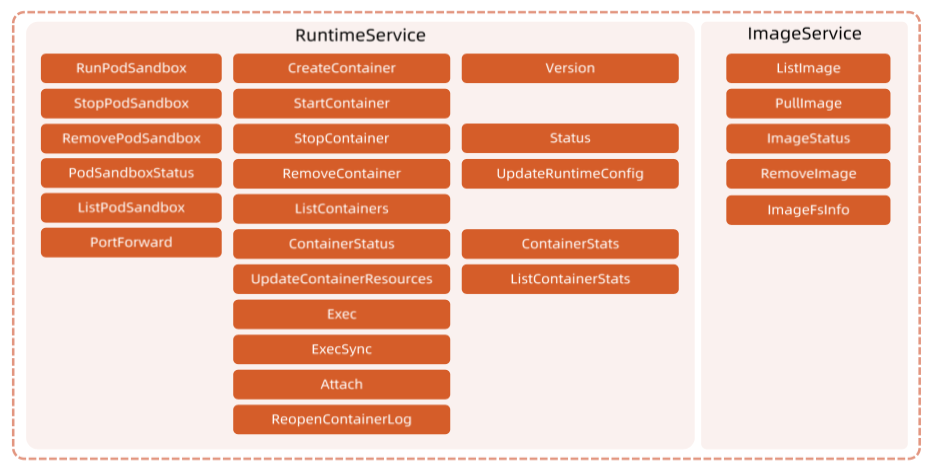
以上 PodSandbox,对应的并不是 Kubernetes 里的 Pod API 对象,而只是抽取了 Pod 里的一部分与容器运行时相关的字段,比如 HostName、DnsConfig、CgroupParent 等。所以说,PodSandbox 这个接口描述的,其实是 Kubernetes 将 Pod 这个概念映射到容器运行时层面所需要的字段,或者说是一个 Pod 对象子集。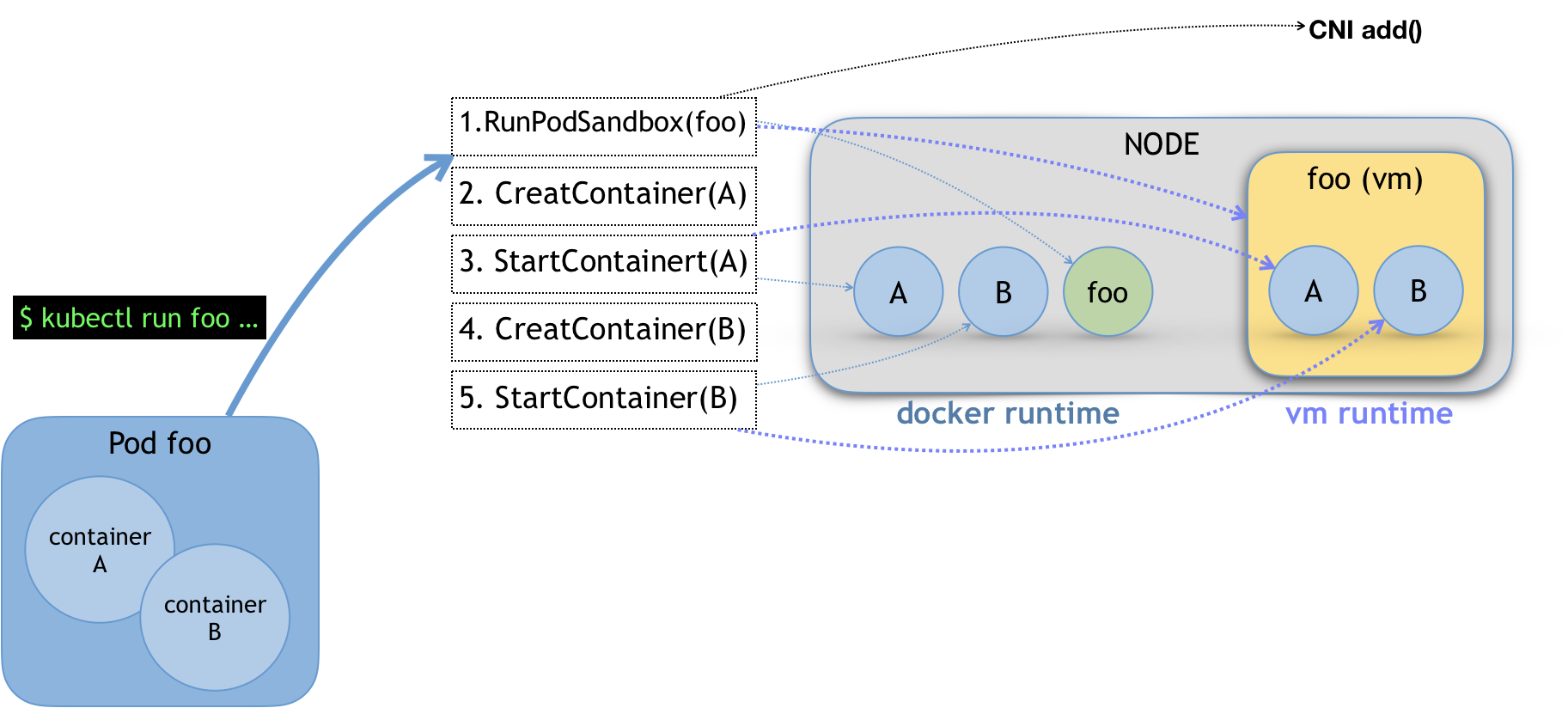
比如,当我们执行 kubectl run 创建了一个名叫 foo 的、包括了 A、B 两个容器的 Pod 之后。这个 Pod 的信息最后来到 kubelet,kubelet 就会按照图中所示的顺序来调用 CRI 接口。
在具体的 CRI shim 中,这些接口的实现是可以完全不同的。比如,如果是 Docker 项目,dockershim 就会创建出一个名叫 foo 的 Infra 容器(pause 容器),用来“hold”住整个 Pod 的 Network Namespace。
而如果是基于虚拟化技术的容器,比如 Kata Containers 项目,它的 CRI 实现就会直接创建出一个轻量级虚拟机来充当 Pod。
在 RunPodSandbox 这个接口的实现中,你还需要调用 networkPlugin.SetUpPod(…) 来为这个 Sandbox 设置网络。这个 SetUpPod(…) 方法,实际上就在执行 CNI 插件里的 add(…) 方法,也就是我在前面为你讲解过的 CNI 插件为 Pod 创建网络,并且把 Infra 容器加入到网络中的操作。
接下来,kubelet 继续调用 CreateContainer 和 StartContainer 接口来创建和启动容器 A、B。对应到 dockershim 里,就是直接启动 A,B 两个 Docker 容器。所以最后,宿主机上会出现三个 Docker 容器组成这一个 Pod。
而如果是 Kata Containers 的话,CreateContainer 和 StartContainer 接口的实现,就只会在前面创建的轻量级虚拟机里创建两个 A、B 容器对应的 Mount Namespace。所以,最后在宿主机上,只会有一个叫作 foo 的轻量级虚拟机在运行。
开源运行时的比较:
Docker 的多层封装和调用,导致其在可维护性上略逊一筹,增加了线上问题的定位难度;几乎除了重启 Docker,就毫无他法了。
containerd 和 CRI-O 的方案比起 Docker 简洁很多,kubelet可以直接调用containerd的接口。
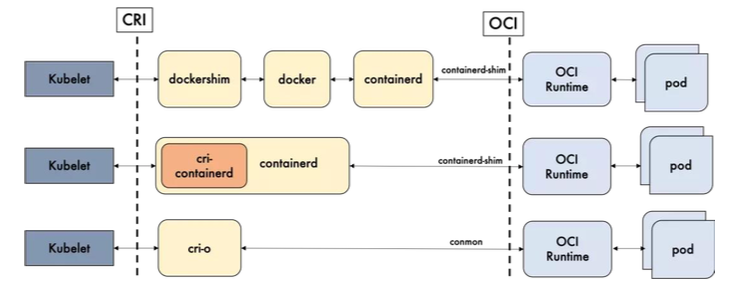
Docker 和 containerd 的差异细节:
4.3 Streaming API
CRI shim 还有一个重要的工作,就是如何实现 exec、logs 等接口。这些接口跟前面的操作有一个很大的不同,就是这些 gRPC 接口调用期间,kubelet 需要跟容器项目维护一个长连接来传输数据。这种 API,我们就称之为 Streaming API。
