
AI 大模型微调
0 参考资料
GeekAGI 知识库: https://geek-agi.feishu.cn/wiki/B9rYwwg6xidZYJkbrlscxTQFnOc
项目地址:https://github.com/DjangoPeng/LLM-quickstart
0.1 搭建开发环境
本项目对于硬件有一定要求:GPU 显存不小于16GB,支持最低配置显卡型号为 NVIDIA Tesla T4。
建议使用 GPU 云服务器来进行模型训练和微调。
项目使用 Python 版本为 3.10,环境关键依赖的官方文档如下:
- Python 环境管理 Miniconda
- Python 交互式开发环境 Jupyter Lab
以下是详细的安装指导(以 Ubuntu 22.04 操作系统为例):
- 安装操作系统级软件依赖
1
2
3
4sudo apt update && sudo apt upgrade
sudo apt install ffmpeg
# 检查是否安装成功
ffmpeg -version
- 安装 Python 环境管理工具 Miniconda
1 | mkdir -p ~/miniconda3 |
安装完成后,建议新建一个 Python 虚拟环境,命名为 peft。
1 | conda create -n peft python=3.10 |
之后每次使用需要激活此环境。
- 安装 Python 依赖软件包
完整 Python 依赖软件包见requirements.txt。
1 | pip install -r requirements.txt |
- 安装和配置 Jupyter Lab
上述开发环境安装完成后,使用 Miniconda 安装 Jupyter Lab:
1 | conda install -c conda-forge jupyterlab |
使用 Jupyter Lab 开发的最佳实践是后台常驻,下面是相关配置(以 root 用户为例):
1 | 生成 Jupyter Lab 配置文件, |
打开上面执行输出的~/.jupyter/jupyter_lab_config.py配置文件后,修改以下配置项:
1 | c.ServerApp.allow_root = True # 非 root 用户启动,无需修改 |
使用 nohup 后台启动 Jupyter Lab
1 | nohup jupyter lab --port=8000 --NotebookApp.token='替换为你的密码' --notebook-dir=./ & |
Jupyter Lab 输出的日志将会保存在 nohup.out 文件(已在 .gitignore中过滤)。
- 安装 CUDA Toolkit 和 GPU 驱动
根据你的实际情况,找到对应的 CUDA 12.04:下载并安装 CUDA 12.04 Toolkit(包含GPU驱动):
1 | wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run |
**注意使用runfile方式,可以连同版本匹配的 GPU 驱动一起安装好。
安装完成后,使用 nvidia-smi 指令查看版本:
1 | nvidia-smi |
1 大语言模型(LLM)的文本生成
1.1 LLM 的推理方式
大型语言模型(LLM)基于 Transformer 架构,通过两个主要步骤生成文本:
- 预填充(Prefill):将输入提示中的所有Token转换为模型可以处理的格式。
- 生成(Completion):模型采用自回归方式,一次生成一个新Token。
例如,在一个聊天机器人与 LLM 的对话中:
- 第一个问题输入了 8 个Token
- 第二个问题输入了 10 个Token
那么第二个问题的「输入Token数」是多少?
一般用户可能会认为是 10 个,但实际上消耗的Token数是:8 + 第一次生成的输出Token数 + 10。
1.2 LLM 的文本生成模式
1.2.1 Completion模式
Completion模式是LLM模型最基础的文本生成模式,适用于从给定提示(prompt)开始自动补全文本段落或回答问题。
工作流程:
- 输出提示:用户提供一个完整的输入提示:
1
prompt = "The history of artificial intelligence is"
- 生成文本:基于输入提示,LLM 模型使用逐个Token生成的方式生成后续文本。
1.2.2 Chat 模式
Chat模式旨在模拟多轮对话,使得LLM能够与用户进行连贯的互动。
工作流程:
- 多轮对话输入:用户提供多轮对话的上下文,如:
1
2
3
4messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Can you tell me about the history of AI?"}
] - 生成回复:基于对话上下文,LLM模型逐个Token生成助手的回复。
在生成策略方面, 两种模式都采用了逐个Token生成的策略, 即根据前面已生成的Token预测下一个Token。
1.3 LLM 的文本生成策略
大规模语言模型(LLM)的文本生成策略指的是从模型中生成文本的具体方法或技术。这些策略用于控制模型生成的文本内容、质量和连贯性。LLM 模型会为所有Token输出 logits(得分),通过 softmax 函数可以将这些得分转换成每个Token在生成时被选中的概率。
1.3.1 Greedy sampling(贪婪抽样)
在贪婪策略中,模型总是选择它认为在每一步最有可能的Token,不考虑其他可能性或探索不同选项。模型选择概率最高的Token,并根据所选的Token继续生成文本。
使用贪婪策略计算上高效且直接,但有时会导致生成重复或过于确定的输出。
由于模型在每一步只考虑最有可能的Token,它可能无法充分捕捉上下文和语言的多样性,或生成最具创意的回应。
1.3.2 Beam search(束搜索)
在束搜索中,模型假设了一组“K”个最有可能的Token,而不是在每一步只考虑最有可能的Token。这组 K个Token被称为“束”(beam)。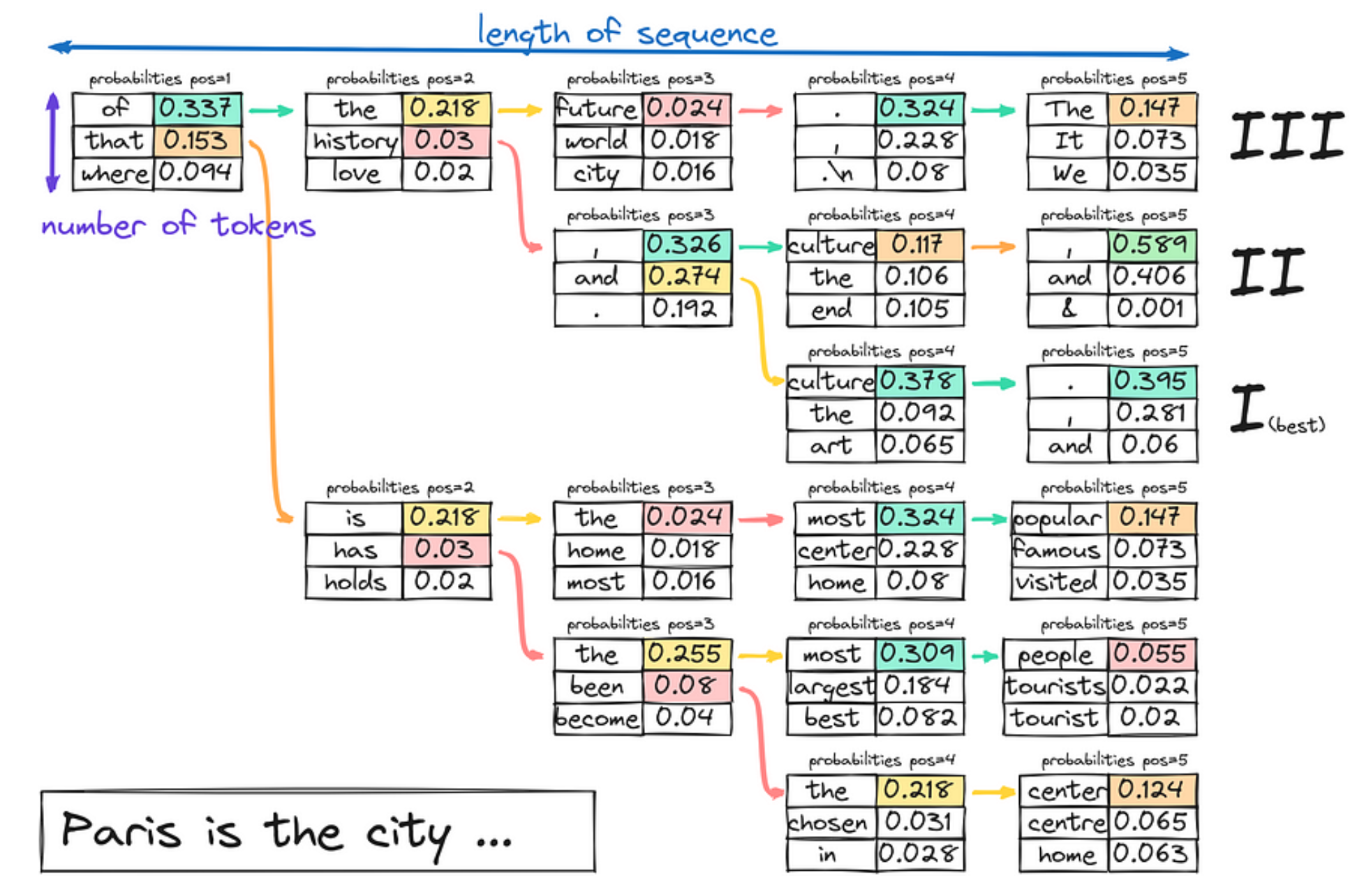
模型为每个Token生成可能的序列,并在文本生成的每一步通过扩展每个束的可能线路来跟踪他们的概率。这个过程持续进行,直到生成的文本达到所需的长度,或者每个束都遇到一个“结束”Token。模型从所有束中选择整体概率最高的序列作为最终输出。
1.3.3 Normal random sampling(正常随机抽样)
通过选择一个随机值将其映射到选定的Token上来选择下一个词,可以想象成转动一个轮盘,每个Token的区域由它的概率决定。概率越高,Token被选中的机会就越大。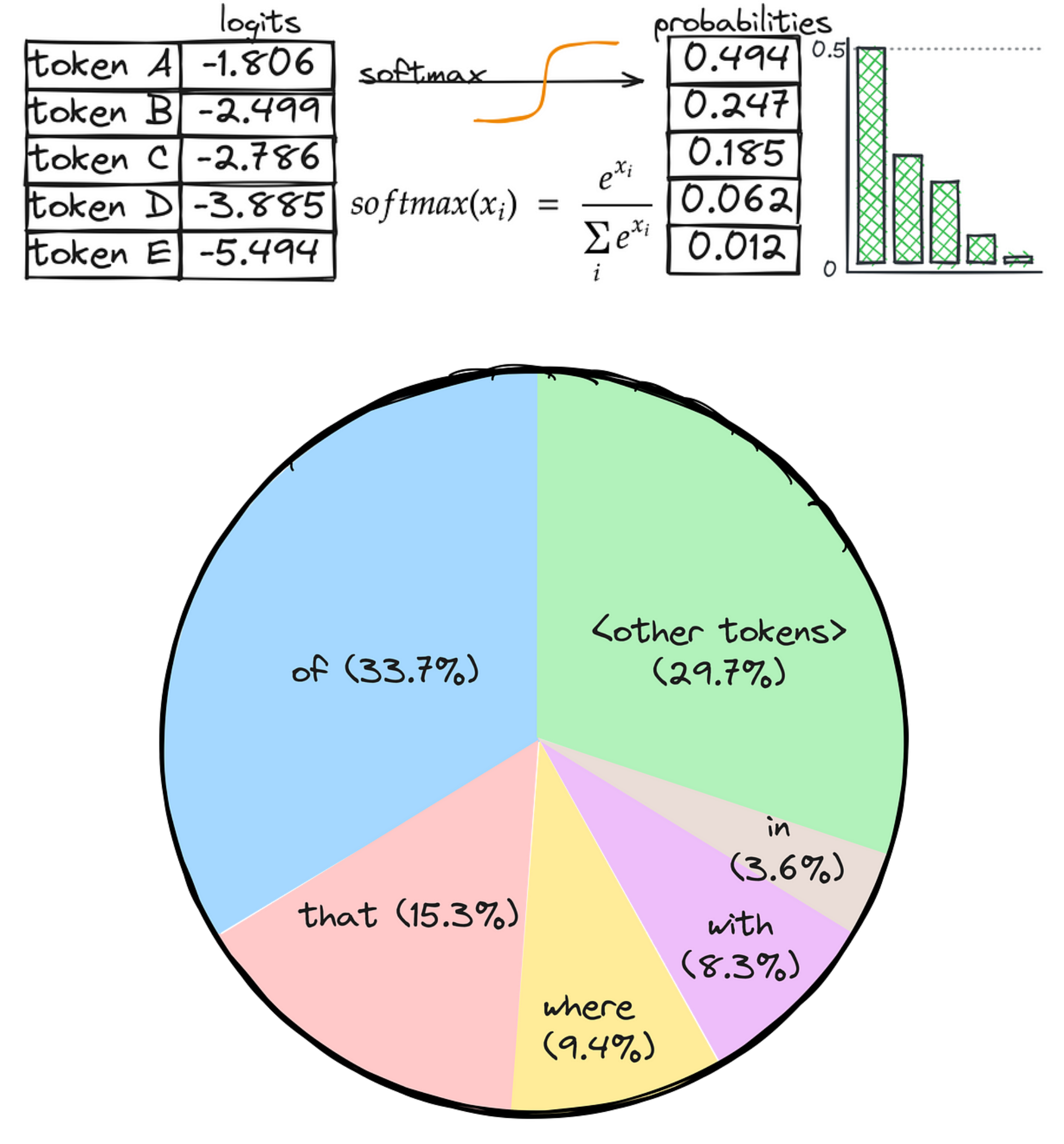
