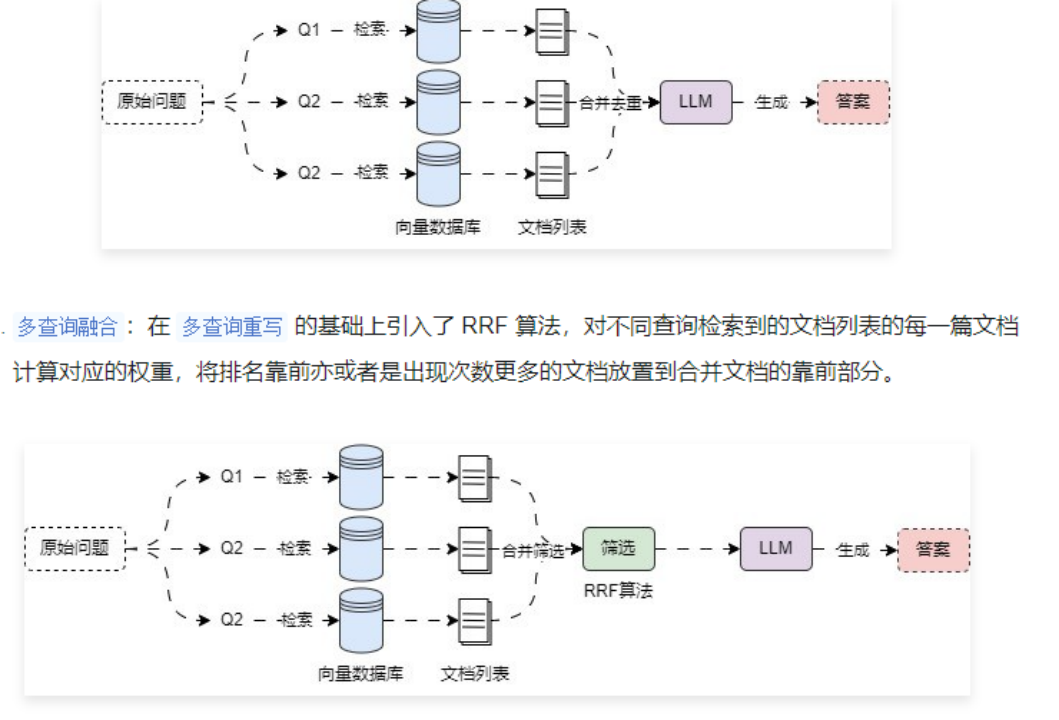
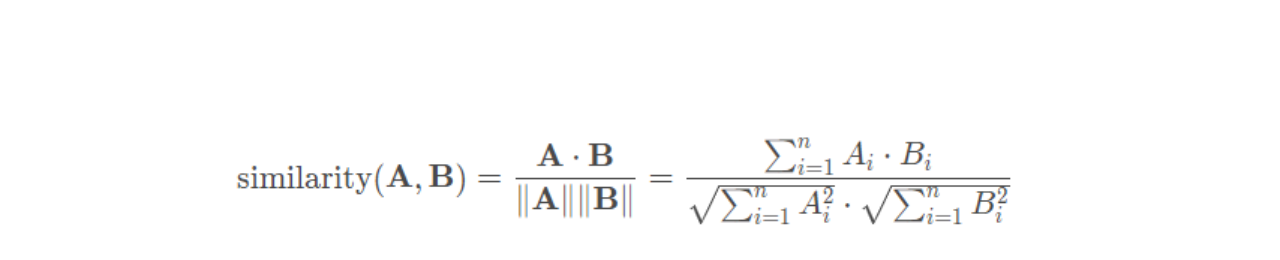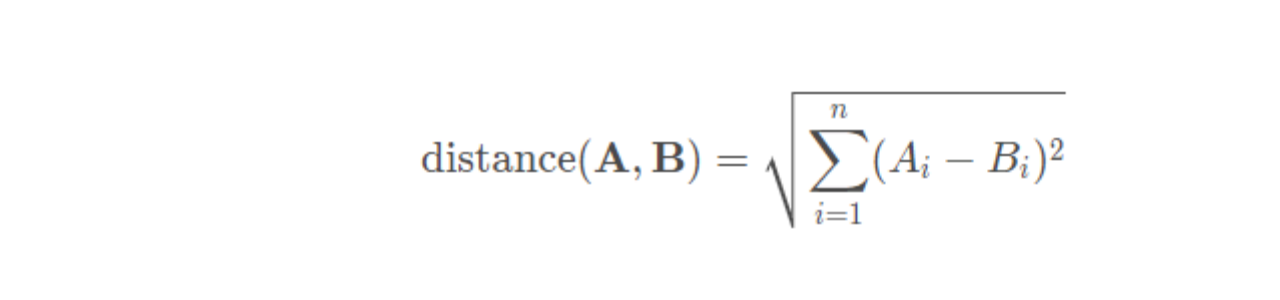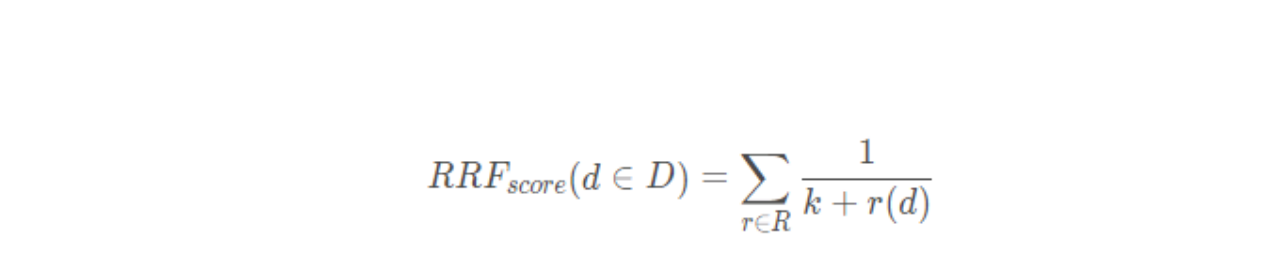1 向量数据库 1.1 向量数据库简介 向量数据库就是一种专门用于存储和处理向量数据的数据库系统,传统的关系型数据库通常不擅长处理向量数据,因为它们需要将数据映射为结构化的表格形式,而向量数据的维度较高、结构复杂,导致传统数据库存储和查询效率低下 ,所以向量数据库应运而生。
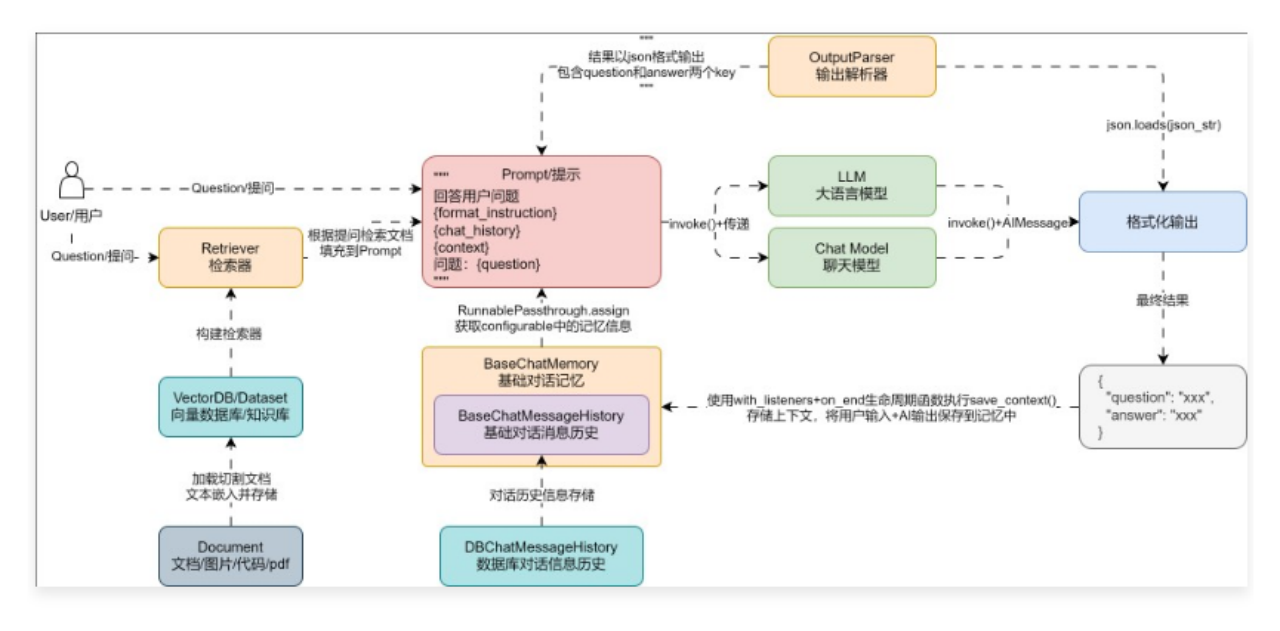
1.2 传统数据库与向量数据库的差异 传统数据库采用基于行的存储方式,传统数据库将数据存储为行记录,每一行包含多个字段,并且每个字段都有固定的列。传统数据库通常使用索引来提高查询性能,例如下方就是一个典型的传统数据库表格
这种方式在处理结构化数据时非常高效,但在处理非结构化或半结构化数据时效率低下。
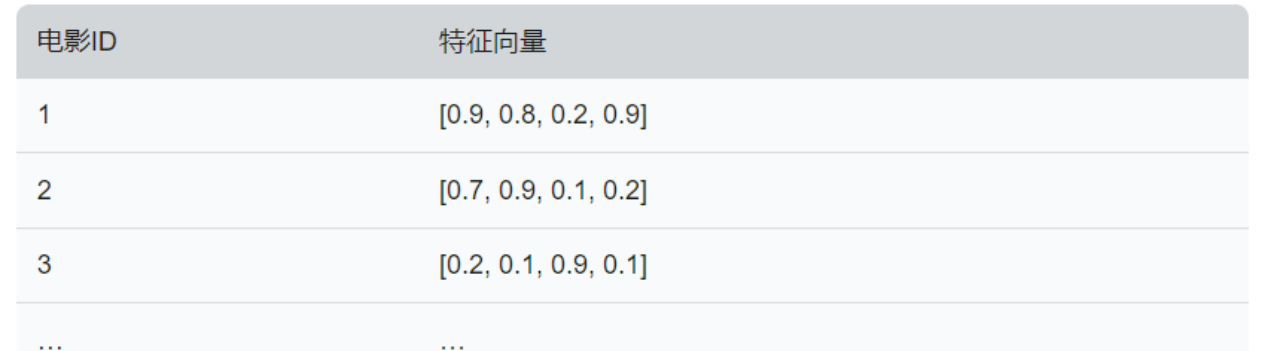
向量数据库将数据以列形式存储,即每个列都有一个独立的存储空间,这使得向量数据库可以更加灵活地处理复杂的数据结构。向量数据库还可以进行列压缩(稀疏矩阵 ),以减少存储空间和提高数据的访问速度。高维向量 ,其中每个向量对应于数据点 。这些向量之间的距离表示它们之间的相似性 。这种方式使得非结构化或半结构化数据的存储和检索变得更加高效。
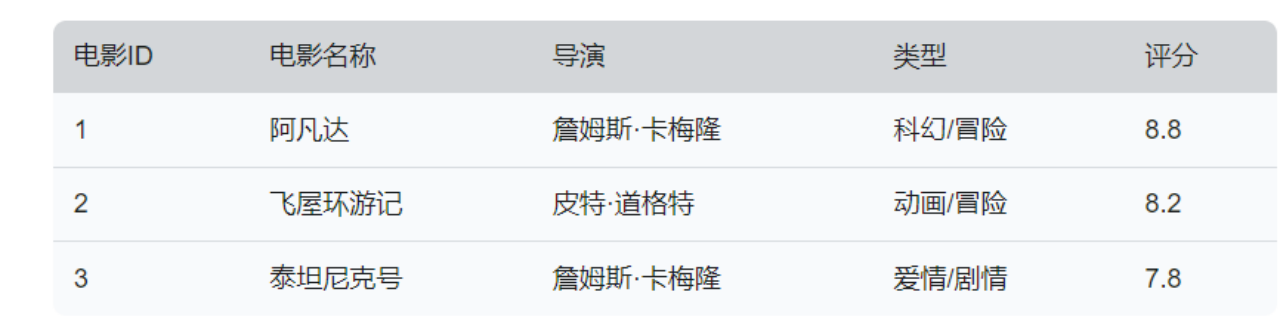
以电影数据库为例,我们可以将每部电影表示为一个特征向量。假设我们使用四个特征来描述每部电影:动作、冒险、爱情、科幻 。每个特征都可以在0到1的范围内进行标准化,表示该电影在该特征上的强度。
例如,电影”阿凡达”的向量表示可以是 [0.9, 0.8, 0.2, 0.9],其中数字分别表示动作、冒险、爱情、科幻的特征强度。其他电影也可以用类似的方式表示。这些向量可以存储在向量数据库中,如下所示:
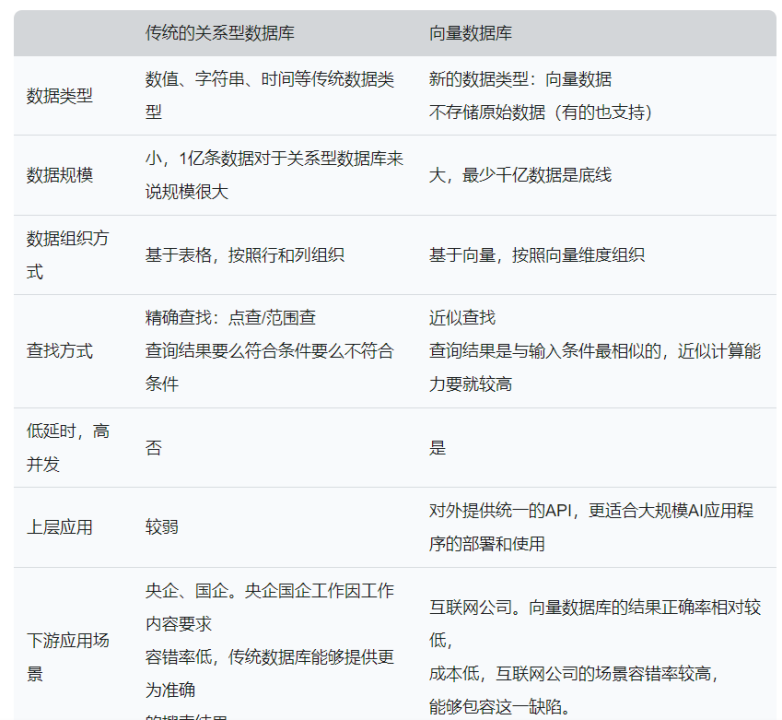
1.3 传统数据库与向量数据库优缺点
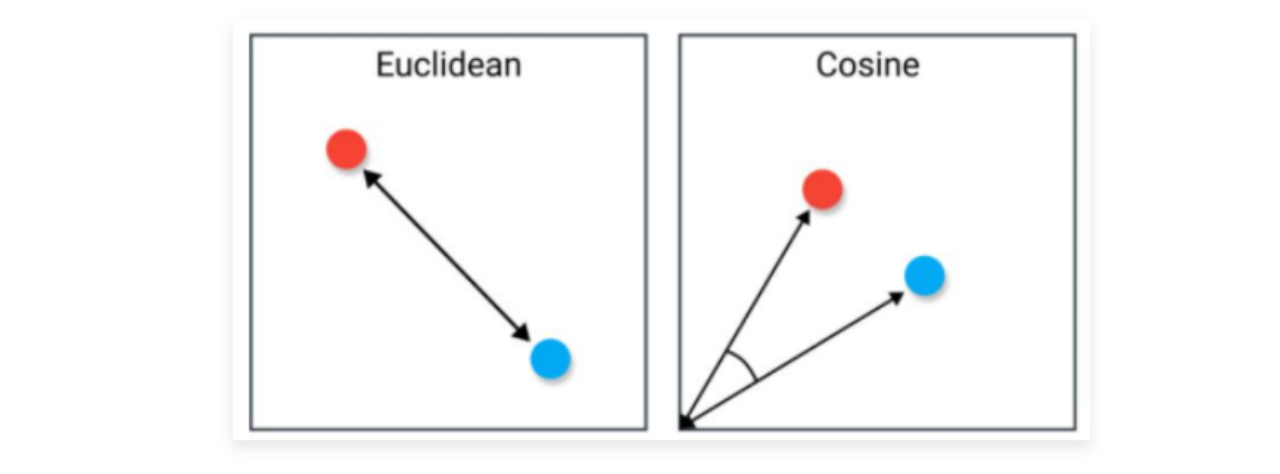
1.4 相似度搜索算法 1.4.1 余弦相似度与欧氏距离 在向量数据库中,支持通过多种方式来计算两个向量的相似度,例如:余弦相似度、欧式距离、曼哈顿距离、闵可夫斯基距离、汉明距离、Jaccard相似度 等多种。其中最常见的就是 余弦相似度 和 欧式距离。
余弦相似度主要用于衡量向量在方向上的相似性,特别适用于文本、图像和高维空间中的向量。它不受向量长度的影响,只考虑方向的相似程度,余弦相似度的计算公式如下(计算两个向量夹角的余弦值,取值范围为[-1, 1]):
欧式距离衡量向量之间的直线距离,得到的值可能很大,最小为 0,通常用于低维空间或需要考虑向量各个维度之间差异的情况。欧氏距离较小的向量被认为更相似,欧式距离的计算公式如下:
1.4.2 相似性搜索加速算法 在向量数据库中,数据按列进行存储,通常会将多个向量组织成一个 M×N 的矩阵,其中 M 是向量的维度(特征数),N 是向量的数量(数据库中的条目数),这个矩阵可以是稠密或者稀疏的,取决于向量的稀疏性和具体的存储优化策略。
这样计算相似性搜索时,本质上就变成了向量与 M×N 矩阵的每一行进行相似度计算,这里可以用到大量成熟的加速算法:
1. 矩阵分解方法 :
· SVD(奇异值分解) :可以通过奇异值分解将原始矩阵转换为更低秩的矩阵表示,从而减少计算量。PCA(主成分分析) :类似地,可以通过主成分分析将高维矩阵映射到低维空间,减少计算复杂度。
索引结构和近似算法 :
· LSH(局部敏感哈希) :LSH 可以在近似相似度匹配中加速计算,特别适用于高维稀疏向量的情况。ANN(近似最近邻)算法 :ANN 算法如KD-Tree、Ball-Tree等可以用来加速对最近邻搜索的计算,虽然主要用于向量空间,但也可以部分应用于相似度计算中。
GPU 加速 :使用图形处理单元(GPU)进行并行计算可以显著提高相似度计算的速度,尤其是对于大规模数据和高维度向量。分布式计算 :由于行与行之间独立,所以可以很便捷地支持分布式计算每行与向量的相似度,从而加速整体计算过程。
向量数据库底层除了在算法层面上针对相似性搜索做了大量优化,在存储结构、索引机制等方面均做了大量的优化,这才使得向量数据库在处理高维数据和实现快速相似性搜索上展示出巨大的优势
1.5 向量数据库的配置和使用 按照部署方式和提供的服务类型进行划分,向量数据库可以划分成几种:本地文件向量数据库 :用户将向量数据存储到本地文件系统中,通过数据库查询的接口来检索向量数据,例如:Faiss 。本地部署 API 向量数据库 :这类数据库不仅允许本地部署,而且提供了方便的 API 接口,使用户可以通过网络请求来访问和查询向量数据,这类数据库通常提供了更复杂的功能和管理选项,例如:Milvus、Annoy、Weaviate 等。云端 API 向量数据库 :将向量数据存储在云端,通过 API 提供向量数据的访问和管理功能,例如:TCVectorDB、Pinecone 等。
1.5.1 Faiss 向量数据库 1.5.1.1 Faiss 基本使用 Faiss 是 Facebook 团队开源的向量检索工具,针对高维空间的海量数据,提供高效可靠的相似性检索方式,被广泛用于推荐系统、图片和视频搜索等业务。Faiss 支持 Linux、macOS 和 Windows 操作系统,在百万级向量的相似性检索表现中,Faiss 能实现 < 10ms 的响应(需牺牲搜索准确度)。
GPU环境下使用并且已经安装了CUDA,则可以使用GPU版本
代码示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import dotenv from langchain_community.vectorstores import FAISS from langchain_huggingface import HuggingFaceEmbeddings dotenv.load_dotenv() embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L12-v2" , cache_folder="../22-其他Embedding嵌入模型的配置与使用/embeddings/" ) db = FAISS.load_local("vector-store/" , embeddings, allow_dangerous_deserialization=True ) print (db.similarity_search_with_score("我养了一只猫,叫笨笨" ))
1.5.1.2 删除指定数据 在 Faiss 中,支持删除向量数据库中特定的数据,目前仅支持传入数据条目 id 进行删除,并不支持条件筛选(但是可以通过条件筛选找到符合的数据,然后提取 id 列表,然后批量删除)。
代码示例:
1 2 3 4 print ("删除前数量:" , db.index.ntotal)db.delete([db.index_to_docstore_id[0 ]]) print ("删除后数量:" , db.index.ntotal)
输出结果:
1.5.1.3 带过滤的相似性搜索 在绝大部分向量数据库中,除了存储向量数据,还支持存储对应的元数据,这里的元数据可以是文本原文、扩展信息、页码、归属文档id、作者、创建时间 等等任何自定义信息,一般在向量数据库中,会通过元数据来实现对数据的检索。
1 向量数据库记录 = 向量(vector)+元数据(metadata)+id
Faiss 原生并不支持过滤,所以在 LangChain 封装的 FAISS 中对过滤功能进行了相应的处理。首先获取比 k 更多的结果 fetch_k(默认为 20 条),然后先进行搜索,接下来再搜索得到的 fetch_k 条结果上进行过滤,得到 k 条结果,从而实现带过滤的相似性搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import dotenv from langchain_community.vectorstores import FAISS from langchain_huggingface import HuggingFaceEmbeddings dotenv.load_dotenv() embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L12-v2" , cache_folder="../22-其他Embedding嵌入模型的配置与使用/embeddings/" ) metadatas: list = [ {"page" : 1 }, {"page" : 2 }, {"page" : 3 }, {"page" : 4 }, {"page" : 5 }, {"page" : 6 }, {"page" : 7 }, {"page" : 8 }, {"page" : 9 }, {"page" : 10 }, ] db = FAISS.from_texts([ "笨笨是一只很喜欢睡觉的猫咪" , "我喜欢在夜晚听音乐,这让我感到放松。" , "猫咪在窗台上打盹,看起来非常可爱。" , "学习新技能是每个人都应该追求的目标。" , "我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , "昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , "我的手机突然关机了,让我有些焦虑。" , "阅读是我每天都会做的事情,我觉得很充实。" , "他们一起计划了一次周末的野餐,希望天气能好。" , "我的狗喜欢追逐球,看起来非常开心。" , ], embeddings, metadatas) print (db.index_to_docstore_id) print (db.similarity_search_with_score("我养了一只猫,叫笨笨" , filter =lambda x: x["page" ] > 5 ))
1.5.2 Pinecone 向量数据库 1.5.2.1 Pinecone 配置 Pinecone 是一个托管的、云原生的向量数据库,具有极简的 API,并且无需在本地部署即可快速使用,Pinecone 服务提供商还为每个账户设置了足够的免费空间,在开发阶段,可以快速基于 Pinecone 快速开发 AI 应用 。https://www.pinecone.io/ https://www.pinecone-io.com/ http://imooc-langchain.shortvar.com/docs/integrations/vectorstores/pinecone/
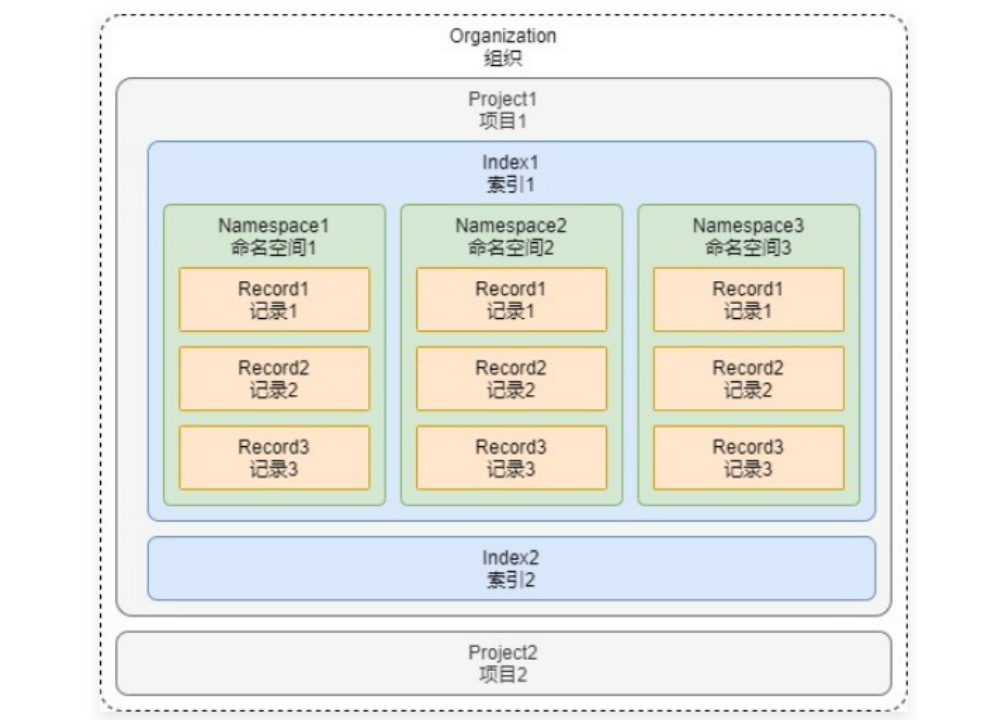
概念的解释如下:组织 :组织是使用相同结算方式的一个或者多个项目的集合,例如个人账号、公司账号等都算是一个组织。项目 :项目是用来管理向量数据库、索引、硬件资源等内容的整合,可以将不同的项目数据进行区分。索引 :索引是 Pinecone 中数据的最高组织单位,在索引中需要定义向量的存储维度、查询时使用的相似性指标,并且在 Pinecone 中支持两种类型的索引:无服务器索引(根据数据大小自动扩容)和 Pod 索引(预设空间/硬件)。命名空间 :命名空间是索引内的分区,用于将索引中的数据区分成不同的组,以便于在不同的组内存储不同的数据,例如知识库、记忆的数据可以存储到不同的组中,类似 Excel 中的 Sheet表。记录 :记录是数据的基本单位,一条记录涵盖了 ID、向量(values)、元数据(metadata) 等。