CRI shim 里对 Streaming API 的实现,依赖于一套独立的 Streaming Server 机制。这一部分原理,可以用如下所示的示意图来为你描述。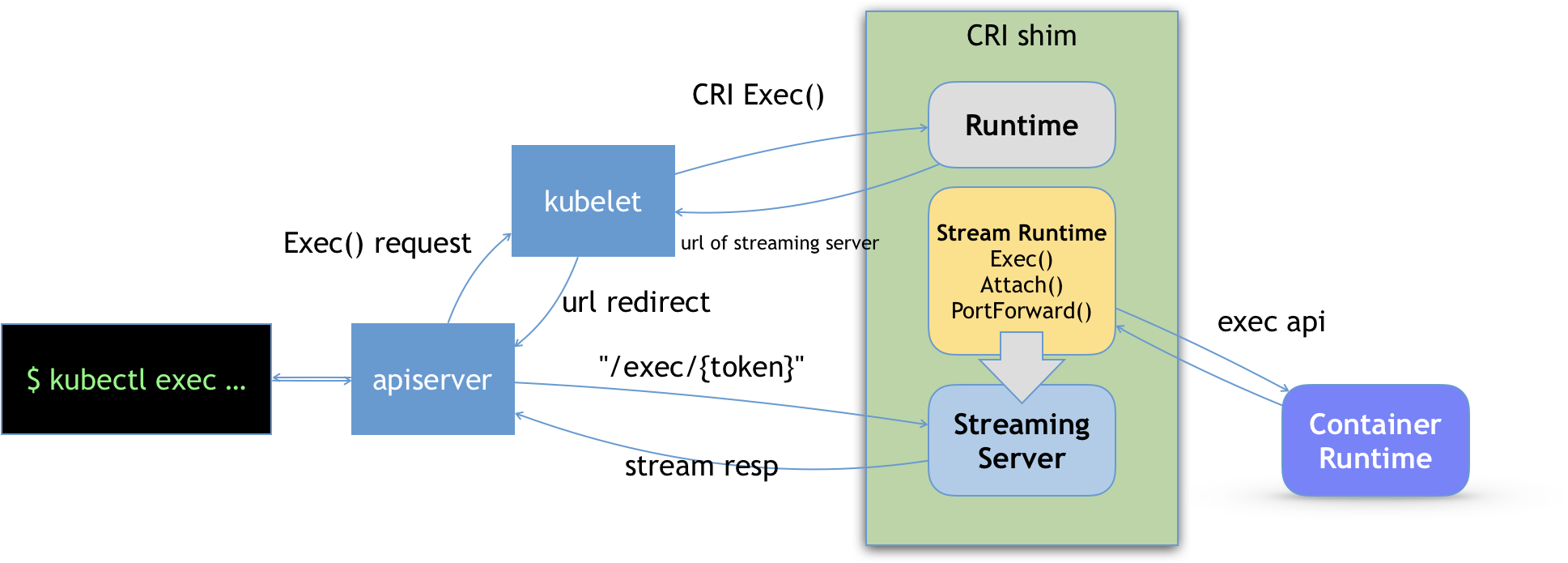
当我们对一个容器执行 kubectl exec 命令的时候,这个请求首先交给 API Server,然后 API Server 就会调用 kubelet 的 Exec API。
这时,kubelet 就会调用 CRI 的 Exec 接口,而负责响应这个接口的,自然就是具体的 CRI shim。
但在这一步,CRI shim 并不会直接去调用后端的容器项目(比如 Docker )来进行处理,而只会返回一个 URL 给 kubelet。这个 URL,就是该 CRI shim 对应的 Streaming Server 的地址和端口。
而 kubelet 在拿到这个 URL 之后,就会把它以 Redirect 的方式返回给 API Server。所以这时候,API Server 就会通过重定向来向 Streaming Server 发起真正的 /exec 请求,与它建立长连接。
当然,这个 Streaming Server 本身,是需要通过使用 SIG-Node 为你维护的 Streaming API 库来实现的。并且,Streaming Server 会在 CRI shim 启动时就一起启动。此外,Stream Server 这一部分具体怎么实现,完全可以由 CRI shim 的维护者自行决定。比如,对于 Docker 项目来说,dockershim 就是直接调用 Docker 的 Exec API 来作为实现的。
4.4 Kata Containers 与 gVisor
无论是 Kata Containers,还是 gVisor,它们实现安全容器的方法其实是殊途同归的。这两种容器实现的本质,都是给进程分配了一个独立的操作系统内核,从而避免了让容器共享宿主机的内核。这样,容器进程能够看到的攻击面,就从整个宿主机内核变成了一个极小的、独立的、以容器为单位的内核,从而有效解决了容器进程发生“逃逸”或者夺取整个宿主机的控制权的问题。这个原理,可以用如下所示的示意图来表示清楚。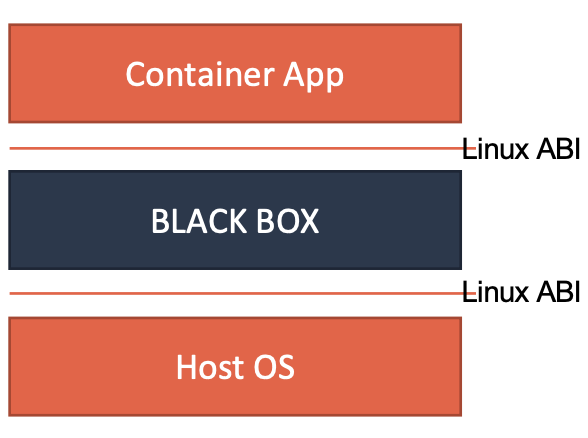
而它们的区别在于,Kata Containers 使用的是传统的虚拟化技术,通过虚拟硬件模拟出了一台“小虚拟机”,然后在这个小虚拟机里安装了一个裁剪后的 Linux 内核来实现强隔离。
而 gVisor 的做法则更加激进,Google 的工程师直接用 Go 语言“模拟”出了一个运行在用户态的操作系统内核,然后通过这个模拟的内核来代替容器进程向宿主机发起有限的、可控的系统调用。
4.4.1 KataContainers
Kata Containers 的本质,就是一个轻量化虚拟机。所以当你启动一个 Kata Containers 之后,你其实就会看到一个正常的虚拟机在运行。这也就意味着,一个标准的虚拟机管理程序(Virtual Machine Manager, VMM)是运行 Kata Containers 必备的一个组件。在我们上面图中,使用的 VMM 就是 Qemu。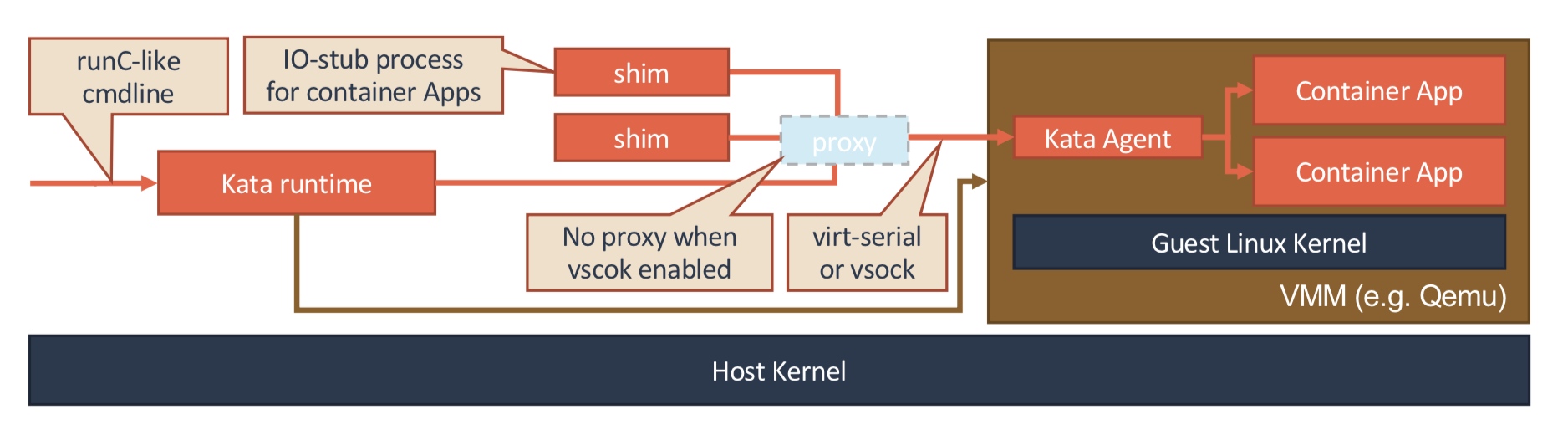