1.3.4 Random sampling with Temperature(随机温度抽样)
LLM 使用softmax 函数将 logits 转换为概率。温度这个超参数,会影响文本生成的随机性。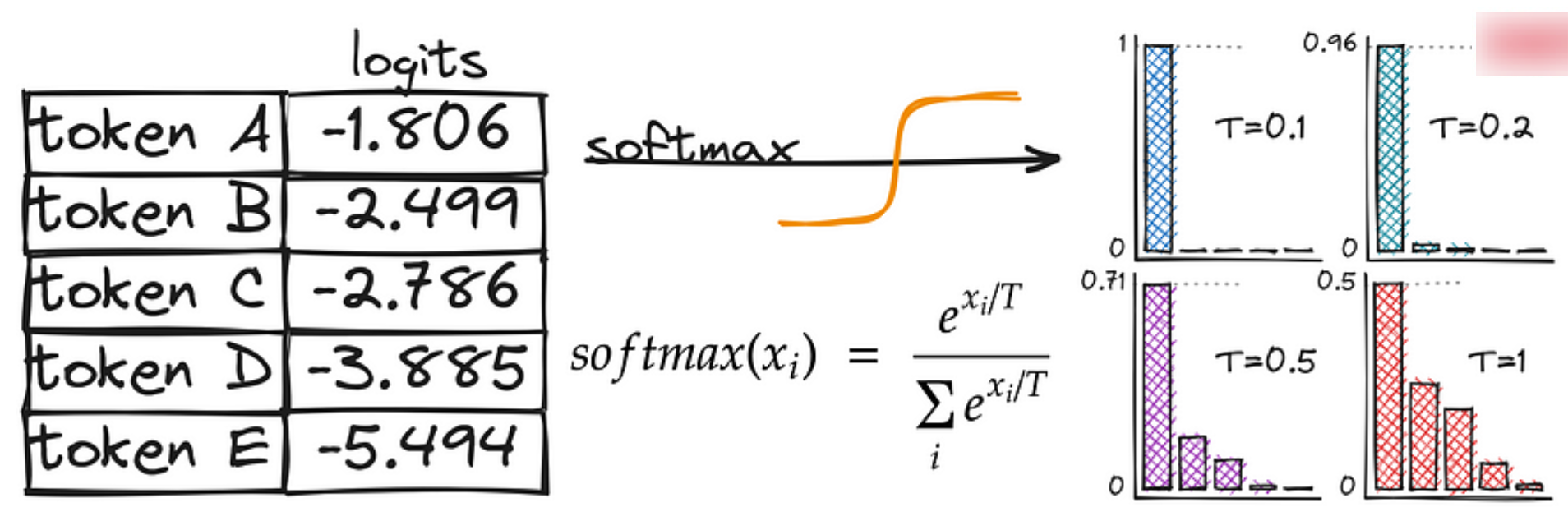
在标准的softmax函数中,根据模型输出的 logits 计算每个Token的概率,其中,$x_i$ 表示第$i$个Token的logit值,$N$为词表大小。
其中,在温度softmax 函数中,引入了一个 温度参数 T,温度T作为分母出现在指数项中,这个参数可以控制概率分布的形状:
- 当$T = 1$时,温度Softmax函数退化为标准的Softmax函数。此时,概率分布与原始logits保持一致。
- 当$T > 1$时,温度较高,概率分布变得更加平缓。这意味着原本概率较低的Token现在有更大的机会被选中,生成的文本将更加多样化和富有创造性。但同时,生成的文本也可能偏离原始主题或失去连贯性。
- 当$0 < T < 1$时,温度较低,概率分布变得更加尖锐。原本概率较高的Token将占据主导地位,生成的文本将更加保守和确定性强。这有助于生成与提示高度相关的文本,但可能缺乏多样性
因此,温度参数$T$提供了一种调节生成文本特性的方法。可以根据具体的应用场景和需求,灵活选择合适的温度值。较高的温度适用于创意写作、故事生成等任务,而较低的问题则适用于事实回答、摘要生成等任务。
1.3.5 Top-K sampling(Tok-K抽样)
结合温度参数,对仅Top-K 的token 进行随机采样。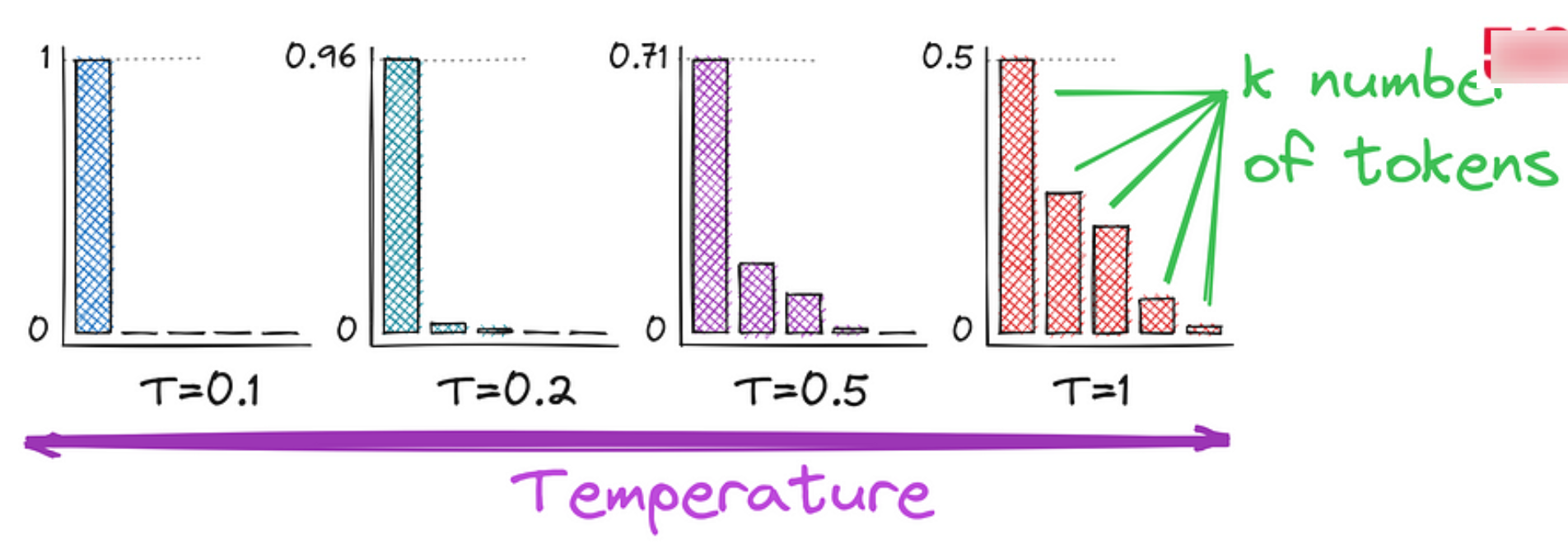
1.3.6 Nucelus sampling or top-p sampling(Top-p 抽样)
Token概率的分布可能会有很大差异,这在文本生成过程中可能会带来意想不到的结果。核采样(Nucleus Sampling)旨在解决不同采样技术的某些局限性。它不是指定要考虑的固定数量的“K”个Token,而是使用一个概率阈值“p”。这个阈值代表您希望在采样中包含的累积概率。
模型在每一步计算所有可能Token的概率,然后按降序排列。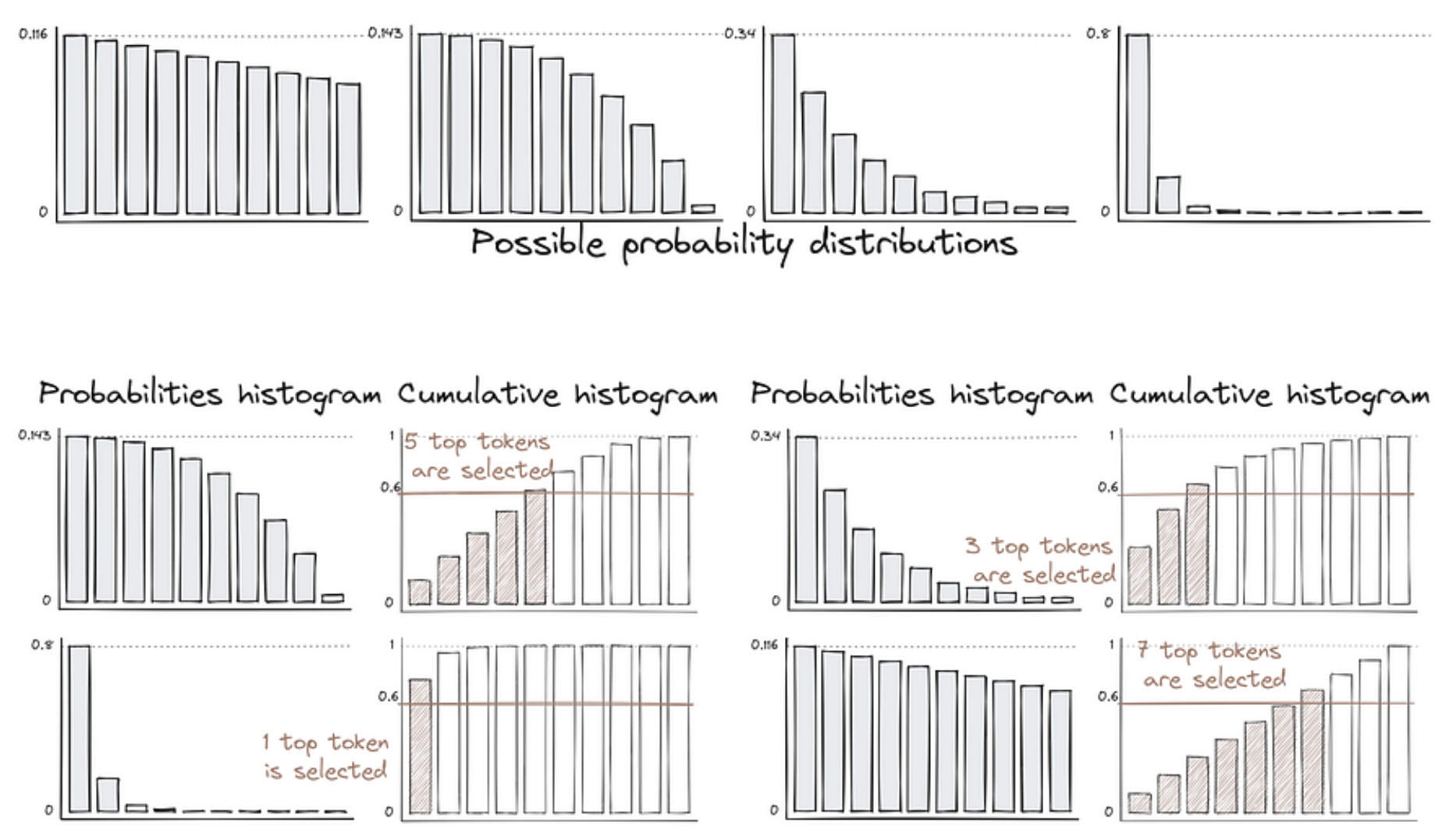
模型继续向生成的文本中添加Token,直到它们的总概率超过指定的阈值。
核采样的优势在于允许基于上下文进行更动态和自适应的Token选择。在每一步选择的Token数量可以根据该上下文中 Token 的概率而变化,这可以导致更多样化和更高质量的输出。
1.3.7 LLM 生成策略比较
主要生成策略的比较:
- 贪婪搜索: 确定性强,但可能生成重复或缺乏多样性的内容。
- 束搜索: 生成质量高,但计算复杂度较高。
- 温度采样: 可调节生成内容的多样性和随机性。
- Top-k 和 Top-p 采样:提高生成质量,同时保持灵活性。
生成策略选择建议:
- 贪婪搜索: 用于生成确定性较高的内容。
- 束搜索: 用于生成质量要求较高的内容。
- 温度采样: 用于调整生成的随机性。
- Top-k和Top-p采样: 用于确保生成内容的多样性。
2 LLM 的 Token 与分词器
LLM(大型语言模型)中的 Token 是模型在处理文本时使用的基本单位。它可以是单词、子词甚至字符,具体取决于模型的分词策略。不同模型和库对 Token 的定义和分词方式可能有所不同。
2.1 分词器(Tokenizer)
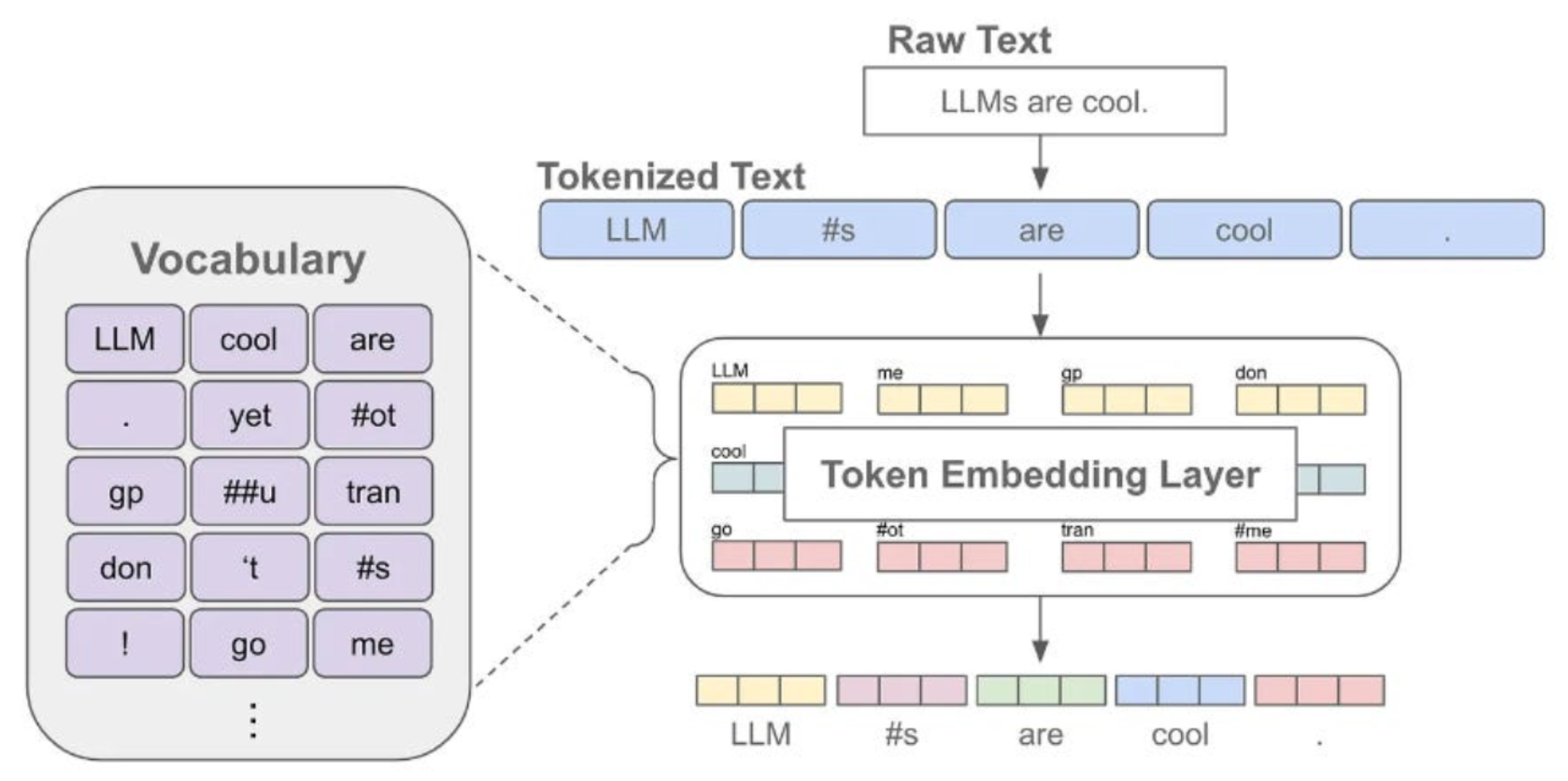
分词器用于将文本转换为模型可以理解的 Token 序列。常见的分词方式包括:
- 字典分词:使用预定义的词汇表将输入文本与词汇表中的词匹配。
- BPE(Byte-Pair Encoding):一种子词分词方法,将常见的字符或字符组合编码成 Token。
- SentencePiece:类似 BPE 的子词分词方法,通常用于处理多种语言。
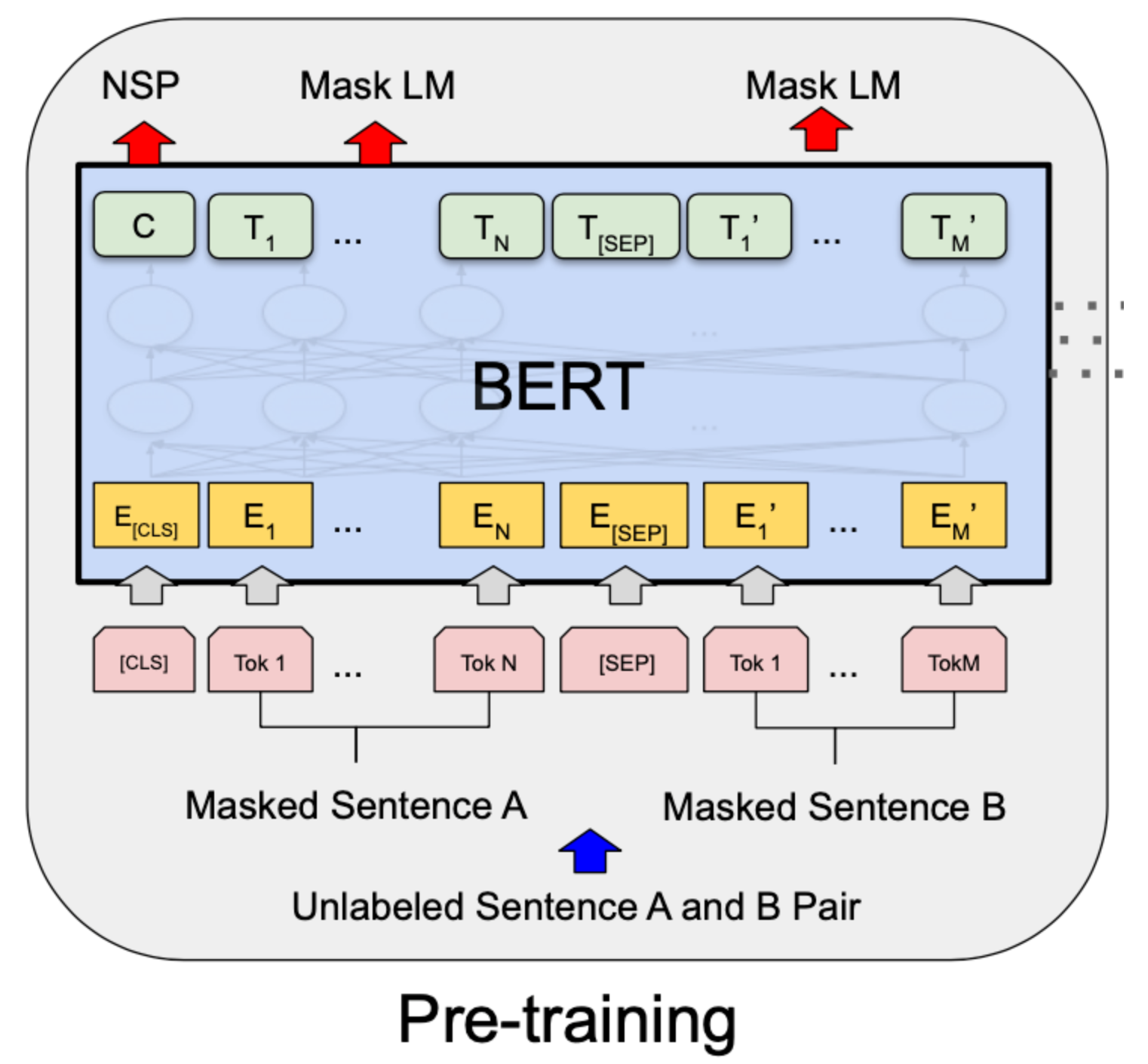
- WordPiece:BERT 模型使用的分词方法,通过子词组合生成更大的词汇。
特殊Token:
在 LLM 中,通常还会使用一些特殊的 Token 来标识不同的功能:
- [CLS]:用于表示句子或文本的开始。
- [SEP]:分隔不同句子。
- [PAD]:用于填充对齐不同长度的输入。
- [UNK]:表示未知的 Token,通常是词汇表中未包含的单词或符号。
- [MASK]:用于掩码语言模型中的填补位置(如 BERT 的预训练任务)。
Token 计数:
在 LLM 的推理过程中,输入和输出的 Token 数量对计算资源和费用具有重要影响。例如,GPT-3 使用的分词策略通常是基于字节对编码(BPE),平均每个单词可能会被分成 1.3 个Token。
使用示例:
1 | import tikToken |
输出:
1 | Tokens: ['Hello', ',', ' I', "'m", ' an', ' AI', ' assistant', '.'] |
3 LLM 的文本生成过程
3.1 LLM 文本生成步骤
- 输入阶段(Input):
- 用户提供一个初始输入,这可以是一个提示、问题或部分文本,模型将基于此生成文本。
- 分词(Tokenization):
输入文本被转换成一系列的Token(Tokens)。分词器会将输入文本分割成更小的单元,这些单元可以是单词、子词或字符,这取决于模型的分词策略。
- 嵌入(Embedding):
每个Token被转换成一个固定长度的向量,这个过程称为嵌入。这些向量通常通过预训练的词嵌入模型生成,它们能够捕捉词汇的语义信息。
- 位置编码(Positional Encoding):
为了保持词序信息,因为Transformer模型本身不具备捕捉顺序的能力,通常会给每个嵌入向量添加一个位置编码。
- Transformer处理:
- 经过嵌入和位置编码的输入被送入Transformer模型。Transformer模型由多个相同的层组成,每层都包括自注意力(Self-Attention)机制和前馈神经网络(Feed-Forward NeuralNetwork)。
- 自注意力机制允许模型在处理当前词时考虑到句子中的其他词,这有助于捕捉文本中的长距离依赖关系。
- 输出转换(Output Transformation):
Transformer模型的最后一层输出被送入一个线性层,将输出向量映射到模型词汇表大小的维度空间。
- Softmax函数:
应用Softmax函数将线性层的输出转换为概率分布,每个Token对应的概率表示模型预测该Token是下一个词的可能性。