所以在 Pinecone 中使用向量数据库,要确保 组织、项目、索引、命名空间、记录 等内容均配置好才可以使用,并且由于 Pinecone 是云端向量数据库,使用时还需配置对应的 API 秘钥(可在注册好 Pinecone 后管理页面的 API Key 中设置)。
1 pip install -U langchain-pinecone
然后在 .env 文件中配置对应的 API 秘钥,如下
1.5.2.2 Pinecone 使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import dotenv from langchain_pinecone import PineconeVectorStore from langchain_huggingface import HuggingFaceEmbeddings dotenv.load_dotenv() embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L12-v2" , cache_folder="../22-其他Embedding嵌入模型的配置与使用/embeddings/" ) texts: list = [ "笨笨是一只很喜欢睡觉的猫咪" , "我喜欢在夜晚听音乐,这让我感到放松。" , "猫咪在窗台上打盹,看起来非常可爱。" , "学习新技能是每个人都应该追求的目标。" , "我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , "昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , "我的手机突然关机了,让我有些焦虑。" , "阅读是我每天都会做的事情,我觉得很充实。" , "他们一起计划了一次周末的野餐,希望天气能好。" , "我的狗喜欢追逐球,看起来非常开心。" , ] metadatas: list = [ {"page" : 1 }, {"page" : 2 }, {"page" : 3 }, {"page" : 4 }, {"page" : 5 }, {"page" : 6 , "account_id" : 1 }, {"page" : 7 }, {"page" : 8 }, {"page" : 9 }, {"page" : 10 }, ] db = PineconeVectorStore(index_name="llmops" , embedding=embeddings, namespace="dataset" , pinecone_api_key="pcsk_Qz5bt_JMBCg1A6oJPbnceUnhwYf6CA1M57kBTxgVTDda96FkwCECAAhwPYrUvyytinYE2" ) db.add_texts(texts, metadatas, namespace="dataset" ) query = "我养了一只猫,叫笨笨" print (db.similarity_search_with_relevance_scores(query))
1.5.3 Weaviate 向量数据库 1.5.3.1 Weaviate 介绍 Weaviate 是完全使用 Go 语言构建的开源向量数据库,提供了强大的数据存储和检索功能。并且 Weaviate 提供了多种部署方式,以满足不同用户和用例的需求,部署方式如下:Weaviate 云 :使用 Weaviate 官方提供的云服务,支持数据复制、零停机更新、无缝扩容等功能,适用于评估、开发和生产场景。Docker 部署 :使用 Docker 容器部署 Weaviate 向量数据库,适用于评估和开发等场景。K8s 部署 :在 K8s 上部署 Weaviate 向量数据库,适用于开发和生产场景。
Weaviate 和 Pinecone/TCVectorDB 一样,也存在着集合的概念,在 Weaviate 中集合类似传统关系型数据库中的表,负责管理一类数据/数据对象,要使用 Weaviate 的流程其实也非常简单:
参考资料: https://weaviate.io/ https://weaviate.io/developers/weaviate/quickstart
LangChain Weaviate 集成包翻译文档:https://imooc-langchain.shortvar.com/docs/integrations/vectorstores/weaviate
1.5.3.2 Weaviate 向量数据库的使用 Docker 部署 Weaviate 向量数据库:
1 docker run -d --name weaviate-dev -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.24.20
创建好 Weaviate 数据库服务后,接下来就可以安装 Python 客户端/LangChain 集成包,命令如下:
1 pip install -Uqq langchain-weaviate
如果使用的是 Weaviate 云服务,可以直接从可视化界面创建 Collection,亦或者在使用时 LangChain 自动检测对应的数据集是否存在,如果不存在则直接创建。
代码示例 :
1 2 3 4 import weaviateclient = weaviate.connect_to_local("192.168.2.120" , "8080" )
连接到远程的 Weaviate 服务代码如下
1 2 3 4 5 6 import weaviatefrom weaviate.auth import AuthApiKeyclient = weaviate.connect_to_wcs( cluster_url="https://2j9jgyhprd2yej3c3rwog.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("BAn9bGZdZbdGCmUyfdegQoKFctyMmxaQdDFb" ) )
创建好客户端后,接下来可以基于客户端创建 LangChain 向量数据库实例,在实例化 LangChain VectorDB 时,需要传递 client(客户端)、 index_name(集合名字)、text(原始文本的存储键)、embedding(文本嵌入模型),如下
1 2 3 4 5 6 7 8 9 10 11 12 import dotenvimport weaviatefrom langchain_openai import OpenAIEmbeddingsfrom langchain_weaviate import WeaviateVectorStoredotenv.load_dotenv() client = weaviate.connect_to_local("192.168.2.120" , "8080" ) embedding = OpenAIEmbeddings(model="text-embedding-3-small" ) db = WeaviateVectorStore(client=client, index_name="DatasetTest" , text_key="text" , embedding=embedding)
实例化 LangChain VectorDB 后,就可以像 Faiss、Pinecone、TCVectorDB 一样去使用了,例如执行新增数据后完成检索示例如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import dotenvimport weaviatefrom langchain_openai import OpenAIEmbeddingsfrom langchain_weaviate import WeaviateVectorStoredotenv.load_dotenv() client = weaviate.connect_to_local("192.168.2.120" , "8080" ) embedding = OpenAIEmbeddings(model="text-embedding-3-small" ) db = WeaviateVectorStore(client=client, index_name="dataset-test" , text_key="text" , embedding=embedding) ids = db.add_texts([ "笨笨是一只很喜欢睡觉的猫咪" , "我喜欢在夜晚听音乐,这让我感到放松。" , "猫咪在窗台上打盹,看起来非常可爱。" , "学习新技能是每个人都应该追求的目标。" , "我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , "昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , "我的手机突然关机了,让我有些焦虑。" , "阅读是我每天都会做的事情,我觉得很充实。" , "他们一起计划了一次周末的野餐,希望天气能好。" , "我的狗喜欢追逐球,看起来非常开心。" , ]) print (db.similarity_search_with_score("笨笨" ))
输出内容:
在 Weaviate 中,也支持带过滤器的相似性筛选,并且 LangChain Weaviate 社区包并没有对筛选过滤器进行二次封装,所以直接传递原生的 weaviate 过滤器即可,参考文档:https://weaviate.io/developers/weaviate/search/filters
例如需要检索 page 属性大于等于 5 的所有数据,可以构建一个 filters 后传递给检索方法,如下:
1 2 3 from weaviate.classes.query import Filterfilters = Filter.by_property("page" ).greater_or_equal(5 ) print (db.similarity_search_with_score("笨笨" , filters=filters))
输出结果如下:
1 [(Document(page_content='我的狗喜欢追逐球,看起来非常开心。' , metadata={'page' : 10.0, 'account_id' : None}), 0.699999988079071), (Document(page_content='我的手机突然关机了,让我有些焦虑。' , metadata={'page' : 7.0, 'account_id' : None}), 0.4045487940311432), (Document(page_content='昨晚我做了一个奇怪的梦,梦见自己在太空飞行。' , metadata={'page' : 6.0, 'account_id' : 1.0}), 0.318904846906662), (Document(page_content='我最喜欢的食物是意大利面,尤其是番茄酱的那种。' , metadata={'page' : 5.0, 'account_id' : None}), 0.2671944797039032)]