而使用了虚拟机作为进程的隔离环境之后,Kata Containers 原生就带有了 Pod 的概念。即:这个 Kata Containers 启动的虚拟机,就是一个 Pod;而用户定义的容器,就是运行在这个轻量级虚拟机里的进程。在具体实现上,Kata Containers 的虚拟机里会有一个特殊的 Init 进程负责管理虚拟机里面的用户容器,并且只为这些容器开启 Mount Namespace。所以,这些用户容器之间,原生就是共享 Network 以及其他 Namespace 的。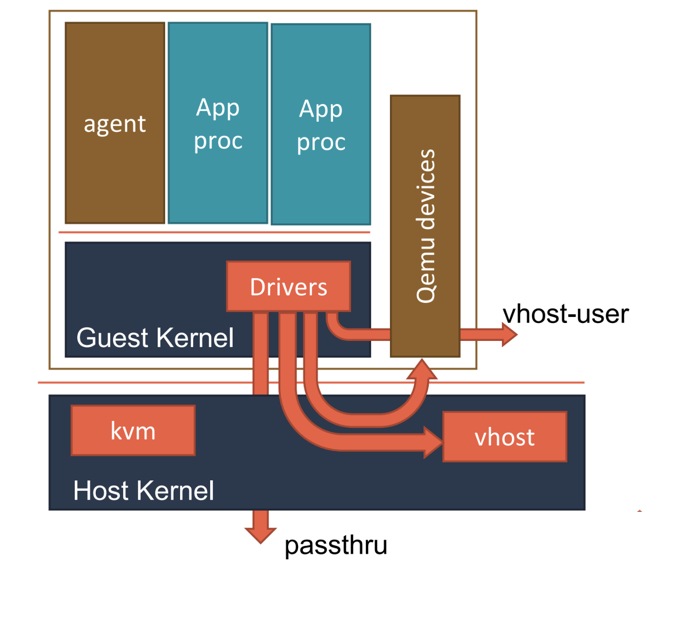
可以看到,当 Kata Containers 运行起来之后,虚拟机里的用户进程(容器),实际上只能看到虚拟机里的、被裁减过的 Guest Kernel,以及通过 Hypervisor 虚拟出来的硬件设备。
而为了能够对这个虚拟机的 I/O 性能进行优化,Kata Containers 也会通过 vhost 技术(比如:vhost-user)来实现 Guest 与 Host 之间的高效的网络通信,并且使用 PCI Passthrough (PCI 穿透)技术来让 Guest 里的进程直接访问到宿主机上的物理设备。这些架构设计与实现,其实跟常规虚拟机的优化手段是基本一致的。
4.4.2 gVisor
gVisor 的设计其实要更加“激进”一些。它的原理,可以用如下所示的示意图来表示清楚。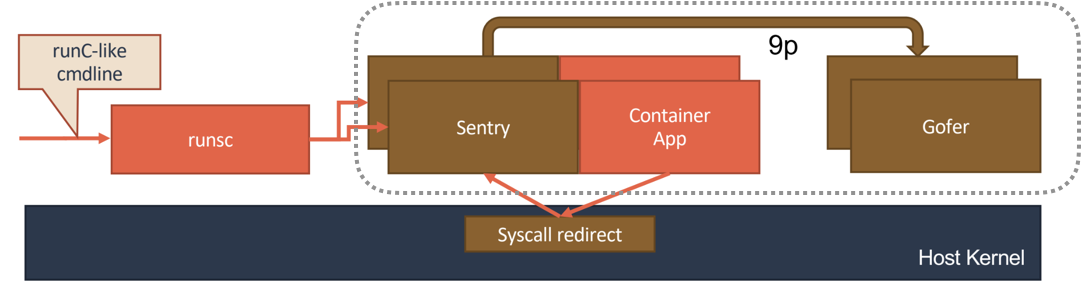
gVisor 工作的核心,在于它为应用进程、也就是用户容器,启动了一个名叫 Sentry 的进程。 而 Sentry 进程的主要职责,就是提供一个传统的操作系统内核的能力,即:运行用户程序,执行系统调用。所以说,Sentry 并不是使用 Go 语言重新实现了一个完整的 Linux 内核,而只是一个对应用进程“冒充”内核的系统组件。
Sentry 对于 Volume 的操作,则需要通过 9p 协议交给一个叫做 Gofer 的代理进程来完成。Gofer 会代替应用进程直接操作宿主机上的文件,并依靠 seccomp 机制将自己的能力限制在最小集,从而防止恶意应用进程通过 Gofer 来从容器中“逃逸”出去。
而在具体的实现上,gVisor 的 Sentry 进程,其实还分为两种不同的实现方式。这里的工作原理,可以用下面的示意图来描述清楚。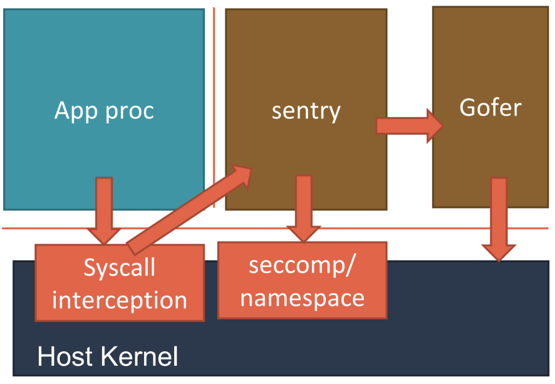
第一种实现方式,是使用 Ptrace 机制来拦截用户应用的系统调用(System Call),然后把这些系统调用交给 Sentry 来进行处理。
这个过程,对于应用进程来说,是完全透明的。而 Sentry 接下来,则会扮演操作系统的角色,在用户态执行用户程序,然后仅在需要的时候,才向宿主机发起 Sentry 自己所需要执行的系统调用。这,就是 gVisor 对用户应用进程进行强隔离的主要手段。不过, Ptrace 进行系统调用拦截的性能实在是太差,仅能供 Demo 时使用。