- 采样(Sampling):
基于Softmax函数得到的概率分布,模型进行采样以选择下一个生成的Token。采样策略可以是贪心采样、随机采样、核采样(Nucleus Sampling)或温度采样(TemperatureSampling)等。
- 生成文本:
重复采样过程,直到生成了足够长度的文本或直到遇到句子结束的Token。
- 后处理(Post-processing):
生成的文本可能需要一些后处理,如去除多余的特殊Token,或者进行语法和语义的修正。
3.2 LLM 文本生成的Q、K、V
在大语言模型(LLM)的文本生成任务中,Q、K、V分别代表Query(查询)、Key(键)和Value(值)。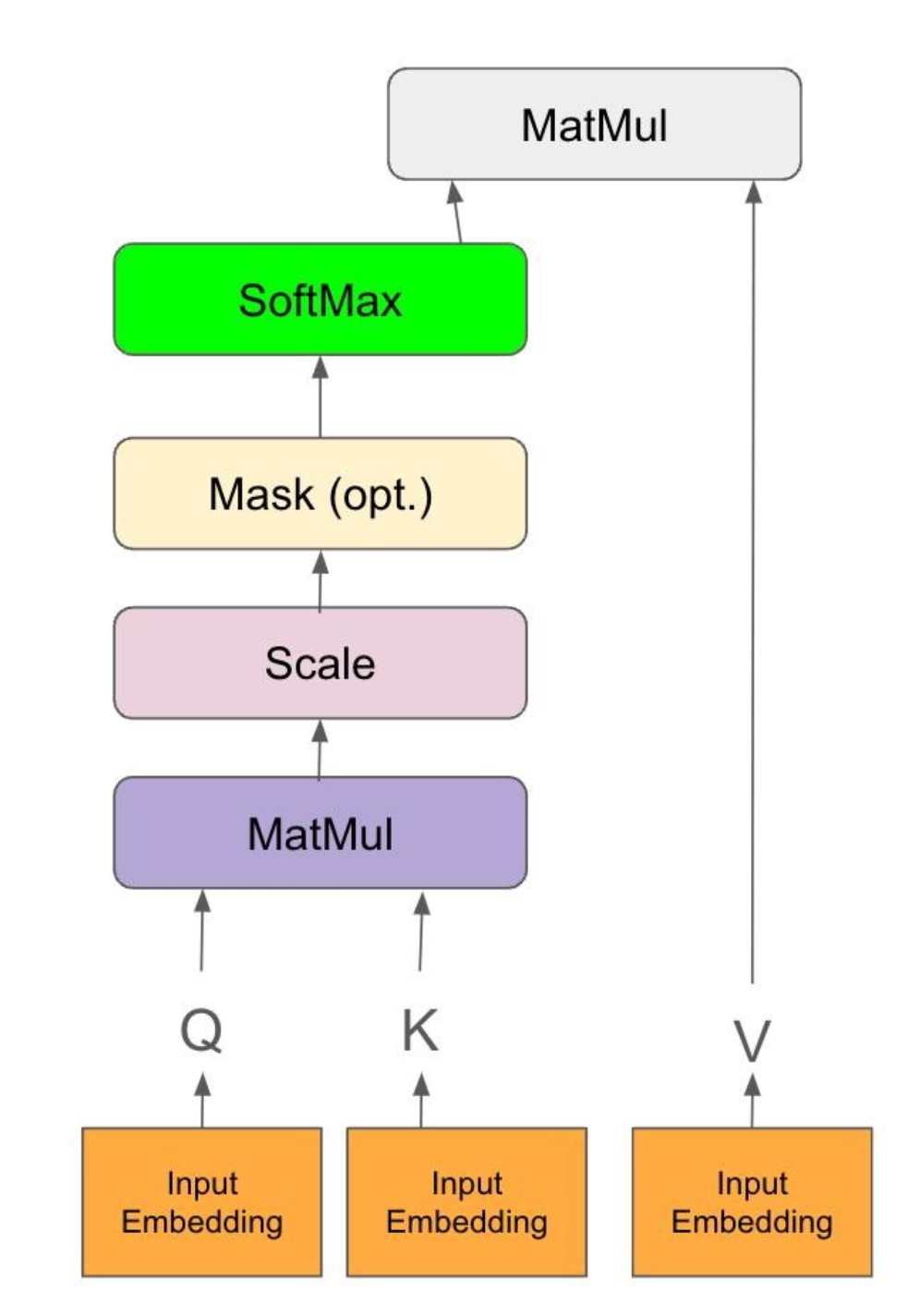
这三个概念源于注意力机制(Attention Mechanism), 特别是自注意力(Self-Attention)机制, 它们在Transformer架构中扮演着关键角色。
- Query(Q): 表示当前正在处理的词或词组。在自注意力机制中, 每个词都被视为一个Query。对于生成任务, Query通常是前面已生成的词或词组。我们希望了解当前Query与其他词(Key-Value对)之间的相关性, 以决定如何生成下一个词。
- Key(K): 表示一组候选词或词组, 用于与Query进行相关性计算。在自注意力机制中, 每个词也同时扮演Key的角色。通过计算Query与不同Key之间的相似度(通常使用点积或其他相似度函数), 我们可以得到一个注意力分布, 表示当前Query与每个Key的相关程度。
- Value(V): 与Key相对应, 表示每个候选词或词组的实际表示或含义。一旦我们根据Query和Key的相关性计算出注意力分布, 就可以使用这个分布对Value进行加权求和,得到当前Query的上下文表示。这个上下文表示融合了与当前Query相关的所有词的信息, 用于指导下一个词的生成。
在Transformer的自注意力层中, 输入序列首先被映射到三个不同的矩阵: Q矩阵、K矩阵和V矩阵。这三个矩阵的维度通常为(序列长度, 隐藏层大小)。然后, 通过将Q矩阵与K矩阵转置相乘, 并除以一个缩放因子(通常为隐藏层大小的平方根), 得到注意力分布。最后, 将注意力分布与V矩阵相乘, 得到输出表示。
对于生成任务, Transformer的解码器部分会根据前面生成的词(作为Query)与编码器输出或解码器自身的隐藏状态(作为Key-Value对)进行交互, 逐步生成后续的词。这个过程反复进行, 直到生成结束Token或达到最大长度限制。
总之, Q、K、V机制使得大语言模型能够动态地关注与当前生成相关的上下文信息, 从而生成更加连贯、自然的文本。这种机制也使得模型能够处理长距离依赖关系, 捕捉词与词之间的复杂交互。
Q、K、V 示例:
以”Paris is the city”作为提示(Prompt), 看看大语言模型如何利用Q、K、V机制生成后续文本。假设我们要生成的下一个词是”of”。
在示例中”of”可以被视为一种”预填充”(prefill)或”预测”(prediction)阶段得到的Token。
在实际的文本生成过程中, 大语言模型通常会使用一种称为”自回归”(autoregressive)的方法, 即根据前面已生成的词来预测下一个词。
这个过程分为两个阶段:
- 预填充(Prefill)阶段: 在这个阶段, 模型根据前面的上下文(如”Paris is the city”)和其内部的语言知识,预测出最可能的下一个词。在我们的例子中, 模型预测”of”是一个高概率的候选词。这个预测过程本质上就是通过Q、K、V 机制, 利用注意力权重和上下文表示来估计每个词的概率分布。
- 采样(Sampling)阶段: 一旦模型得到了下一个词的概率分布 ,它就可以从这个分布中采样出一个实际的词。常见的采样策略包括贪婪采样(选择概率最高的词)、随机采样(根据概率随机选择)、束搜索(保留多个高概率候选)等。采样得到的词会被添加到已生成的序列中,然后模型再次进入预填充阶段,预测下一个词。
假设我们要生成的下一个词是”of”。此时, “of”对应的Query向量(Q)会与前面已生成词(“Paris”, “is”, “the”, “city”)的Key向量(K)进行交互。
- 首先, 模型将”of”的嵌入向量作为Query(Q), 将”Paris”,”is”,”the”,”city”的嵌入向量分别作为Key(K)。
- 然后, 模型计算Query与每个Key的相似度得分。在这个例子中,”of”可能与”city”的相似度最高, 因为”city of”是一个常见的短语。相似度得分可以表示为:
1
2
3
4Similarity("of", "Paris") = 0.1
Similarity("of", "is") = 0.2
Similarity("of", "the") = 0.3
Similarity("of", "city") = 0.8 - 接下来, 模型将这些相似度得分转化为注意力权重。这通常通过Softmax函数实现, 以确保所有权重的和为1:
1
2Attention_weights = Softmax([0.1, 0.2, 0.3, 0.8])
= [0.05, 0.07, 0.10, 0.78] - 最后, 模型使用注意力权重对每个词的Value向量(V)进行加权求和。Value向量表示每个词的实际语义表示。假设我们有:那么,”of”的上下文表示(Context)就是:
1
2
3
4Value("Paris") = [0.2, 0.1, ..., 0.5]
Value("is") = [0.3, 0.2, ..., 0.4]
Value("the") = [0.1, 0.3, ..., 0.2]
Value("city") = [0.5, 0.2, ..., 0.9]这个上下文表示融合了与”of”最相关的词(“city”)的语义信息, 同时也考虑了其他词的影响。1
2
3Context("of") = 0.05 * Value("Paris") + 0.07 * Value("is")
+ 0.10 * Value("the") + 0.78 * Value("city")
= [0.44, 0.20, ..., 0.79]
模型将使用这个上下文表示来预测下一个词, 比如”light”, “love”, “fashion”等。
通过这种方式, 大语言模型可以动态地关注与当前生成最相关的上下文, 并根据这些信息生成连贯、自然的后续文本。在实际的模型中, 这个过程会重复多次(多头注意力机制), 并通过多个Transformer层进行处理, 以捕捉更复杂、更抽象的语言模式和依赖关系。