如果想获取 Weaviate 原始集合的实例,可以通过 db._collection 快速获得,从而去执行一些原始操作,例如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from weaviate.classes.query import MetadataQuerycollection = db._collection response = collection.query.near_text( query="a sweet German white wine" , limit=2 , target_vector="title_country" , return_metadata=MetadataQuery(distance=True ) ) for o in response.objects: print (o.properties) print (o.metadata.distance)
1.5.4 自定义向量数据库 向量数据库的发展非常迅猛,几乎间隔几天就有新的向量数据库发布,LangChain 不可能将所有向量数据库都进行集成,亦或者封装的包存在这一些 bug 或错误,这个时候就需要考虑创建自定义向量数据库,去实现特定的方法。
在 LangChain 实现自定义向量数据库的类有两种模式,一种是继承封装好的数据库类,一种是继承基类 VectorStore。前一种一般继承后重写部分方法进行扩展或者修复 bug,后面一种是对接新的向量数据库。
在 LangChain 中,继承 VectorStore 只需实现最基础的 3 个方法即可正常使用:add_texts :将对应的数据添加到向量数据库中。similarity_search :最基础的相似性搜索。from_texts :从特定的文本列表、元数据列表中构建向量数据库。
其他方法因为使用频率并不高,VectorStore 并没有设置成虚拟方法,但是再没有实现的情况下,直接调用会报错,涵盖:_select_relevance_score_fn():根据距离计算相似性得分函数。similarity_search_with_score():携带得分的相似性搜索函数。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 import uuid from typing import List , Optional , Any , Iterable, Type import dotenv import numpy as np from langchain_core.documents import Document from langchain_core.embeddings import Embeddings from langchain_core.vectorstores import VectorStore from langchain_openai import OpenAIEmbeddings class MemoryVectorStore (VectorStore ): """基于内存+欧几里得距离的向量数据库""" store: dict = {} def __init__ (self, embedding: Embeddings ): self._embedding = embedding def add_texts (self, texts: Iterable[str ], metadatas: Optional [List [dict ]] = None , **kwargs: Any ) -> List [str ]: """将数据添加到向量数据库中""" if metadatas is not None and len (metadatas) != len (texts): raise ValueError("metadatas格式错误" ) embeddings = self._embedding.embed_documents(texts) ids = [str (uuid.uuid4()) for _ in texts] for idx, text in enumerate (texts): self.store[ids[idx]] = { "id" : ids[idx], "text" : text, "vector" : embeddings[idx], "metadata" : metadatas[idx] if metadatas is not None else {}, } return ids def similarity_search (self, query: str , k: int = 4 , **kwargs: Any ) -> List [Document]: """传入对应的query执行相似性搜索""" embedding = self._embedding.embed_query(query) result = [] for key, record in self.store.items(): distance = self._euclidean_distance(embedding, record["vector" ]) result.append({"distance" : distance, **record}) sorted_result = sorted (result, key=lambda x: x["distance" ]) result_k = sorted_result[:k] return [ Document(page_content=item["text" ], metadata={**item["metadata" ], "score" : item["distance" ]}) for item in result_k ] @classmethod def from_texts (cls: Type ["MemoryVectorStore" ], texts: List [str ], embedding: Embeddings, metadatas: Optional [List [dict ]] = None , **kwargs: Any ) -> "MemoryVectorStore" : """从文本和元数据中去构建向量数据库""" memory_vector_store = cls(embedding=embedding) memory_vector_store.add_texts(texts, metadatas, **kwargs) return memory_vector_store @classmethod def _euclidean_distance (cls, vec1: list , vec2: list ) -> float : """计算两个向量的欧几里得距离""" return np.linalg.norm(np.array(vec1) - np.array(vec2)) dotenv.load_dotenv() texts = [ "笨笨是一只很喜欢睡觉的猫咪" , "我喜欢在夜晚听音乐,这让我感到放松。" , "猫咪在窗台上打盹,看起来非常可爱。" , "学习新技能是每个人都应该追求的目标。" , "我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , "昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , "我的手机突然关机了,让我有些焦虑。" , "阅读是我每天都会做的事情,我觉得很充实。" , "他们一起计划了一次周末的野餐,希望天气能好。" , "我的狗喜欢追逐球,看起来非常开心。" , ] metadatas = [ {"page" : 1 }, {"page" : 2 }, {"page" : 3 }, {"page" : 4 }, {"page" : 5 }, {"page" : 6 , "account_id" : 1 }, {"page" : 7 }, {"page" : 8 }, {"page" : 9 }, {"page" : 10 }, ] embedding = OpenAIEmbeddings(model="text-embedding-3-small" ) db = MemoryVectorStore(embedding=embedding) ids = db.add_texts(texts, metadatas) print (ids) print (db.similarity_search("笨笨是谁?" ))
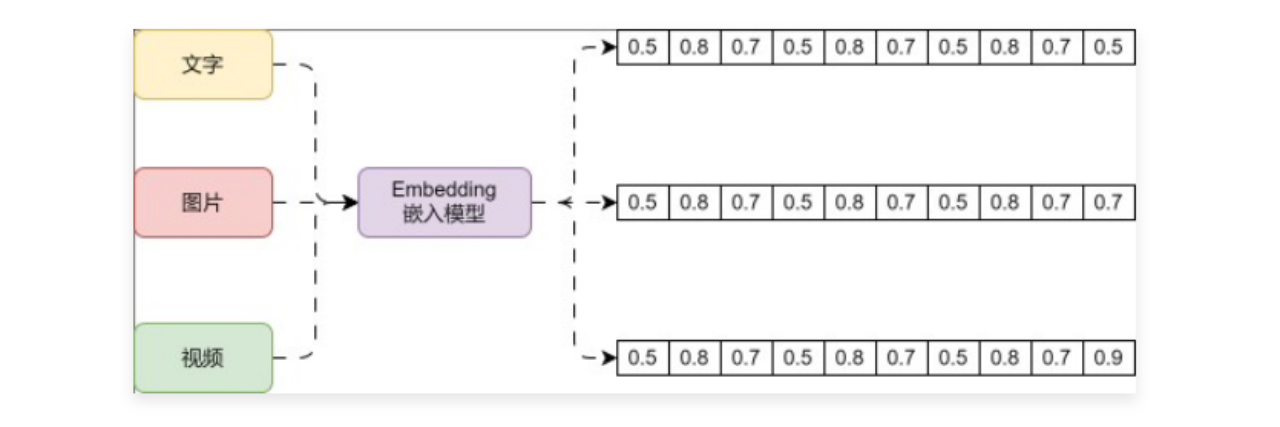
2 嵌入模型介绍和使用 2.1 嵌入模型介绍 要想使用向量数据库的相似性搜索,存储的数据必须是向量,那么如何将高维度的文字、图片、视频等非结构化数据转换成向量呢?这个时候就需要使用到 Embedding 嵌入模型了,例如下方就是 Embedding 嵌入模型的运行流程:
Embedding 模型是一种在机器学习和自然语言处理中广泛应用的技术,它旨在将高纬度的数据(如文字、图片、视频)映射到低纬度的空间。Embedding 向量是一个 N 维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。这种嵌入可以是一个词、一个类别特征(如商品、电影、物品等)或时间序列特征等。Embedding 向量可以更准确地表示对应特征的内在含义,使几何距离相近的向量对应的物体有相近的含义 ,甚至对向量进行加减乘除算法都有意义!一种模型生成方法,可以将非结构化的数据,例如文本/图片/视频等数据映射成有意义的向量数据 。
目前生成 embedding 方法的模型有以下 4 类:Word2Vec(词嵌入模型) :这个模型通过学习将单词转化为连续的向量表示,以便计算机更好地理解和处理文本。Word2Vec 模型基于两种主要算法 CBOW 和 Skip-gram。Glove :一种用于自然语言处理的词嵌入模型,它与其他常见的词嵌入模型(如 Word2Vec 和 FastText)类似,可以将单词转化为连续的向量表示。GloVe 模型的原理是通过观察单词在语料库中的共现关系,学习得到单词之间的语义关系。具体来说,GloVe 模型将共现概率矩阵表示为两个词向量之间的点积和偏差的关系,然后通过迭代优化来训练得到最佳的词向量表示。GloVe 模型的优点是它能够在大规模语料库上进行有损压缩,得到较小维度的词向量,同时保持了单词之间的语义关系。这些词向量可以被用于多种自然语言处理任务,如词义相似度计算、情感分析、文本分类等。FastText :一种基于词袋模型的词嵌入技术,与其他常见的词嵌入模型(如 Word2Vec 和 GloVe)不同之处在于,FastText考虑了单词的子词信息。其核心思想是将单词视为字符的 n-grams 的集合,在训练过程中,模型会同时学习单词级别和n-gram级别的表示。这样可以捕捉到单词内部的细粒度信息,从而更好地处理各种形态和变体的单词。大模型 Embeddings(重点) :和大模型相关的嵌入模型,如 OpenAI 官方发布的第二代模型:text-embedding-ada-002。它最长的输入是 8191 个tokens,输出的维度是 1536。