而第二种实现方式,则更加具有普适性。它的工作原理如下图所示。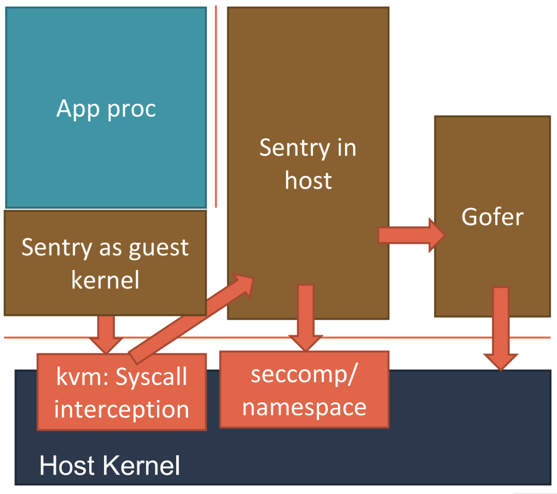
Sentry 会使用 KVM 来进行系统调用的拦截,这个性能比 Ptrace 就要好很多了。
当然,为了能够做到这一点,Sentry 进程就必须扮演一个 Guest Kernel 的角色,负责执行用户程序,发起系统调用。而这些系统调用被 KVM 拦截下来,还是继续交给 Sentry 进行处理。只不过在这时候,Sentry 就切换成了一个普通的宿主机进程的角色,来向宿主机发起它所需要的系统调用。
可以看到,在这种实现里,Sentry 并不会真的像虚拟机那样去虚拟出硬件设备、安装 Guest 操作系统。它只是借助 KVM 进行系统调用的拦截,以及处理地址空间切换等细节。
安全容器的意义,绝不仅仅止于安全。你可以想象一下这样一个场景:比如,你的宿主机的 Linux 内核版本是 3.6,但是应用却必须要求 Linux 内核版本是 4.0。这时候,你就可以把这个应用运行在一个 KataContainers 里。
5 CNI
5.1 简介
Kubernetes 网络模型设计的基础原则是:
- 所有的 Pod 能够不通过 NAT 就能相互访问。
- 所有的节点能够不通过 NAT 就能相互访问。
- 容器内看见的 IP 地址和外部组件看到的容器 IP 是一样的
Kubernetes 的集群里,IP 地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的IP 地址。一个Pod内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的IP 地址、网络设备、配置等都是共享的。也就是说,Pod 里面的所有容器能通过 localhost:port 来连接对方。在Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI (Container NetworkInterface),专门用于设置和删除容器的网络连通性。容器运行时通过 CNI调用网络插件来完成容器的网络设置。
5.2 CNI 插件简介
5.2.1 常见插件和分类
IPAM:IP 地址分配
主插件:网卡设置
- bridge: 创建一个网桥,并把主机端口和容器端口插入网桥。
- ipvlan: 为容器添加ipvlan网口
- loopback: 设置loopback网口
Meta:附加功能
- portmap: 设置主机端口和容器端口映射
- bandwidth: 利用Linux Traffic Control限流
- firewall: 通过iptables或firewalld为容器设置防火墙规则
参考资料:https://github.com/containernetworking/plugins
5.2.2 CNI 插件运行机制
容器运行时在启动时会从 CNI 的配置目录中读取JSON 格式的配置文件,文件后缀为”.conf”,“conflist”,“json”。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。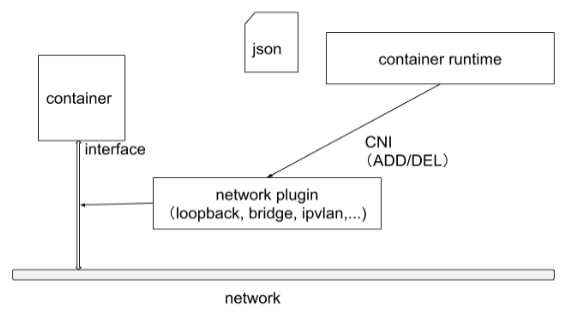