3.3 预填充(prefill)和解码(decode)
预填充和解码对于模型生成连贯、准确和高效的文本非常重要。
3.3.1 预填充(prefill)阶段
预填充阶段主要用于准备初始上下文,为模型生成后续文本提供基础。在这个阶段,模型会处理输入的初始文本(通常是用户提供的提示或上下文),并生成相应的内部状态(如KV缓存)。
具体过程:
- 初始上下文输入:
- 用户提供一个初始文本作为提示,例如问题、句子或段落
- 该文本通常被编码为一系列Token
- 初始上下文的注意力计算:
- 模型对输入的所有Token进行处理,生成键和值,并存储在KV缓存中
- 初始概率分布
- 计算最后一个Token的概率分布,作为生成下一个Token的起始点
3.3.2 解码(decode)阶段
解码阶段是模型根据预填充阶段准备好的上下文,生成后续文本的过程。在这个阶段,模型会逐步生成每个新Token,并在每次生成后更新KV缓存。
具体过程:
- Token生成:
- 从预填充阶段的初始概率分布中采样一个新Token,作为下一个输入。
- 根据用户选择的策略(如贪心、采样、温度)进行采样。
- KV缓存更新
- 使用新Token进行前向传递,更新KV缓存,生成新的键和值。
- 生成新的概率分布,用于采样下一个Token。
- 循环迭代
- 重复步骤1和步骤2,直到达到生成的最大长度或满足停止条件。
预填充和解码阶段的意义:
- 预填充阶段的意义:
- 为模型提供初始的上下文,使得生成的文本更连贯和准确
- 预先计算KV缓存,减少解码阶段的计算量
- 解码阶段的意义
- 根据预填充阶段的初始上下文逐步生成连贯的文本
- 通过选择不同的采样策略(如温度、Top-k、Top-p)控制生成的文本质量
4 大模型微调原理
4.1 基座模型到对话模型的转变
预训练LLM基础模型
在大规模语料库上预训练一个LLM基础模型。这个模型通常是一个大型的Transformer模型, 如GPT-3、T5、LLaMA等。
预训练的目标是让模型学习到语言的基本结构、语法、语义等一般性知识。
预训练通常采用自监督学习的方式, 即让模型在大量无标签的文本数据上学习预测下一个词或恢复被掩盖的词。通过这种方式, 模型可以学习到词汇、短语、句法、语义等多层次的语言表征。
预训练得到的LLM基础模型具有强大的语言理解和生成能力, 但它们通常是通用的, 没有针对特定任务或领域进行优化。使用SFT进行任务适应
为了让LLM基础模型适应特定的任务,如对话、问答、摘要等, 我们需要在特定任务的标注数据集上对其进行有监督微调(SFT)。
在对话任务中, 我们通常准备一个由人类对话组成的数据集, 其中每个样本包括一个对话历史(上下文)和一个人类回复(目标)。
然后, 我们将这些样本输入到LLM基础模型中, 让其学习根据给定的对话历史生成恰当的回复。SFT的过程类似于监督学习, 即最小化模型生成的回复与真实人类回复之间的差异(通常使用交叉熵损失)。
通过在大量对话样本上训练, 模型可以学习到对话的一般模式、礼貌用语、常见话题等。SFT得到的模型已经可以进行基本的对话交互, 但其生成的回复可能仍然存在一些问题, 如不够流畅、不够贴切、缺乏逻辑等。
- 使用RLHF 提高对话质量
RLHF的核心思想是让模型根据人类对其生成回复的反馈(奖励)来学习和改进其行为策略。
具体来说, RLHF的过程如下:
- 收集一批SFT模型生成的回复样本, 并让人类对每个回复打分(如按相关性、流畅度、逻辑性等维度)。
- 训练一个奖励模型, 用于根据对话历史和回复内容预测人类的评分。这个奖励模型本质上是一个回归模型, 可以用人类打分的样本进行监督学习。
- 使用奖励模型对SFT模型的生成过程进行引导。具体来说, 在生成每个词时, 我们使用奖励模型评估不同词选择对应的未来奖励, 并鼓励模型选择能获得更高奖励的词(通常使用策略梯度算法)。
- 重复步骤1-3,不断收集新的人类反馈数据, 优化奖励模型和对话模型, 直到对话质量满足要求。
通过RLHF, 对话模型可以学习到更加符合人类偏好的对话策略, 生成更加自然、贴切、有逻辑的回复。同时, RLHF也可以帮助模型学习避免生成不恰当、有害或偏见的内容。
- 模型部署和持续优化
经过SFT和RLHF优化的LLM聊天模型已经可以投入实际应用, 为用户提供智能对话服务。但我们的工作并没有就此结束, 还需要持续监控模型的性能, 收集用户反馈, 发现和解决存在的问题。
同时, 随着时间的推移, 用户的需求和偏好可能会发生变化, 新的话题和任务也会不断出现。因此, 我们需要持续收集新的对话数据, 定期对模型进行重新训练和优化, 以适应不断变化的应用环境。
此外, 我们还需要重视聊天模型的伦理性、安全性和可解释性。这需要在数据收集、模型训练、应用部署的各个环节进行全面考虑, 并与用户、社会各界保持积极沟通和互动。
4.2 特定领域SFT微调的流程
进行特定领域SFT微调通常包括以下几个关键步骤:
- 领域数据准备:
- 收集高质量的领域文本数据, 包括各种形式的结构化、半结构化和非结构化数据。
- 对原始数据进行清洗、脱敏,去除噪音、错误和敏感信息。
- 根据任务需求, 将数据标注为特定的输入输出格式, 如问答对、摘要对、翻译对等。
- 微调样本构建:
- 根据LLM的特点和领域任务的要求, 设计输入输出的样本格式和提示模板。
- 利用领域知识图谱、行业规范文档等, 丰富输入样本的背景信息和约束条件。
- 将格式统一的输入输出样本整理为可直接用于微调的数据集。
- 微调策略设计:
- 选择一个与领域任务相近的通用LLM作为初始化模型, 以提高微调的效率和效果。
- 设计微调的目标函数, 除了基本的语言建模损失, 还可加入特定任务的评估指标。
- 确定微调的超参数, 如学习率、BatchSize、训练轮数等, 以平衡性能和成本。
- 模型微调训练:
- 利用构建好的微调样本集, 在初始化的LLM上进行梯度下降训练。
- 动态调整超参数, 监控模型在验证集上的收敛情况。
- 对训练过程中的checkpoints进行测试, 选择性能最优的模型进行后续优化。
- 微调模型评估:
- 在独立的测试集上全面评估微调后的模型, 既要考察通用的语言质量, 也要重点评测领域任务的关键指标。
- 邀请领域专家对模型输出进行人工评审, 提供改进反馈。
- 针对评估结果, 有针对性地扩充数据、调整模型, 进行多轮迭代优化。
- 模型部署应用:
- 将微调优化后的模型部署到生产环境, 为特定领域任务提供智能辅助。
- 构建人机交互界面, 让领域用户可以方便地使用LLM的能力。持续收集用户反馈数据, 定期审核模型性能, 并根据领域知识的更新迭代模型。
4.3 LLM 微调方法
为了在不同的应用场景中高效地利用和优化LLM, 研究者们提出了多种训练方法, 包括Full-tuning、Freeze-tuning、LoRA(Low-Rank Adaptation)和QLoRA(Quantized Low-Rank Adaptation)。