2.3 Embedding 的价值 1. 降维 :在许多实际问题中,原始数据的维度往往非常高。例如,在自然语言处理中,如果使用 Token 词表编码来表示词汇,其维度等于词汇表的大小,可能达到数十万甚至更高。通过 Embedding,我们可以将这些高维数据映射到一个低维空间,大大减少了模型的复杂度。捕捉语义信息 :Embedding 不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。例如,在词嵌入中,语义上相近的词在向量空间中也会相近。这意味着Embedding可以保留并利用原始数据的一些重要信息。适应性 : 与一些传统的特征提取方法相比,Embedding 是通过数据驱动的方式学习的。这意味着它能够自动适应数据的特性,而无需人工设计特征。泛化能力 :在实际问题中,我们经常需要处理一些在训练数据中没有出现过的数据。由于Embedding能够捕捉到数据的一些内在规律,因此对于这些未见过的数据,Embedding仍然能够给出合理的表示。可解释性 :尽管 Embedding 是高维的,但我们可以通过一些可视化工具(如t-SNE)来观察和理解 Embedding 的结构。这对于理解模型的行为,以及发现数据的一些潜在规律是非常有用的。
2.4 CacheBackEmbedding 组件 通过嵌入模型计算传递数据的向量需要昂贵的算力,对于重复的内容,Embeddings 计算的结果肯定是一致的,如果数据重复仍然二次计算,会导致效率非常低,而且增加无用功。
所以在 LangChain 中提供了一个叫 CacheBackEmbedding 的包装类,一般通过类方法 from_bytes_store 进行实例化,它接受以下参数:
CacheBackEmbedding 默认不缓存 embed_query 生成的向量,如果要缓存,需要设置 query_embedding_cache 的值,另外请尽可能设置 namespace,以避免使用不同嵌入模型嵌入的相同文本发生冲突。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import dotenv import numpy as np from langchain.embeddings import CacheBackedEmbeddings from langchain.storage import LocalFileStore from langchain_openai import OpenAIEmbeddings from numpy.linalg import norm dotenv.load_dotenv() def cosine_similarity (vector1: list , vector2: list ) -> float : """计算传入两个向量的余弦相似度""" dot_product = np.dot(vector1, vector2) norm_vec1 = norm(vector1) norm_vec2 = norm(vector2) return dot_product / (norm_vec1 * norm_vec2) embeddings = OpenAIEmbeddings(model="text-embedding-3-small" ) embeddings_with_cache = CacheBackedEmbeddings.from_bytes_store( embeddings, LocalFileStore("./cache/" ), namespace=embeddings.model, query_embedding_cache=True , ) query_vector = embeddings_with_cache.embed_query("你好,我是慕小课,我喜欢打篮球" ) documents_vector = embeddings_with_cache.embed_documents([ "你好,我是慕小课,我喜欢打篮球" , "这个喜欢打篮球的人叫慕小课" , "求知若渴,虚心若愚" ]) print (query_vector) print (len (query_vector)) print ("============" ) print (len (documents_vector)) print ("vector1与vector2的余弦相似度:" , cosine_similarity(documents_vector[0 ], documents_vector[1 ])) print ("vector2与vector3的余弦相似度:" , cosine_similarity(documents_vector[0 ], documents_vector[2 ]))
2.5 HuggingFace Embedding 模型的配置和使用 2.5.1 HuggingFace 本地模型 在某些对数据保密要求极高的场合下,数据不允许传递到外网,这个时候就可以考虑使用本地的文本嵌入模型——Hugging Face 本地嵌入模型,安装 langchain-huggingface 与 sentence-transformers 包,命令如下:
1 pip install -U langchain-huggingface sentence-transformers
其中 langchain-huggingface 是 langchain 团队基于 huggingface 封装的第三方社区包,sentence-transformers 是一个用于生成和使用预训练的文本嵌入,基于 transformer 架构,也是目前使用量最大的本地文本嵌入模型。
1 2 3 4 5 6 7 8 9 10 11 from langchain_huggingface import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L12-v2" , cache_folder="./embeddings/" ) query_vector = embeddings.embed_query("你好,我是慕小课,我喜欢打篮球游泳" ) print (query_vector) print (len (query_vector))
2.5.2 HuggingFace远程嵌入模型 部分模型的文件比较大,如果只是短期内调试,可以考虑使用 HuggingFace 提供的远程嵌入模型,首先安装对应的依赖
1 pip install huggingface_hub
然后在 Hugging Face 官网(https://huggingface.co/ ) 的 setting 中添加对应的访问秘钥,并配置到 .env 文件中
1 HUGGINGFACEHUB_API_TOKEN=xxx
接下来就可以使用 HuggingFace 提供的推理服务,这样在本地服务器上就无需配置对应的文本嵌入模型了。
1 2 3 4 5 6 7 8 9 10 11 import dotenv from langchain_huggingface import HuggingFaceEndpointEmbeddings dotenv.load_dotenv() embeddings = HuggingFaceEndpointEmbeddings(model="sentence-transformers/all-MiniLM-L12-v2" ) query_vector = embeddings.embed_query("你好,我是慕小课,我喜欢打篮球游泳" ) print (query_vector) print (len (query_vector))
相关资料信息:https://huggingface.co/ https://python.langchain.com/v0.2/docs/integrations/text_embedding/sentence_transformers/ http://imooc-langchain.shortvar.com/docs/integrations/text_embedding/sentence_transformers/
3 文档加载器 3.1 Document 与文档加载器 Document 类是 LangChain 中的核心组件,这个类定义了一个文档对象的结构,涵盖了文本内容和相关的元数据,Document 也是文档加载器、文档分割器、向量数据库、检索器这几个组件之间交互传递的状态数据。
在 LangChain 中封装了上百种文档加载器,几乎所有的文件都可以使用这些加载器完成数据的读取,而不需要手动去封装
代码示例:
1 2 3 4 5 6 7 8 9 10 11 from langchain_community.document_loaders import TextLoader loader = TextLoader("./电商产品数据.txt" , encoding="utf-8" ) documents = loader.load() print (documents) print (len (documents)) print (documents[0 ].metadata)
3.2 内置文档加载器的使用技巧 LangChain 内置文档加载器文档:https://imooc-langchain.shortvar.com/docs/integrations/document_loaders/
3.2.1 Markdown 文档加载器 LangChain 中封装了一个 UnstructuredMarkdownLoader 对象,要使用这个加载器,必须安装 unstructured 包,安装命令
1 pip install unstructured
代码示例:
1 2 3 4 5 6 7 8 from langchain_community.document_loaders import UnstructuredMarkdownLoader loader = UnstructuredMarkdownLoader("./项目API资料.md" ) documents = loader.load() print (documents) print (len (documents)) print (documents[0 ].metadata)
3.2.2 Office 文档加载器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_community.document_loaders import ( UnstructuredPowerPointLoader, ) ppt_loader = UnstructuredPowerPointLoader("./章节介绍.pptx" ) documents = ppt_loader.load() print (documents) print (len (documents)) print (documents[0 ].metadata)
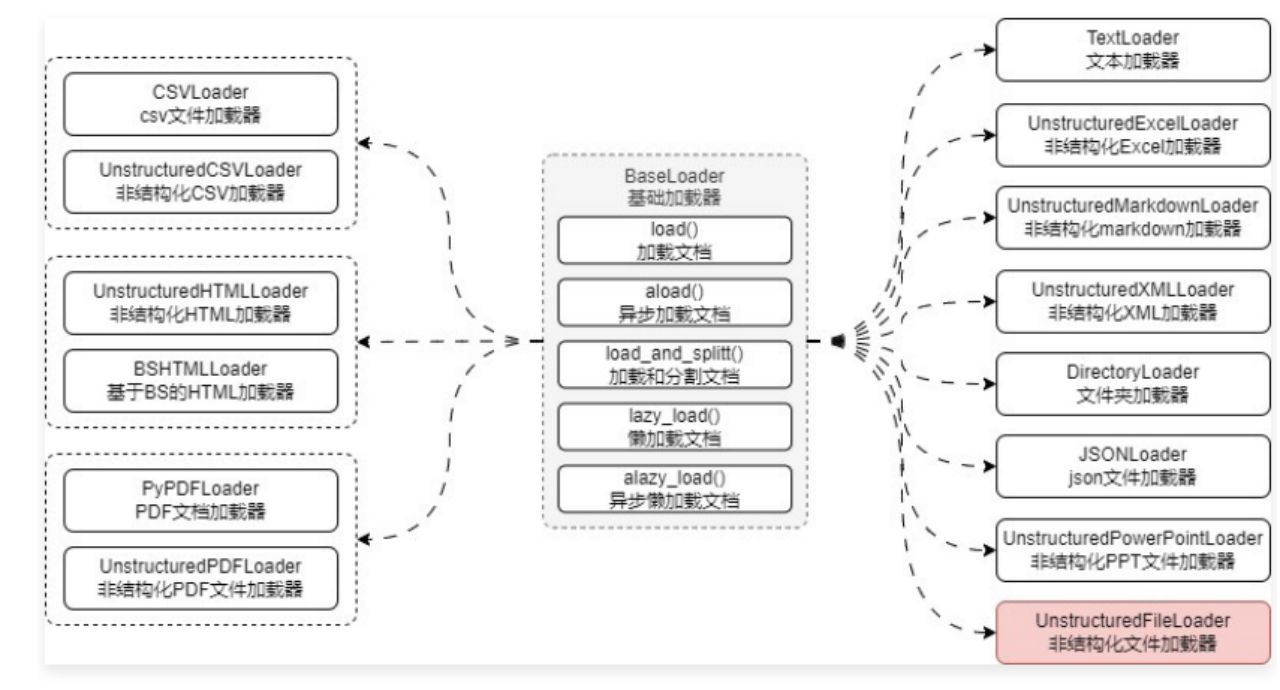
3.2.3 通用文档加载器 在实际的 LLM 应用开发中,由于数据的种类是无穷的,没办法单独为每一种数据配置一个加载器(也不现实),所以对于一些无法判断的数据类型或者想进行通用性文件加载,可以统一使用非结构化文件加载器 UnstructuredFileLoader 来实现对文件的加载。
UnstructuredFileLoader 是所有 UnstructuredXxxLoader 文档类的基类,其核心是将文档划分为元素,当传递一个文件时,库将读取文档,将其分割为多个部分,对这些部分进行分类,然后提取每个部分的文本,然后根据模式决定是否合并(single、paged、elements)。