关于容器网络管理,容器运行时一般需要配置两个参数 –cni-bin-dir 和 –cni-conf-dir。有一种特殊情况,kubelet 内置的 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处:
- cni-bin-dir:网络插件的可执行文件所在目录。默认是 /opt/cni/bin
- cni-conf-dir:网络插件的配置文件所在目录。默认是 /etc/cni/net.d

在部署 Kubernetes 的时候,有一个步骤是安装 kubernetes-cni 包,它的目的就是在宿主机上安装CNI 插件所需的基础可执行文件,下边以flannel为例。可以在宿主机的 /opt/cni/bin 目录下看到它们,如下所示:
1 | $ ls -al /opt/cni/bin/ |
这些 CNI 的基础可执行文件,按照功能可以分为三类:
第一类,叫作 Main 插件,它是用来创建具体网络设备的二进制文件。比如,bridge(网桥设备)、ipvlan、loopback(lo 设备)、macvlan、ptp(Veth Pair 设备),以及 vlan。
我在前面提到过的 Flannel、Weave 等项目,都属于“网桥”类型的 CNI 插件。所以在具体的实现中,它们往往会调用 bridge 这个二进制文件。这个流程,我马上就会详细介绍到。
第二类,叫作 IPAM(IP Address Management)插件,它是负责分配 IP 地址的二进制文件。比如,dhcp,这个文件会向 DHCP 服务器发起请求;host-local,则会使用预先配置的 IP 地址段来进行分配。
第三类,是由 CNI 社区维护的内置 CNI 插件。比如:flannel,就是专门为 Flannel 项目提供的 CNI 插件;tuning,是一个通过 sysctl 调整网络设备参数的二进制文件;portmap,是一个通过 iptables 配置端口映射的二进制文件;bandwidth,是一个使用 Token Bucket Filter (TBF) 来进行限流的二进制文件。
由于 Flannel 项目对应的 CNI 插件已经被内置了,所以它无需再单独安装。而对于 Weave、Calico 等其他项目来说,我们就必须在安装插件的时候,把对应的 CNI 插件的可执行文件放在 /opt/cni/bin/ 目录下。
就需要在宿主机上安装 flanneld(网络方案本身)。而在这个过程中,flanneld 启动后会在每台宿主机上生成它对应的CNI 配置文件(它其实是一个 ConfigMap),从而告诉 Kubernetes,这个集群要使用 Flannel 作为容器网络方案。
这个 CNI 配置文件的内容如下所示:
1 | $ cat /etc/cni/net.d/10-flannel.conflist |
5.2.3 CNI 插件设计考量


5.3 CNI Plugin
5.3.1 Flannel
Flannel 是由 CoreOS 开发的项目,是 CNI 插件早期的入门产品,简单易用。
Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上运行flanneld 来守护进程。
每个节点都被分配一个子网,为该节点上的 Pod 分配 IP 地址。
同一主机内的 Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过 flanneld 将其流量封装在 UDP 数据包中,以路由到适当的目的地。
封装方式默认和推荐的方法是使用 VXLAN,因为它具有良好的性能,并且比其他选项要少些人为干预。虽然使用 VXLAN 之类的技术封装的解决方案效果很好,但缺点就是该过程使流量跟踪变得困难。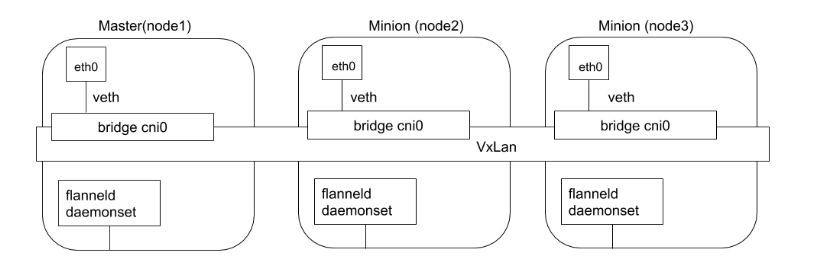
5.3.2 Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
对于同网段通信,基于第 3层,Calico 使用 BGP 路由协议在主机之间路由数据包,使用BGP路由协议也意味着数据包在主机之间移动时不需要包装在额外的封装层中。
对于跨网段通信,基于 IPinlP 使用虚拟网卡设备 tunl0,用一个IP 数据包封装另一个IP数据包,外层IP数据包头的源地址为隧道入口设备的 IP 地址,目标地址为隧道出口设备的IP地址。
网络策路是 Calico 最受欢迎的功能之一,使用 ACLs 协议和 kube-proxy 来创建iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策路。这意味着您可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强对网络环境的控制
Calico 属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境, Calico 是一个不错选择。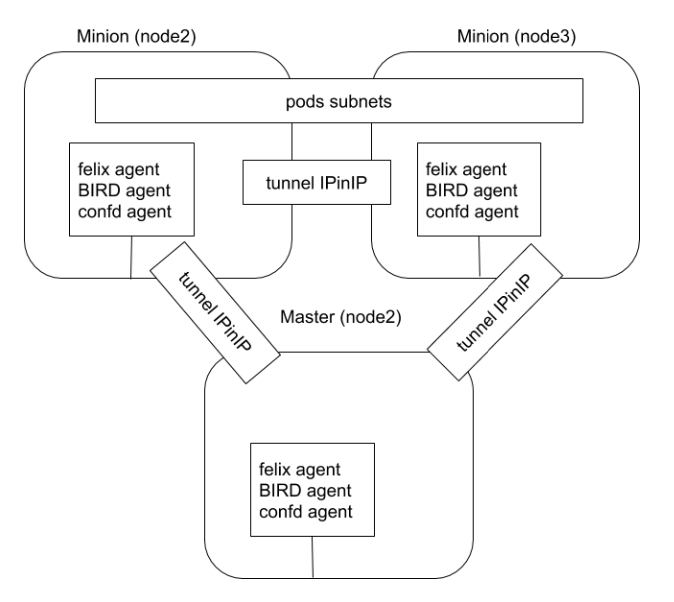
Calico VXLan: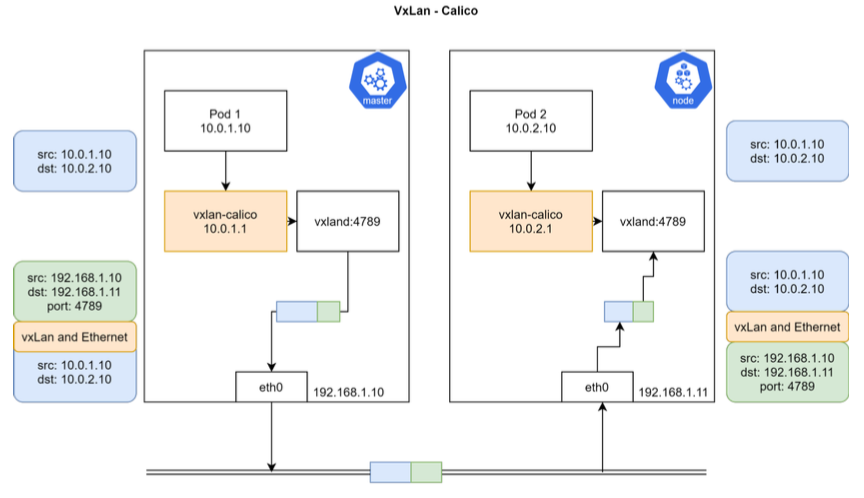
6 CSI
6.1 CSI 插件体系的设计原理
默认情况下,Kubernetes 里通过存储插件管理容器持久化存储的原理,可以用如下所示的示意图来描述: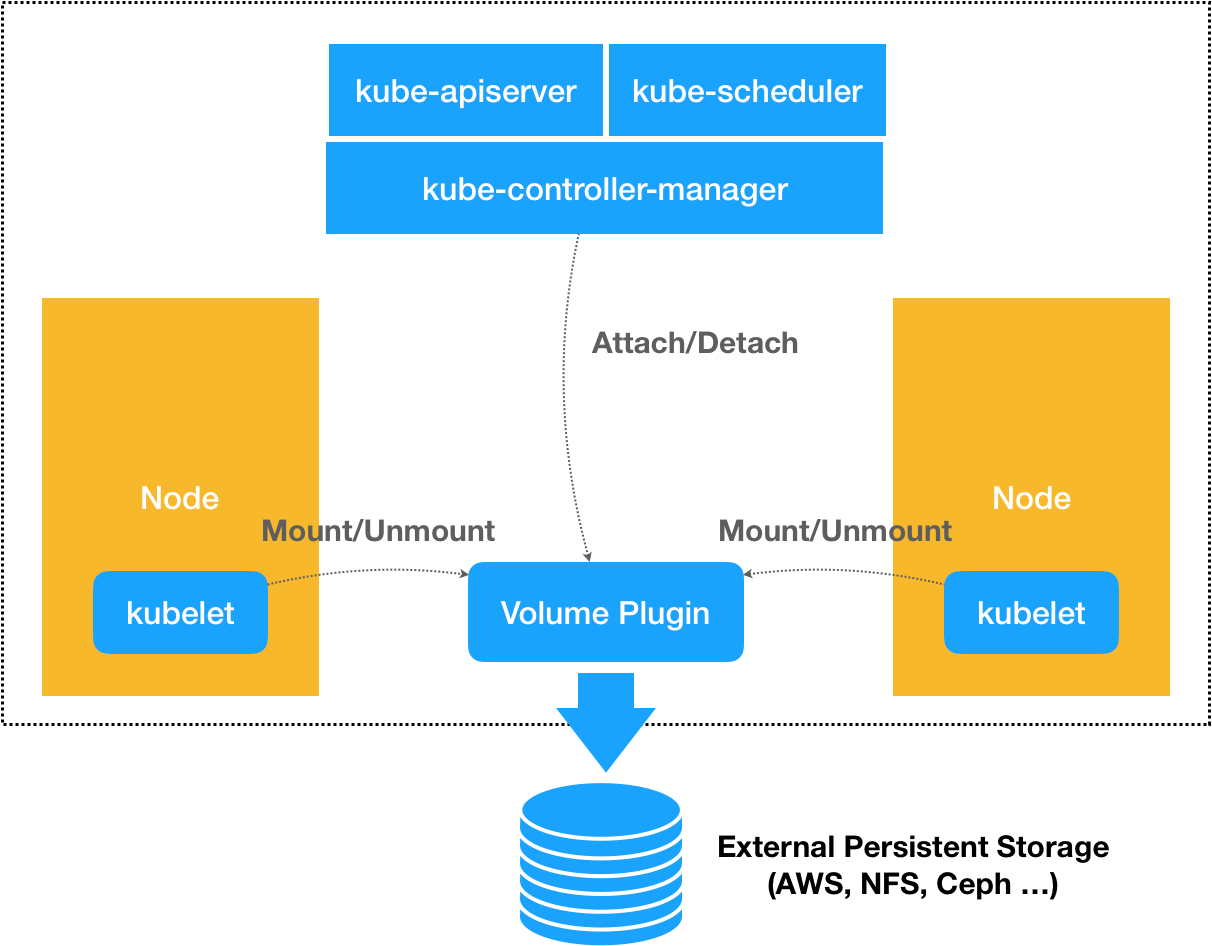
无论是 FlexVolume,还是 Kubernetes 内置的其他存储插件,它们实际上担任的角色,仅仅是 Volume 管理中的“Attach 阶段”和“Mount 阶段”的具体执行者。而像 Dynamic Provisioning 这样的功能,就不是存储插件的责任,而是 Kubernetes 本身存储管理功能的一部分。
CSI 插件体系的设计思想,就是把这个 Provision 阶段,以及 Kubernetes 里的一部分存储管理功能,从主干代码里剥离出来,做成了几个单独的组件。这些组件会通过 Watch API 监听 Kubernetes 里与存储相关的事件变化,比如 PVC 的创建,来执行具体的存储管理动作。
而这些管理动作,比如“Attach 阶段”和“Mount 阶段”的具体操作,实际上就是通过调用 CSI 插件来完成的。