4.3.1 Full-tuning(全量微调)
Full-tuning 是对预训练模型的所有参数进行全面调整,以适应特定的下游任务,流程如下:
- 加载预训练的LLM模型及其所有参数
- 在下游任务的训练数据上,使用任务特定的损失函数(如交叉熵、平方损失等)对模型进行端到端的微调。
- 所有模型参数都得到更新,以最小化任务损失。
- 微调后的模型可以直接应用于目标任务的推理。
Full-tuning的优势在于其灵活性和表现力。通过调整所有参数, 模型可以充分适应目标任务的特点,学习任务特定的知识和模式。这种全面的微调通常能够取得较好的性能表现。
Full-tuning也存在一些局限性:
1. 它需要大量的计算资源和时间成本。对于大型LLM,全参数微调需要训练数亿甚至上千亿个参数,对计算设备提出了很高的要求。
2. Full-tuning可能面临过拟合的风险。当下游任务的训练数据有限时, 全参数微调可能过度适应训练集的特点, 导致在测试集上泛化能力下降。
4.3.2 Freeze-tuning(冻结部分参数微调)
Freeze-tuning 与 Full-tuning不同, Freeze-tuning只调整模型的一部分参数, 而将其余参数”冻结”为预训练的初始值。
通常, Freeze-tuning只微调LLM的最后一层或几层, 而保持底层的表示学习层不变。流程如下:
- 加载预训练的LLM模型及其参数。
- 选择要微调的顶层(如最后一个Transformer块), 并解冻其参数。
- 冻结其余底层的参数, 使其保持预训练的初始值不变。
- 在下游任务的训练数据上, 只对解冻的顶层参数进行微调, 以最小化任务损失。
Freeze-tuning的优势在于 计算效率 和 泛化能力。:
- 由于只微调部分参数, Freeze-tuning大大减少了训练时间和资源消耗。
- 冻结底层参数有助于保留预训练模型学到的通用语言知识, 降低过拟合风险, 提高模型在下游任务上的泛化表现。
Freeze-tuning的表现力相对有限:
- 由于大部分参数被冻结, 模型的适应能力受到限制, 可能难以充分捕捉目标任务的特定模式。
- 在数据充足、任务复杂度高的场景下, Freeze-tuning可能难以达到Full-tuning的性能水平。
4.3.3 LoRA 低秩适应的参数高效微调
LoRA(Low-Rank Adaptation) 与Freeze-tuning固定底层参数不同, LoRA在每个Transformer层中引入了一组低秩分解矩阵, 并只训练这些新增的低秩矩阵, 而保持原有的预训练权重不变。
LoRA的流程如下:
- 加载预训练的LLM模型及其参数。
- 在每个Transformer层的自注意力机制和前馈神经网络模块中, 并行地插入一组低秩分解矩阵(秩 r<<d,d为隐藏层维度)。
- 冻结预训练模型的所有原有权重, 只微调新增的低秩矩阵。
- 在前向传播时,将低秩矩阵与原有权重相乘, 得到适应后的隐藏层表示。
LoRA的核心思想是, 通过少量的额外参数(低秩矩阵)来捕捉下游任务的特定模式, 而不改变预训练权重。
这种方法大大减少了可训练参数的数量(比Full-tuning少2-3个数量级), 显著提高了训练效率。同时, 通过冻结预训练权重, LoRA在很大程度上保留了原有模型的泛化能力, 降低了过拟合风险。
4.3.4 QLoRA:低秩适应的量化优化
QLoRA(Quantized Low-Rank Adaptation)是LoRA的一种量化优化变体。QLoRA 的核心思想是在应用 LoRA 进行模型调优之前, 先对预训练的基础模型进行量化。
量化是一种将模型参数从高精度浮点数转换为低精度整数的技术, 可以在保持模型性能的同时, 大幅降低模型的存储和计算开销。
QLoRA 的训练过程可以分为以下几个步骤:
- 对基础模型进行量化:使用量化技术, 如整数量化或二值化, 将预训练模型的权重从浮点数转换为低精度整数。这一步可以显著减小模型的体积和内存占用。
- 在量化模型上应用 LoRA:在量化后的基础模型上, 通过添加低秩矩阵对模型进行微调。这一步与标准的 LoRA 类似, 通过训练额外的低秩矩阵来适应特定任务, 而无需调整原始模型的权重。
- 训练和部署:使用任务特定的数据对 LoRA 矩阵进行训练, 得到适应后的模型。在推理阶段, 量化后的基础模型和训练好的 LoRA 矩阵可以高效地结合, 以生成所需的输出。
QLoRA 结合了量化和参数高效微调的优点,具有以下特点:
- 显著减小模型体积:通过量化技术,QLoRA 可以将基础模型的体积减小到原来的几分之一, 甚至更小。这使得 QLoRA 模型更容易存储和部署在资源受限的设备上。
- 加速推理:量化后的模型可以使用整数运算, 而整数运算通常比浮点运算更快。因此, QLoRA 模型在推理阶段可以获得显著的加速。
- 参数高效:与标准的微调方法相比,QLoRA 只需训练额外的低秩矩阵, 而不需要调整整个模型的参数。这使得 QLoRA 的参数开销非常小, 非常适合在参数量受限的情况下进行模型调优。
4.3.5 总结
Full-tuning、Freeze-tuning、LoRA和QLoRA代表了LLM训练的不同思路和方法。它们在参数效率、计算成本、性能表现等方面各有优劣,适用于不同的任务场景和资源限制。
- Full-tuning是最传统、最灵活的微调方法, 通过调整所有参数来充分适应下游任务, 但计算成本高,过拟合风险大。
- Freeze-tuning通过冻结底层参数, 在减少计算开销的同时保留了预训练知识, 提高了泛化能力, 但表现力有限
- LoRA通过引入少量低秩分解矩阵, 在保留预训练权重的同时高效地适应下游任务, 取得了参数效率和性能的良好平衡
- QLoRA在LoRA的基础上进行量化优化, 进一步压缩模型尺寸, 加速计算过程,特别适用于资源受限场景
6 大模型开发工具库-Transformers
Transformers Notebooks:https://huggingface.co/docs/transformers/notebooks
6.1 Transformers 核心模块
6.1.1 Pipelines
Pipelines(管道)是使用模型进行推理的一种简单易上手的方式。
这些管道是抽象了 Transformers 库中大部分复杂代码的对象,提供了一个专门用于多种任务的简单API,包括命名实体识别、掩码语言建模、情感分析、特征提取和问答等。
| Modality | Task | Description | Pipeline API |
|---|---|---|---|