例如通过检测文件的扩展名来加载不同的文件加载器,对于没校验到的文件类型,才考虑使用 UnstructuredFileLoader,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if file_extension in [".xlsx" , ".xls" ]: loader = UnstructuredExcelLoader(file_path) elif file_extension == ".pdf" : loader = UnstructuredPDFLoader(file_path) elif file_extension in [".md" , ".markdown" ]: loader = UnstructuredMarkdownLoader(file_path) elif file_extension in [".htm" , "html" ]: loader = UnstructuredHTMLLoader(file_path) elif file_extension in [".docx" , ".doc" ]: loader = UnstructuredWordDocumentLoader(file_path) elif file_extension == ".csv" : loader = UnstructuredCSVLoader(file_path) elif file_extension in [".ppt" , ".pptx" ]: loader = UnstructuredPowerPointLoader(file_path) elif file_extension == ".xml" : loader = UnstructuredXMLLoader(file_path) else : loader = UnstructuredFileLoader(file_path) if is_unstructured else TextLoader(file_path)
3.2.4 自定义文档加载器 代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from typing import Iterator, AsyncIterator from langchain_core.document_loaders import BaseLoader from langchain_core.documents import Document class CustomDocumentLoader (BaseLoader ): """自定义文档加载器,将文本文件的每一行都解析成Document""" def __init__ (self, file_path: str ) -> None : self.file_path = file_path def lazy_load (self ) -> Iterator[Document]: with open (self.file_path, encoding="utf-8" ) as f: line_number = 0 for line in f: yield Document( page_content=line, metadata={"score" : self.file_path, "line_number" : line_number} ) line_number += 1 async def alazy_load (self ) -> AsyncIterator[Document]: import aiofiles async with aiofiles.open (self.file_path, encoding="utf-8" ) as f: line_number = 0 async for line in f: yield Document( page_content=line, metadata={"score" : self.file_path, "line_number" : line_number} ) line_number += 1 loader = CustomDocumentLoader("./喵喵.txt" ) documents = loader.load() print (documents) print (len (documents)) print (documents[0 ].metadata)
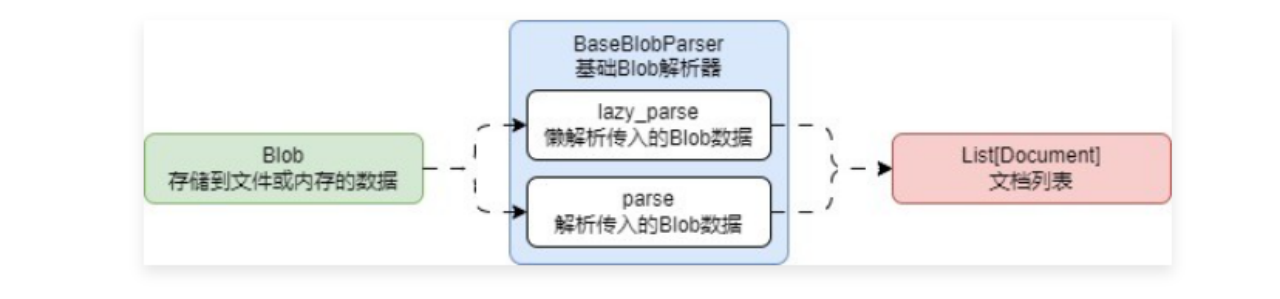
lazy_load() 方法的两个核心步骤就是:读取文件数据、将文件数据解析成Document,并且绝大部分文档加载器都有着两个核心步骤,而且 读取文件数据 这个步骤大家都大差不差。
就像 *.md、*.txt、*.py 这类文本文件,甚至是 *.pdf、*.doc 等这类非文本文件,都可以使用同一个 读取文件数据 步骤将文件读取为 二进制内容,然后在使用不同的解析逻辑来解析对应的二进制内容,所以很容易可以得出:
因此,在项目开发中,如果大量配置自定义文档解析器的话,将解析逻辑与加载逻辑分离,维护起来会更容易,而且也更容易复用相应的逻辑(具体使用哪种方式取决于开发)。
这样原先的 DocumentLoader 运行流程就变成了如下:
4 文本分割器 在 LangChain 中针对文档的转换也统一封装了一个基类 BaseDocumentTransformer,所有涉及到文档的转换的类均是该类的子类 ,将大块文档切割成 chunk 分块的文档分割器也是 BaseDocumentTransformer 的子类实现。
BaseDocumentTransformer 基类封装了两个方法:
在 LangChain 中,文档转换组件分成了两类:文档分割器(使用频率高)、文档处理转换器(使用频率低,老版本写法)。
1 pip install -qU langchain-text-splitters
4.2 字符分割器 在文档分割器中,最简单的分割器就是——字符串分割器 ,这个组件会基于给定的字符串进行分割,默认为 \n\n,并且在分割时会尽可能保证数据的连续性。分割出来每一块的长度是通过字符数来衡量的,使用起来也非常简单,实例化 CharacterTextSplitter 需传递多个参数,信息如下:
1. separator:分隔符,默认为 \n\n。
如果想将文档切割为不超过 500 字符,并且每块之间文本重叠 50 个字符,可以使用 CharacterTextSplitter 来实现,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain_text_splitters import CharacterTextSplitter loader = UnstructuredMarkdownLoader("./项目API文档.md" ) documents = loader.load() text_splitter = CharacterTextSplitter( separator="\n\n" , chunk_size=500 , chunk_overlap=50 , add_start_index=True , ) chunks = text_splitter.split_documents(documents) for chunk in chunks: print (f"块大小:{len (chunk.page_content)} , 元数据:{chunk.metadata} " ) print (len (chunks))
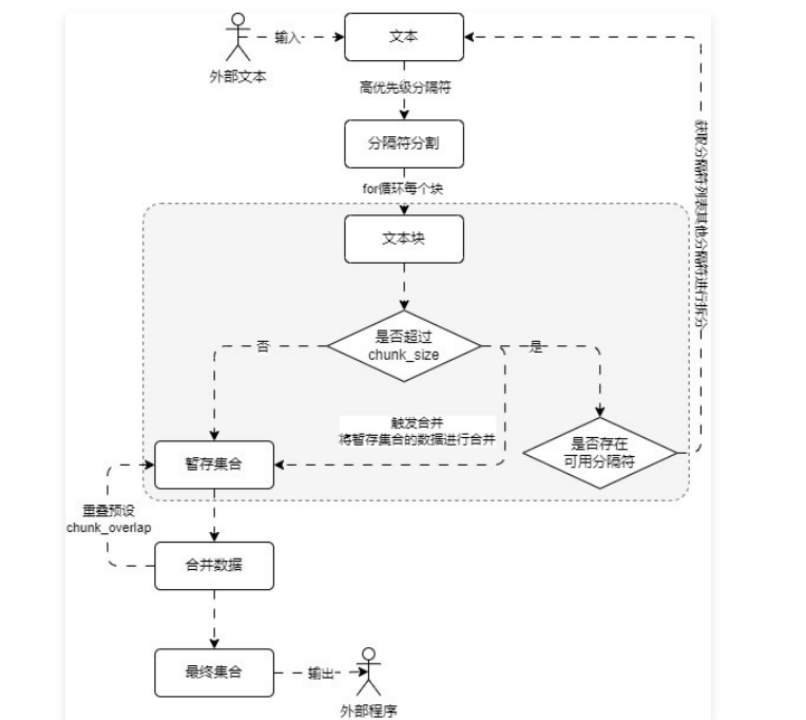
4.3 递归字符文本分割器 普通的字符文本分割器只能使用单个分隔符对文本内容进行划分,在划分的过程中,可能会出现文档块 过小 或者 过大 的情况,这会让 RAG 变得不可控,例如:文档块可能会变得非常大 ,极端的情况下某个块的内容长度可能就超过了 LLM 的上下文长度限制,这样这个文本块永远不会被引用到,相当于存储了数据,但是数据又丢失了。文档块可能会远远小于窗口大小 ,导致文档块的信息密度太低,块内容即使填充到 Prompt 中,LLM 也无法提取出有用的信息。
RecursiveCharacterTextSplitter,即递归字符串分割 ,这个分割器可以传递 一组分隔符 和 设定块内容大小,根据分隔符的优先顺序对文本进行预分割,然后将小块进行合并,将大块进行递归分割,直到获得所需块的大小,最终这些文档块的大小并不能完全相同,但是仍然会逼近指定长度。["\n\n", "\n", " ", ""],即优先使用换两行的数据进行分割,然后在使用单个换行符,如果块内容还是太大,则使用空格,最后再拆分成单个字符。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain_text_splitters import RecursiveCharacterTextSplitter loader = UnstructuredMarkdownLoader("./项目API文档.md" ) documents = loader.load() text_splitter = RecursiveCharacterTextSplitter( chunk_size=500 , chunk_overlap=50 , add_start_index=True , ) chunks = text_splitter.split_documents(documents) for chunk in chunks: print (f"块大小: {len (chunk.page_content)} , 元数据: {chunk.metadata} " )
4.4 语义文档分割器 语义相似性分割器,SemanticChunker 在使用上和其他的文档分割器存在一些差异,并且该类并没有继承 TextSplitter,实例化参数含义如下:
1. embeddings:文本嵌入模型,在该分类器底层使用向量的 余弦相似度 来识别语句之间的相似性。(?<=[.?!])\s+,即以英文的点、问号、感叹号切割语句,不同的文档需要传递不同的切割正则表达式。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import dotenv from langchain_community.document_loaders import UnstructuredFileLoader from langchain_experimental.text_splitter import SemanticChunker from langchain_openai import OpenAIEmbeddings dotenv.load_dotenv() loader = UnstructuredFileLoader("./科幻短篇.txt" ) text_splitter = SemanticChunker( embeddings=OpenAIEmbeddings(model="text-embedding-3-small" ), number_of_chunks=10 , add_start_index=True , sentence_split_regex=r"(?<=[。?!.?!])" ) documents = loader.load() chunks = text_splitter.split_documents(documents) for chunk in chunks: print (f"块大小: {len (chunk.page_content)} , 元数据: {chunk.metadata} " )