这种设计思路,我可以用如下所示的一幅示意图来表示: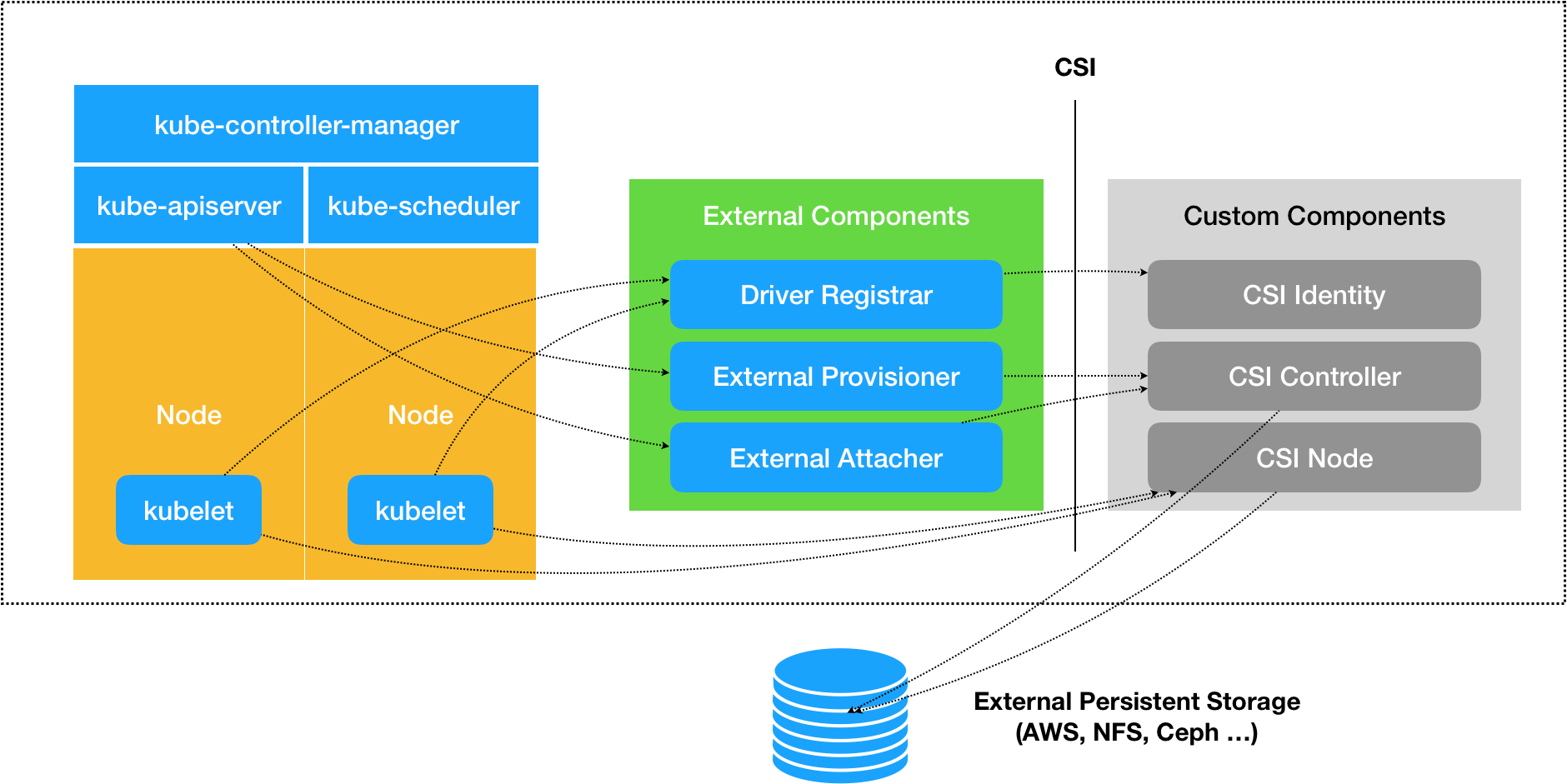
这套存储插件体系多了三个独立的外部组件(External Components),即:Driver Registrar、External Provisioner 和 External Attacher,对应的正是从 Kubernetes 项目里面剥离出来的那部分存储管理功能。
- Driver Registrar 组件,负责将插件注册到 kubelet 里面(这可以类比为,将可执行文件放在插件目录下)。而在具体实现上,Driver Registrar 需要请求 CSI 插件的 Identity 服务来获取插件信息。
- External Provisioner 组件,负责的正是 Provision 阶段。在具体实现上,External Provisioner 监听(Watch)了 APIServer 里的 PVC 对象。当一个 PVC 被创建时,它就会调用 CSI Controller 的 CreateVolume 方法,创建对应 PV。
- External Attacher 组件,负责的正是“Attach 阶段”。在具体实现上,它监听了 APIServer 里 VolumeAttachment 对象的变化。VolumeAttachment 对象是 Kubernetes 确认一个 Volume 可以进入“Attach 阶段”的重要标志。
CSI 插件里的三个服务:CSI Identity、CSI Controller 和 CSI Node。
- CSI 插件的 CSI Identity 服务,负责对外暴露这个插件本身的信息,如下所示:
1 | service Identity { |
- CSI Controller 服务,定义的是对 CSI Volume(对应 Kubernetes 里的 PV)的管理接口,比如:创建和删除 CSI Volume、对 CSI Volume 进行 Attach/Dettach(在 CSI 里,这个操作被叫作 Publish/Unpublish),以及对 CSI Volume 进行 Snapshot 等,它们的接口定义如下所示:CSI Controller 服务里定义的这些操作有个共同特点,那就是它们都无需在宿主机上进行,而是属于 Kubernetes 里 Volume Controller 的逻辑,也就是属于 Master 节点的一部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29service Controller {
// provisions a volume
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
// deletes a previously provisioned volume
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
// make a volume available on some required node