| Audio | Audio classification | 为音频文件分配一个标签 | pipeline(task=“audio-classification”) |
| Automatic speech recognition | 将音频文件中的语音提取为文本 | pipeline(task=“automatic-speech-recognition”) | |
| Computer vision | Image classification | 为图像分配一个标签 | pipeline(task=“image-classification”) |
| Object detection | 预测图像中目标对象的边界框和类别 | pipeline(task=“object-detection”) | |
| Image segmentation | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | pipeline(task=“image-segmentation”) | |
| Natural language processing | Text classification | 为给定的文本序列分配一个标签 | pipeline(task=“sentiment-analysis”) |
| Token classification | 为序列里的每个 token 分配一个标签(人, 组织, 地址等等) | pipeline(task=“ner”) | |
| Question answering | 通过给定的上下文和问题, 在文本中提取答案 | pipeline(task=“question-answering”) | |
| Summarization | 为文本序列或文档生成总结 | pipeline(task=“summarization”) | |
| Translation | 将文本从一种语言翻译为另一种语言 | pipeline(task=“translation”) | |
| Multimodal | Document question answering | 根据给定的文档和问题回答一个关于该文档的问题。 | pipeline(task=“document-question-answering”) |
| Visual Question Answering | 给定一个图像和一个问题,正确地回答有关图像的问题 | pipeline(task=“vqa”) |
Pipelines 已支持的完整任务列表:https://huggingface.co/docs/transformers/task_summary
Pipeline API 是对所有其他可用管道的包装。它可以像任何其他管道一样实例化,并且降低AI推理的学习和使用成本。
- 使用Pipeline API 实现 Text Classification 任务
Text classification(文本分类)与任何模态中的分类任务一样,文本分类将一个文本序列(可以是句子级别、段落或者整篇文章)标记为预定义的类别集合之一。文本分类有许多实际应用,其中包括:
- 情感分析:根据某种极性(如积极或消极)对文本进行标记,以在政治、金融和市场等领域支持决策制定。
- 内容分类:根据某个主题对文本进行标记,以帮助组织和过滤新闻和社交媒体信息流中的信息(天气、体育、金融等)。
下面以 Text classification 中的情感分析任务为例,展示如何使用 Pipeline API。
模型主页:https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english
在transformers自定义模型下载的路径:
1 | import os |
加载对应的模型:
1 | from transformers import pipeline |
使用模型进行推理:
1 | pipe("You learn things really quickly. You understand the theory class as soon as it is taught.") |
- 使用 Pipelines 实现智能问答
Question Answering(问答)是另一个token-level的任务,返回一个问题的答案,有时带有上下文(开放领域),有时不带上下文(封闭领域)。每当我们向虚拟助手提出问题时,例如询问一家餐厅是否营业,就会发生这种情况。它还可以提供客户或技术支持,并帮助搜索引擎检索您要求的相关信息。
有两种常见的问答类型:
- 提取式:给定一个问题和一些上下文,模型必须从上下文中提取出一段文字作为答案
- 生成式:给定一个问题和一些上下文,答案是根据上下文生成的;这种方法由
Text2TextGenerationPipeline处理,而不是下面展示的QuestionAnsweringPipeline
模型主页:https://huggingface.co/distilbert-base-cased-distilled-squad
1 | from transformers import pipeline |
- 使用 Pipelines 实现语音识别
Audio classification(音频分类)是一项将音频数据从预定义的类别集合中进行标记的任务。这是一个广泛的类别,具有许多具体的应用,其中一些包括:
- 声学场景分类:使用场景标签(“办公室”、“海滩”、“体育场”)对音频进行标记。
- 声学事件检测:使用声音事件标签(“汽车喇叭声”、“鲸鱼叫声”、“玻璃破碎声”)对音频进行标记。
- 标记:对包含多种声音的音频进行标记(鸟鸣、会议中的说话人识别)。
- 音乐分类:使用流派标签(“金属”、“嘻哈”、“乡村”)对音乐进行标记。
模型主页:https://huggingface.co/superb/hubert-base-superb-er
数据集主页:https://huggingface.co/datasets/superb#er
情感识别(ER)为每个话语预测一个情感类别。我们采用了最广泛使用的ER数据集IEMOCAP,并遵循传统的评估协议:我们删除不平衡的情感类别,只保留最后四个具有相似数量数据点的类别,并在标准分割的五折交叉验证上进行评估。评估指标是准确率(ACC)。
依赖必要的音频处理数据包:ffmpeg
1 | apt update & apt upgrade |
1 | from transformers import pipeline |
Automatic speech recognition(自动语音识别)将语音转录为文本。这是最常见的音频任务之一,部分原因是因为语音是人类交流的自然形式。如今,ASR系统嵌入在智能技术产品中,如扬声器、电话和汽车。我们可以要求虚拟助手播放音乐、设置提醒和告诉我们天气。