4.5 自定义文档分割器 代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from typing import List import jieba.analyse from langchain_community.document_loaders import UnstructuredFileLoader from langchain_text_splitters import TextSplitter class CustomTextSplitter (TextSplitter ): """自定义文本分割器""" def __init__ (self, seperator: str , top_k: int = 10 , **kwargs ): """构造函数,传递分割器还有需要提取的关键词数,默认为10""" super ().__init__(**kwargs) self._seperator = seperator self._top_k = top_k def split_text (self, text: str ) -> List [str ]: """传递对应的文本执行分割并提取分割数据的关键词,组成文档列表返回""" split_texts = text.split(self._seperator) text_keywords = [] for split_text in split_texts: text_keywords.append(jieba.analyse.extract_tags(split_text, self._top_k)) return ["," .join(keywords) for keywords in text_keywords] loader = UnstructuredFileLoader("./科幻短篇.txt" ) text_splitter = CustomTextSplitter("\n\n" , 10 ) documents = loader.load() chunks = text_splitter.split_documents(documents) for chunk in chunks: print (chunk.page_content)
4.6 非分割类型的文档分割器 在 LangChain 中,还存在另一种非分割类型的文档转换器,这类转换器也是传递 文档列表 并返回 文档列表,一般是将某种文档按照需求转换成另外一种格式(例如:翻译文档、文档重排、HTML 转文本、文档元数据提取、文档转问答 等)
4.6.1 问答转换器 在 RAG 的外挂知识库中,向量存储知识库中使用的文档通常以叙述或对话格式存储。但是,绝大部分用户的查询都是问题格式,所以如果我们在对文档进行向量化之前先将其转换为 问答格式,可以在一定程度上增加检索相关文档的可能性,降低检索不相关文档的可能性。
这个技巧也是 RAG 应用开发中常见的一种优化策略,即将原始数据转换成 QA 数据后进行存储,除此之外,对于绝大部分 LLM 的微调,使用的也是 QA问答数据 也可以考虑使用该问答转换器进行转换。
在 LangChain 中封装了 Doctran 库并实现了 DoctranQATransformer 类可以快捷实现该功能,这个库底层使用 OpenAI 的函数回调来实现对问答数据的提取,首先安装该库
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import dotenv from doctran import Doctran from langchain_community.document_transformers import DoctranQATransformer from langchain_core.documents import Document _ = Doctran dotenv.load_dotenv() page_content = """机密文件 - 仅供内部使用 日期:2023年7月1日 主题:各种话题的更新和讨论 亲爱的团队, 希望这封邮件能找到你们一切安好。在这份文件中,我想向你们提供一些重要的更新,并讨论需要我们关注的各种话题。请将此处包含的信息视为高度机密。 安全和隐私措施 作为我们不断致力于确保客户数据安全和隐私的一部分,我们已在所有系统中实施了强有力的措施。我们要赞扬IT部门的John Doe(电子邮件:john.doe@example.com)在增强我们网络安全方面的勤奋工作。未来,我们提醒每个人严格遵守我们的数据保护政策和准则。此外,如果您发现任何潜在的安全风险或事件,请立即向我们专门的团队报告,联系邮箱为security@example.com。 人力资源更新和员工福利 最近,我们迎来了几位为各自部门做出重大贡献的新团队成员。我要表扬Jane Smith(社保号:049-45-5928)在客户服务方面的出色表现。Jane一直受到客户的积极反馈。此外,请记住我们的员工福利计划的开放报名期即将到来。如果您有任何问题或需要帮助,请联系我们的人力资源代表Michael Johnson(电话:418-492-3850,电子邮件:michael.johnson@example.com)。 营销倡议和活动 我们的营销团队一直在积极制定新策略,以提高品牌知名度并推动客户参与。我们要感谢Sarah Thompson(电话:415-555-1234)在管理我们的社交媒体平台方面的杰出努力。Sarah在过去一个月内成功将我们的关注者基数增加了20%。此外,请记住7月15日即将举行的产品发布活动。我们鼓励所有团队成员参加并支持我们公司的这一重要里程碑。 研发项目 在追求创新的过程中,我们的研发部门一直在为各种项目不懈努力。我要赞扬David Rodriguez(电子邮件:david.rodriguez@example.com)在项目负责人角色中的杰出工作。David对我们尖端技术的发展做出了重要贡献。此外,我们希望每个人在7月10日定期举行的研发头脑风暴会议上分享他们的想法和建议,以开展潜在的新项目。 请将此文档中的信息视为最机密,并确保不与未经授权的人员分享。如果您对讨论的话题有任何疑问或顾虑,请随时直接联系我。 感谢您的关注,让我们继续共同努力实现我们的目标。 此致, Jason Fan 联合创始人兼首席执行官 Psychic jason@psychic.dev""" documents = [Document(page_content=page_content)] qa_transformer = DoctranQATransformer(openai_api_model="gpt-3.5-turbo-16k" ) transformer_documents = qa_transformer.transform_documents(documents) for qa in transformer_documents[0 ].metadata.get("questions_and_answers" ): print ("问答数据:" , qa)
输出内容:
1 2 3 4 5 6 7 8 9 10 11 {'question' : '文件日期是什么?' , 'answer' : '2023年7月1日' } {'question' : '文件主题是什么?' , 'answer' : '各种话题的更新和讨论' } {'question' : '谁是IT部门的网络安全负责人?' , 'answer' : 'John Doe(电子邮件:john.doe@example.com)' } {'question' : '如果发现安全风险或事件,应该向谁报告?' , 'answer' : '专门的团队,联系邮箱为security@example.com' } {'question' : '谁在客户服务方面表现出色?' , 'answer' : 'Jane Smith(社保号:049-45-5928)' } {'question' : '员工福利计划的开放报名期是什么时候?' , 'answer' : '即将到来' } {'question' : '人力资源代表的联系信息是什么?' , 'answer' : 'Michael Johnson(电话:418-492-3850,电子邮件:michael.johnson@example.com)' } {'question' : '谁在管理社交媒体平台方面做出了杰出努力?' , 'answer' : 'Sarah Thompson(电话:415-555-1234)' } {'question' : '产品发布活动的日期是什么时候?' , 'answer' : '7月15日' } {'question' : '谁在研发部门担任项目负责人角色?' , 'answer' : 'David Rodriguez(电子邮件:david.rodriguez@example.com)' } {'question' : '研发头脑风暴会议的日期是什么时候?' , 'answer' : '7月10日' }
4.6.2 翻译转换器 在 RAG 应用开发中,将文档通过嵌入/向量的方式进行比较的好处在于能跨语言工作,例如:你好,世界!、Hello, World! 和 こんにちは、世界! 分别是 中英日 三国的语言,但是因为语义相近,所以在向量空间中的位置也是非常接近的。
当一个 RAG 应用需要跨语言工作时,一般有两种策略:
5 文档检索器 5.1 带得分阈值的相似性搜索 在 LangChain 的相似性搜索中,无论结果多不匹配,只要向量数据库中存在数据,一定会查找出相应的结果,在 RAG 应用开发中,一般是将高相似文档插入到 Prompt 中,所以可以考虑添加一个 相似性得分阈值,超过该数值的部分才等同于有相似性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import dotenv from langchain_community.vectorstores import FAISS from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings dotenv.load_dotenv() embedding = OpenAIEmbeddings(model="text-embedding-3-small" ) documents = [ Document(page_content="笨笨是一只很喜欢睡觉的猫咪" , metadata={"page" : 1 }), Document(page_content="我喜欢在夜晚听音乐,这让我感到放松。" , metadata={"page" : 2 }), Document(page_content="猫咪在窗台上打盹,看起来非常可爱。" , metadata={"page" : 3 }), Document(page_content="学习新技能是每个人都应该追求的目标。" , metadata={"page" : 4 }), Document(page_content="我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , metadata={"page" : 5 }), Document(page_content="昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , metadata={"page" : 6 }), Document(page_content="我的手机突然关机了,让我有些焦虑。" , metadata={"page" : 7 }), Document(page_content="阅读是我每天都会做的事情,我觉得很充实。" , metadata={"page" : 8 }), Document(page_content="他们一起计划了一次周末的野餐,希望天气能好。" , metadata={"page" : 9 }), Document(page_content="我的狗喜欢追逐球,看起来非常开心。" , metadata={"page" : 10 }), ] db = FAISS.from_documents(documents, embedding) print (db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨" , score_threshold=0.4 ))