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
// make a volume un-available on some required node
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
...
// make a snapshot
rpc CreateSnapshot (CreateSnapshotRequest)
returns (CreateSnapshotResponse) {}
// Delete a given snapshot
rpc DeleteSnapshot (DeleteSnapshotRequest)
returns (DeleteSnapshotResponse) {}
...
}
CSI Controller 服务的实际调用者,并不是 Kubernetes(即:通过 pkg/volume/csi 发起 CSI 请求),而是 External Provisioner 和 External Attacher。这两个 External Components,分别通过监听 PVC 和 VolumeAttachement 对象,来跟 Kubernetes 进行协作。
CSI Volume 需要在宿主机上执行的操作,都定义在了 CSI Node 服务里面,如下所示:需要注意的是,“Mount 阶段”在 CSI Node 里的接口,是由 NodeStageVolume 和 NodePublishVolume 两个接口共同实现的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27service Node {
// temporarily mount the volume to a staging path
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
// unmount the volume from staging path
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
// mount the volume from staging to target path
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
// unmount the volume from staging path
rpc NodeUnpublishVolume (NodeUnpublishVolumeRequest)
returns (NodeUnpublishVolumeResponse) {}
// stats for the volume
rpc NodeGetVolumeStats (NodeGetVolumeStatsRequest)
returns (NodeGetVolumeStatsResponse) {}
...
// Similar to NodeGetId
rpc NodeGetInfo (NodeGetInfoRequest)
returns (NodeGetInfoResponse) {}
}