但是,Transformer架构帮助解决的一个关键挑战是低资源语言。通过在大量语音数据上进行预训练,仅在一个低资源语言的一小时标记语音数据上进行微调,仍然可以产生与以前在100倍更多标记数据上训练的ASR系统相比高质量的结果。
模型主页:https://huggingface.co/openai/whisper-small
下面展示使用 OpenAI Whisper Small 模型实现 ASR 的 Pipeline API 示例:
1 | from transformers import pipeline |
6.1.2 使用 AutoClass 管理 Tokenizer 和 Model
实际上,在 Transformers 库内部实现中,Pipeline 作为管理:原始文本-输入Token IDs-模型推理-输出概率-生成结果 的流水线抽象,背后串联了 Transformers 库的核心模块 Tokenizer和 Models。
Piplines 运行原理: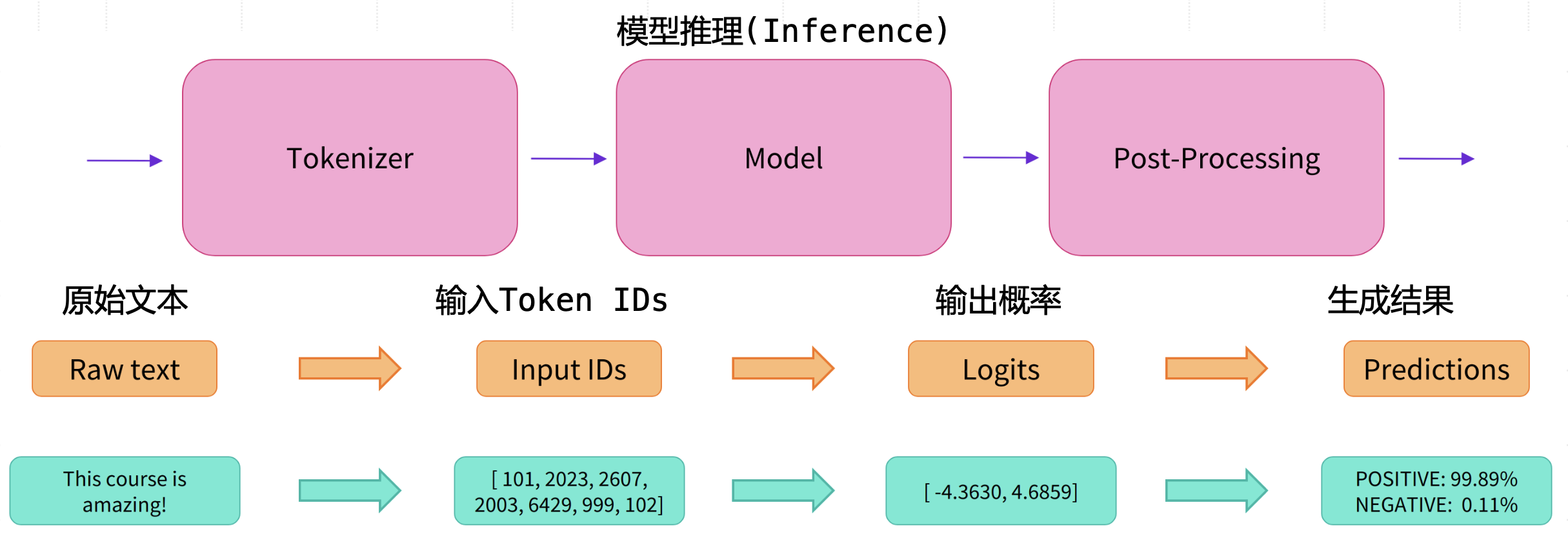
通常,想要使用的模型(网络架构)可以从提供给 from_pretrained() 方法的预训练模型的名称或路径中推测出来。
AutoClasses就是为了帮助用户完成这个工作,以便根据预训练权重/配置文件/词汇表的名称/路径自动检索相关模型。
比如手动加载bert-base-chinese模型以及对应的 tokenizer 方法如下:
1 | from transformers import AutoTokenizer, AutoModel |
- 使用 BERT Tokenizer 编码文本
编码 (Encoding) 过程包含两个步骤:
- 分词:使用分词器按某种策略将文本切分为 tokens;
- 映射:将 tokens 转化为对应的 token IDs。
1 | # 第一步:分词 |
- 使用 Tokenizer.encode 方法端到端处理
1 | token_ids_e2e = tokenizer.encode(sequence) |
- 编解码多段文本
1 | sequence_batch = ["美国的首都是华盛顿特区", "中国的首都是北京"] |
- 直接使用
tokenizer.__call__方法完成文本编码 + 特殊编码补全1
2
3embedding_batch = tokenizer("美国的首都是华盛顿特区", "中国的首都是北京")
print(embedding_batch)
# {'input_ids': [101, 5401, 1744, 4638, 7674, 6963, 3221, 1290, 4670, 7561, 4294, 1277, 102, 704, 1744, 4638, 7674, 6963, 3221, 1266, 776, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
- input_ids: token_ids
- token_type_ids: token_id 归属的句子编号
- attention_mask: 指示哪些token需要被关注(注意力机制)
1 | # 优化下输出结构 |
1 | input_ids: [101, 5401, 1744, 4638, 7674, 6963, 3221, 1290, 4670, 7561, 4294, 1277, 102, 704, 1744, 4638, 7674, 6963, 3221, 1266, 776, 102] |
- 添加新 Token
当出现了词表或嵌入空间中不存在的新Token,需要使用 Tokenizer 将其添加到词表中。 Transformers 库提供了两种不同方法:
- add_tokens: 添加常规的正文文本 Token,以追加(append)的方式添加到词表末尾。
- add_special_tokens: 添加特殊用途的 Token,优先在已有特殊词表中选择(
bos_token, eos_token, unk_token, sep_token, pad_token, cls_token, mask_token)。如果预定义均不满足,则都添加到additional_special_tokens。
先查看已有词表,确保新添加的 Token 不在词表中:
1 | len(tokenizer.vocab.keys) # 21128 |
- 添加特殊 Token
1 | new_special_token = {"sep_token": "NEW_SPECIAL_TOKEN"} |
- 使用
save_pretrained方法保存指定 Model 和 Tokenizer
借助 AutoClass 的设计理念,保存 Model 和 Tokenizer 的方法也相当高效便捷。
假设我们对bert-base-chinese模型以及对应的 tokenizer 做了修改,并更名为new-bert-base-chinese,方法如下:
1 | tokenizer.save_pretrained("./models/new-bert-base-chinese") |
保存 Tokenizer 会在指定路径下创建以下文件:
- tokenizer.json: Tokenizer 元数据文件;
- special_tokens_map.json: 特殊字符映射关系配置文件;
- tokenizer_config.json: Tokenizer 基础配置文件,存储构建 Tokenizer 需要的参数;
- vocab.txt: 词表文件;
- added_tokens.json: 单独存放新增 Tokens 的配置文件。
保存 Model 会在指定路径下创建以下文件:
- config.json:模型配置文件,存储模型结构参数,例如 Transformer 层数、特征空间维度等;
- pytorch_model.bin:又称为 state dictionary,存储模型的权重。
1 | tokenizer.save_pretrained("./models/new-bert-base-chinese") |
1 | ('./models/new-bert-base-chinese/tokenizer_config.json', |
6.2 Transformers 微调训练
基于 Transformers 实现模型微调训练的主要流程,包括:
- 数据集下载
- 数据预处理
- 训练超参数配置
- 训练评估指标设置
- 训练器基本介绍
- 实战训练
- 模型保存