5.2 as_retriever() 检索器 在 LangChain 中,VectorStore 可以通过 as_retriever() 方法转换成检索器,在 as_retriever() 中可以传递一下参数:
1. search_type:搜索类型,支持 similarity(基础相似性搜索)、similarity_score_threshold(携带相似性得分+阈值判断的相似性搜索)、mmr(最大边际相关性搜索)。
并且由于检索器是 Runnable 可运行组件,所以可以使用 Runnable 组件的所有功能(组件替换、参数配置、重试、回退、并行等)。
例如将向量数据库转换成 携带得分+阈值判断的相似性搜索,并设置得分阈值为0.5,数据条数为10条,代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import dotenv import weaviate from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() loader = UnstructuredMarkdownLoader("./项目API文档.md" ) text_splitter = RecursiveCharacterTextSplitter( separators=["\n\n" , "\n" , "。|!|?" , "\.\s|\!\s|\?\s" , ";|;\s" , ",|,\s" , " " , "" , ], is_separator_regex=True , chunk_size=500 , chunk_overlap=50 , add_start_index=True , ) documents = loader.load() chunks = text_splitter.split_documents(documents) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) db.add_documents(chunks) retriever = db.as_retriever( search_type="similarity_score_threshold" , search_kwargs={"k" : 10 , "score_threshold" : 0.5 }, ) documents = retriever.invoke("关于配置接口的信息有哪些" ) print (list (document.page_content[:50 ] for document in documents)) print (len (documents))
5.3 MMR 最大边际相关性 最大边际相关性(MMR,max_marginal_relevance_search)的基本思想是同时考量查询与文档的 相关度,以及文档之间的 相似度。相关度 确保返回结果对查询高度相关,相似度 则鼓励不同语义的文档被包含进结果集。具体来说,它计算每个候选文档与查询的 相关度,并减去与已经入选结果集的文档的最大 相似度,这样更不相似的文档会有更高分。
而在 LangChain 中MMR 的实现过程和 FAISS 的 带过滤器的相似性搜索 非常接近,同样也是先执行相似性搜索,并得到一个远大于 k 的结果列表,例如 fetch_k 条数据,然后对搜索得到的 fetch_k 条数据计算文档之间的相似度,通过加权得分找到最终的 k 条数据。
简单来说,MMR 就是在一大堆最相似的文档中查找最不相似的,从而保证 结果多样化。
执行一个 MMR 最大边际相似性搜索需要的参数为:搜索语句、k条搜索结果数据、fetch_k条中间数据、多样性系数(0代表最大多样性,1代表最小多样性),在 LangChain 中也是基于这个思想进行封装,max_marginal_relevance_search() 函数的参数如下:
1. query:搜索语句,类型为字符串,必填参数。底层计算得分 = lambda_mult *相关性 - (1 - lambda_mult)*相似性,所以 0 代表最大多样性、1 代表最小多样性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import dotenv import weaviate from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() loader = UnstructuredMarkdownLoader("./项目API文档.md" ) text_splitter = RecursiveCharacterTextSplitter( separators=["\n\n" , "\n" , "。|!|?" , "\.\s|\!\s|\?\s" , ";|;\s" , ",|,\s" , " " , "" , ], is_separator_regex=True , chunk_size=500 , chunk_overlap=50 , add_start_index=True , ) documents = loader.load() chunks = text_splitter.split_documents(documents) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) search_documents = db.max_marginal_relevance_search("关于应用配置的接口有哪些?" ) for document in search_documents: print (document.page_content[:100 ]) print ("===========" )
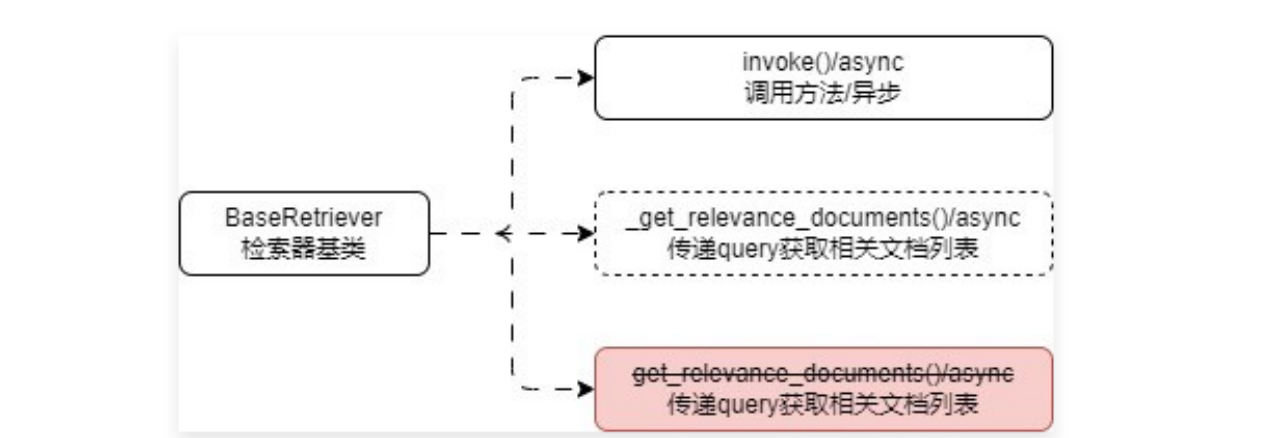
5.4 检索器组件 在 LangChain 中,传递一段 query 并返回与这段文本相关联文档的组件被称为 检索器,并且 LangChain 为所有检索器设计了一个基类——BaseRetriever,该类继承了 RunnableSerializable,所以该类是一个 Runnable 可运行组件,支持使用 Runnable 组件的所有配置,在 BaseRetriever 下封装了一些通用的方法,类图如下
其中 get_relevance_documents() 方法将在 0.3.0 版本开始被遗弃(老版本非 Runnable 写法),使用检索器的技巧也非常简单,按照特定的规则创建好检索器后(通过 as_retriever() 或者 构造函数),调用 invoke() 方法即可。
并且针对所有 向量数据库,LangChain 都配置了 as_retriever() 方法,便于快捷将向量数据库转换成检索器,不同的检索器传递的参数会有所差异,需要查看源码或者查看文档搭配使用,例如下方是一个向量数据库检索器的使用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import dotenv import weaviate from langchain_core.runnables import ConfigurableField from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever( search_type="similarity_score_threshold" , search_kwargs={"k" : 10 , "score_threshold" : 0.5 }, ).configurable_fields( search_type=ConfigurableField(id ="db_search_type" ), search_kwargs=ConfigurableField(id ="db_search_kwargs" ), ) mmr_documents = retriever.with_config( configurable={ "db_search_type" : "mmr" , "db_search_kwargs" : { "k" : 4 , } } ).invoke("关于应用配置的接口有哪些?" ) print ("相似性搜索: " , mmr_documents) print ("内容长度:" , len (mmr_documents)) print (mmr_documents[0 ].page_content[:20 ]) print (mmr_documents[1 ].page_content[:20 ])
5.5 自定义检索器 在 LangChain 中实现自定义检索器的技巧其实非常简单,只需要继承 BaseRetriever 类,然后实现 _get_relevant_documents() 方法即可,从 query 到 list[document] 的逻辑全部都在这个函数内部实现,异步的方法也可以不需要实现,底层会委托同步方法来执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from typing import List from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from langchain_core.retrievers import BaseRetriever class CustomRetriever (BaseRetriever ): """自定义检索器""" documents: list [Document] k: int def _get_relevant_documents (self, query: str , *, run_manager: CallbackManagerForRetrieverRun ) -> List [Document]: """根据传入的query,获取相关联的文档列表""" matching_documents = [] for document in self.documents: if len (matching_documents) > self.k: return matching_documents if query.lower() in document.page_content.lower(): matching_documents.append(document) return matching_documents documents = [ Document(page_content="笨笨是一只很喜欢睡觉的猫咪" , metadata={"page" : 1 }), Document(page_content="我喜欢在夜晚听音乐,这让我感到放松。" , metadata={"page" : 