微调 BERT 情感分类:https://github.com/DjangoPeng/LLM-quickstart/blob/main/transformers/fine-tune-quickstart.ipynb
微调语言模型-问答任务:https://github.com/DjangoPeng/LLM-quickstart/blob/main/transformers/fine-tune-QA.ipynb
6.2.1 数据集处理库 Datasets
Datasets 解决数据来源问题,可以快速准备好数据集以进行深度学习模型的训练。
datasets.load_dataset 实现原理:
如果您想向数据集添加额外的属性,例如类别标签。有两种方法来填充BuilderConfig类或其子类的属性
- 在datasets DatasetBuilder.BUILDER_CONFIGS()属性中提供预定义的BuilderConfig类(或子类)实例列表。
- 当调用load_dataset()时,各参数默认值会直接读取 BuilderConfig 类的预定义值,否则会被覆盖。
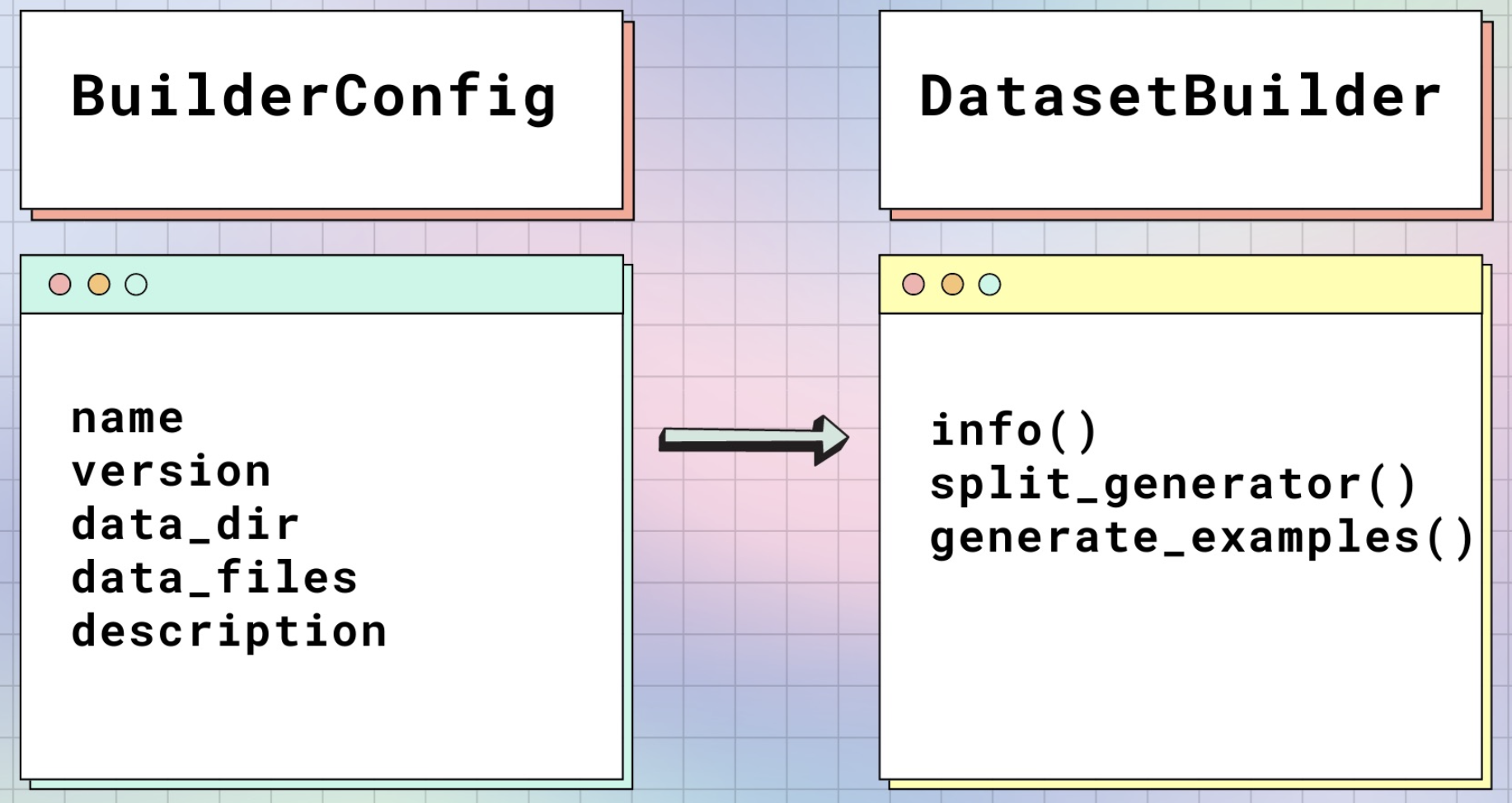
实际构造数据集的类 DatasetBuilder: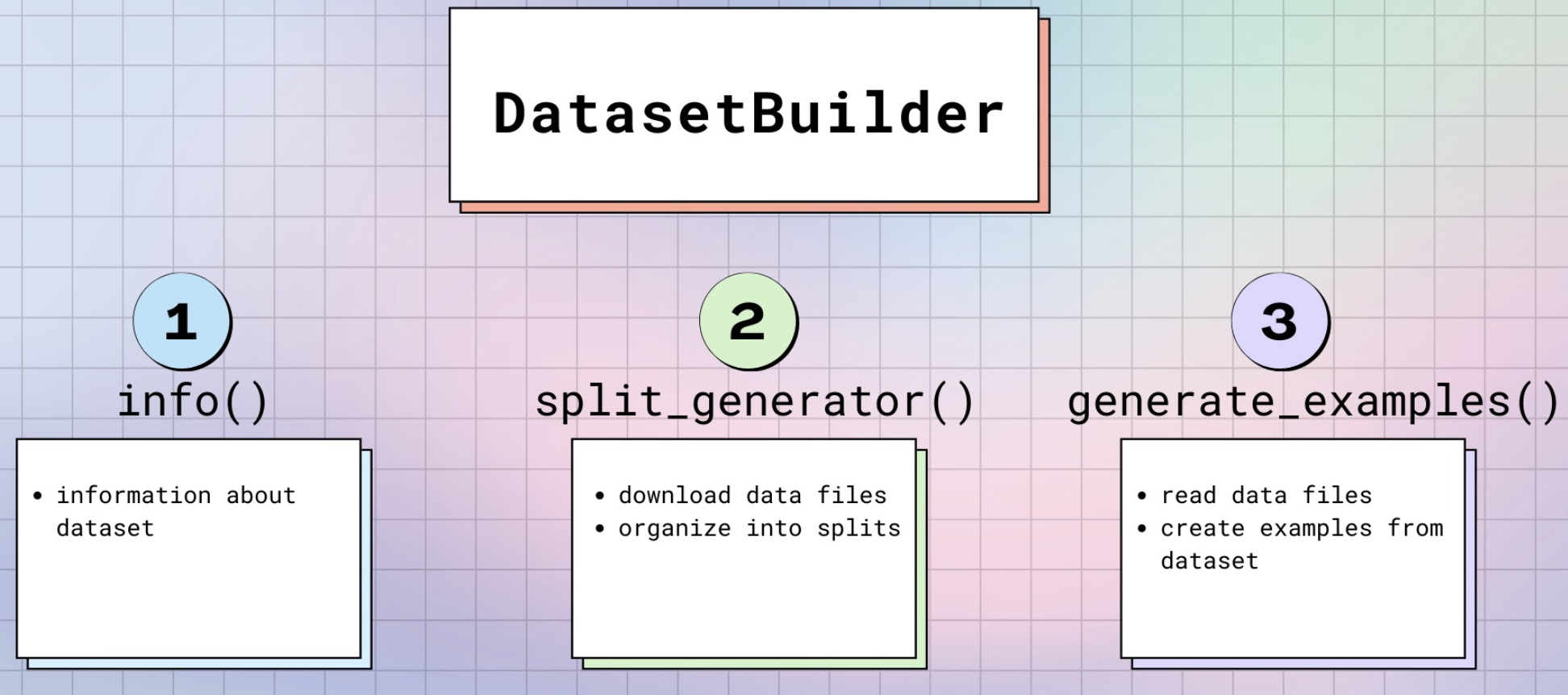
下载数据集:
Yelp评论数据集包括来自Yelp的评论。它是从Yelp Dataset Challenge 2015数据中提取的。
支持的任务和排行榜:文本分类、情感分类:该数据集主要用于文本分类:给定文本,预测情感。
1 | from datasets import load_dataset |
输出:
1 | DatasetDict({ |
1 | dataset["train"][111] |
1 | {'label': 2, |
数据展示工具:
1 | import random |

6.2.2 预处理数据
下载数据集到本地后,使用 Tokenizer 来处理文本,对于长度不等的输入数据,可以使用填充(padding)和截断(truncation)策略来处理。
Datasets 的 map 方法,支持一次性在整个数据集上应用预处理函数。
下面使用填充到最大长度的策略,处理整个数据集:
1 | from transformers import AutoTokenizer |


数据抽样:
使用 1000 个数据样本,在 BERT 上演示小规模训练(基于 Pytorch Trainer)shuffle()函数会随机重新排列列的值。如果您希望对用于洗牌数据集的算法有更多控制,可以在此函数中指定generator参数来使用不同的numpy.random.Generator。
1 | small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000)) |
6.2.3 微调训练配置
- 加载 BERT 模型
警告通知我们正在丢弃一些权重(vocab_transform 和 vocab_layer_norm 层),并随机初始化其他一些权重(pre_classifier 和 classifier 层)。在微调模型情况下是绝对正常的,因为我们正在删除用于预训练模型的掩码语言建模任务的头部,并用一个新的头部替换它,对于这个新头部,我们没有预训练的权重,所以库会警告我们在用它进行推理之前应该对这个模型进行微调,而这正是我们要做的事情。
1 | from transformers import AutoModelForSequenceClassification |
上边输出如下告警:
1 | Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias'] |
- 训练超参数(TrainingArguments)
源代码定义:https://github.com/huggingface/transformers/blob/v4.36.1/src/transformers/training_args.py#L161
最重要配置:模型权重保存路径(output_dir)
1 | from transformers import TrainingArguments |
1 | TrainingArguments( |
- 训练过程中的指标评估(Evaluate)
Hugging Face Evaluate 库 支持使用一行代码,获得数十种不同领域(自然语言处理、计算机视觉、强化学习等)的评估方法。 当前支持 完整评估指标:https://huggingface.co/evaluate-metric
训练器(Trainer)在训练过程中不会自动评估模型性能。因此,我们需要向训练器传递一个函数来计算和报告指标。
Evaluate库提供了一个简单的准确率函数,您可以使用evaluate.load函数加载
1 | import numpy as np |
接着,调用 compute 函数来计算预测的准确率。
在将预测传递给 compute 函数之前,我们需要将 logits 转换为预测值(所有Transformers 模型都返回 logits)。
1 | def compute_metrics(eval_pred): |
- 训练过程中指标监控
通常,为了监控训练过程中的评估指标变化,我们可以在TrainingArguments指定evaluation_strategy参数,以便在 epoch 结束时报告评估指标。
1 | from transformers import TrainingArguments, Trainer |
6.2.4 微调训练模块 Trainer
完成了以上的配置后,可以执行 Trainer 进行训练:
1 | trainer = Trainer( |

因为数据集只有 1000,约6分钟训练完成。
训练过程中可以使用 nvidia-smi 查看 GPU 使用:
为了实时查看GPU使用情况,可以使用 watch 指令实现轮询:watch -n 1 nvidia-smi:
1 | Every 1.0s: nvidia-smi Wed Dec 20 14:37:41 2023 |
1 | small_test_dataset = tokenized_datasets["test"].shuffle(seed=64).select(range(100)) |
1 | {'eval_loss': 1.0753791332244873, |
6.2.5 保存模型和训练状态
- 使用
trainer.save_model方法保存模型,后续可以通过 from_pretrained() 方法重新加载 - 使用
trainer.save_state方法保存训练状态
1 | trainer.save_model(model_dir) |