2 }), Document(page_content="猫咪在窗台上打盹,看起来非常可爱。" , metadata={"page" : 3 }), Document(page_content="学习新技能是每个人都应该追求的目标。" , metadata={"page" : 4 }), Document(page_content="我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , metadata={"page" : 5 }), Document(page_content="昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , metadata={"page" : 6 }), Document(page_content="我的手机突然关机了,让我有些焦虑。" , metadata={"page" : 7 }), Document(page_content="阅读是我每天都会做的事情,我觉得很充实。" , metadata={"page" : 8 }), Document(page_content="他们一起计划了一次周末的野餐,希望天气能好。" , metadata={"page" : 9 }), Document(page_content="我的狗喜欢追逐球,看起来非常开心。" , metadata={"page" : 10 }), ] retriever = CustomRetriever(documents=documents, k=3 ) retriever_documents = retriever.invoke("猫" ) print (retriever_documents) print (len (retriever_documents))
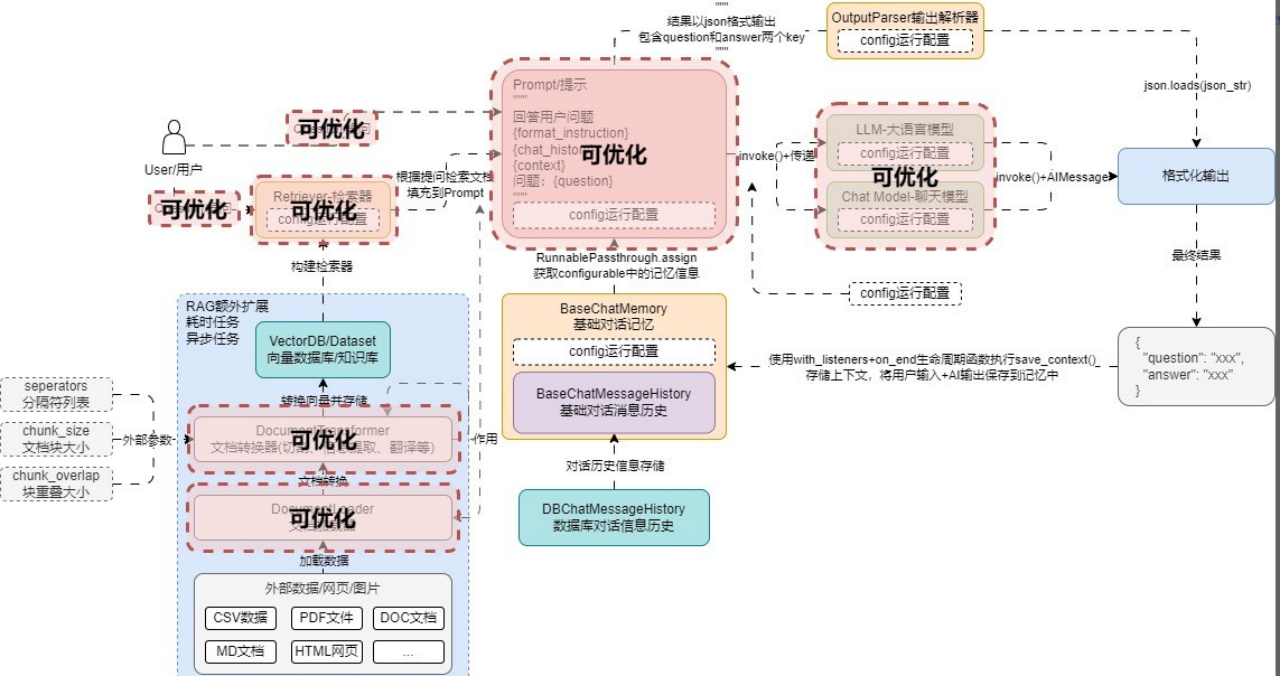
6 RAG 优化策略 6.1 RAG 开发6个阶段优化策略 在 RAG 应用开发中,无论架构多复杂,接入了多少组件,使用了多少优化策略与特性,所有优化的最终目标都是 提升LLM生成内容的准确性,而对于 Transformer架构类型 的大模型来说,要实现这个目标,一般只需要 3 个步骤:
1. 传递更准确的内容:传递和提问准确性更高的内容,会让 LLM 能识别到关联的内容, 生成的内容准确性更高。
看起来很简单,但是目前针对这 3 个步骤 N 多研究员提出了不少方案,比较遗憾的是,目前也没有一种统一的方案,不同的场合仍然需要考虑不同的方案结合才能实现相对好一点的效果,并不是所有场合都适合配置很复杂的优化策略。
在 RAG 应用开发中,使用的优化策略越多,单次响应成本越高,性能越差,需要合理使用。映射到 RAG 中,其实就是 切割合适的文档块、更准确的搜索语句、正确地排序文档、剔除重复无关的检索内容,所以在 RAG应用开发 中,想进行优化,可以针对 query(提问查询)、TextSplitter(文本分割器)、VectorStore(向量数据库)、Retriever(检索器)、Prompt(基础prompt编写) 这几个组件。
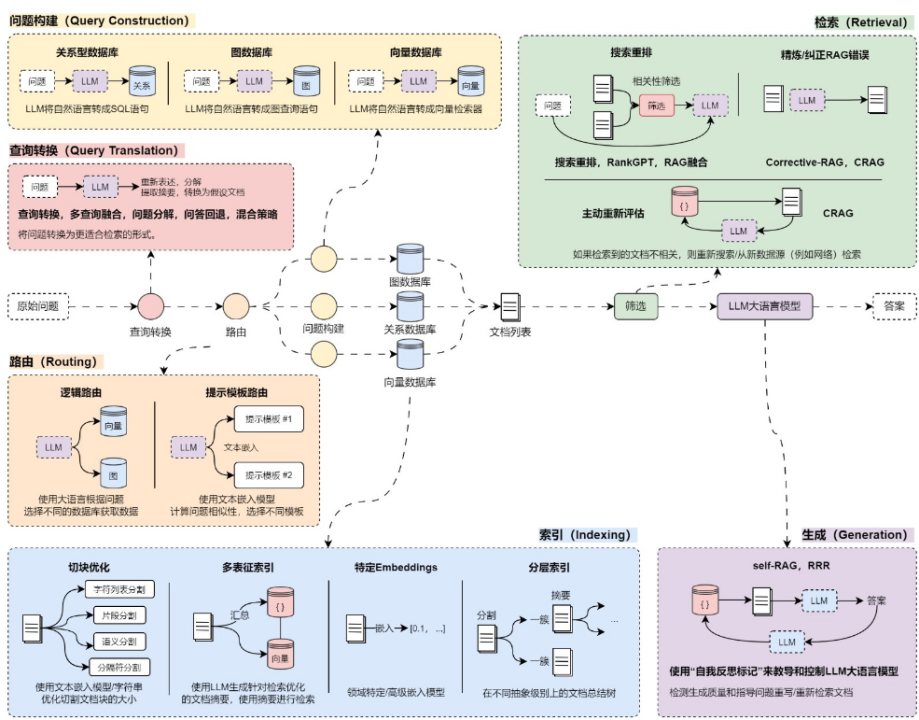
在 RAG 开发的 6 个阶段中,不同的阶段拥有不同的优化策略,需要针对不同的应用进行特定性的优化,目前市面上常见的优化方案有:问题转换、多路召回、混合检索、搜索重排、动态路由、图查询、问题重建、自检索 等数十种优化策略,每种策略所在的阶段并不一致,效果也有差异,并且相互影响。
6.2 多查询重写策略 6.2.1 Muliti-Query 多查询策略 多查询策略 也被称为 子查询,是一种用于生成子问题的技术,其核心思想是在问答过程中,为了更好地理解和回答主问题,系统会自动生成并提出与主问题相关的子问题,这些子问题通常具有更具体的细节,可以帮助大语言模型更深入地理解主问题,从而进行更加准确的检索并提供正确的答案。
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import dotenv import weaviate from langchain.retrievers import MultiQueryRetriever from langchain_openai import ChatOpenAI from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever(search_type="mmr" ) multi_query_retriever = MultiQueryRetriever.from_llm( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), include_original=True , ) docs = multi_query_retriever.invoke("关于LLMOps应用配置的文档有哪些" ) print (docs) print (len (docs))
输出:
1 2 3 [Document(metadata={'source' : './项目API文档.md' , 'start_index' : 0.0}, page_content='LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态码共有 6 种,其中只有 success(成功) 代表业务操作成功,其他 5 种状态均代表失败,并且失败时会附加相关的信息:fail(通用失败)、not_found(未找到)、unauthorized(未授权)、forbidden(无权限)和validate_error(数据验证失败)。\n\n接口示例:\n\njson { "code": "success", "data": { "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail" }, "message": "" }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 3042.0}, page_content='1.2 [todo]更新应用草稿配置信息\n\n接口说明:更新应用的草稿配置信息,涵盖:模型配置、长记忆模式等,该接口会查找该应用原始的草稿配置并进行更新,如果没有原始草稿配置,则创建一个新配置作为草稿配置。\n\n接口信息:授权+POST:/apps/:app_id/config\n\n接口参数:\n\n请求参数:\n\napp_id -> str:需要修改配置的应用 id。\n\nmodel_config -> json:模型配置信息。\n\ndialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\n请求示例:\n\njson { "model_config": { "dialog_round": 10 }, "memory_mode": "long_term_memory" }\n\n响应示例:\n\njson { "code": "success", "data": {}, "message": "更新AI应用配置成功" }\n\n1.3 [todo]获取应用调试长记忆' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 5818.0}, page_content='json { "code": "success", "data": { "list": [ { "id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "conversation_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8", "query": "能详细讲解下LLM是什么吗?", "answer": "LLM 即 Large Language Model,大语言模型,是一种基于深度学习的自然语言处理模型,具有很高的语言理解和生成能力,能够处理各式各样的自然语言任务,例如文本生成、问答、翻译、摘要等。它通过在大量的文本数据上进行训练,学习到语言的模式、结构和语义知识' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 675.0}, page_content='json { "code": "success", "data": { "list": [ { "app_count": 0, "created_at": 1713105994, "description": "这是专门用来存储慕课LLMOps课程信息的知识库", "document_count": 13, "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/07/96b5e270-c54a-4424-aece-ff8a2b7e4331.png", "id": "c0759ca8-2d35-4480-83a8-1f41f29d1401", "name": "慕课LLMOps课程知识库", "updated_at": 1713106758, "word_count": 8850 } ], "paginator": { "current_page": 1, "page_size": 20, "total_page": 1, "total_record": 2 } }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 2324.0}, page_content='json { "code": "success", "data": { "id": "5e7834dc-bbca-4ee5-9591-8f297f5acded", "name": "慕课LLMOps聊天机器人", "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/23/e4422149-4cf7-41b3-ad55-ca8d2caa8f13.png", "description": "这是一个慕课LLMOps的Agent应用", "published_app_config_id": null, "drafted_app_config_id": null, "debug_conversation_id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "published_app_config": null, "drafted_app_config": { "id": "755dc464-67cd-42ef-9c56-b7528b44e7c8"' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 2042.0}, page_content='dialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\nstatus -> string:应用配置的状态,drafted 代表草稿、published 代表已发布配置。\n\nupdated_at -> int:应用配置的更新时间。\n\ncreated_at -> int:应用配置的创建时间。\n\nupdated_at -> int:应用的更新时间。\n\ncreated_at -> int:应用的创建时间。\n\n响应示例:' )] 6
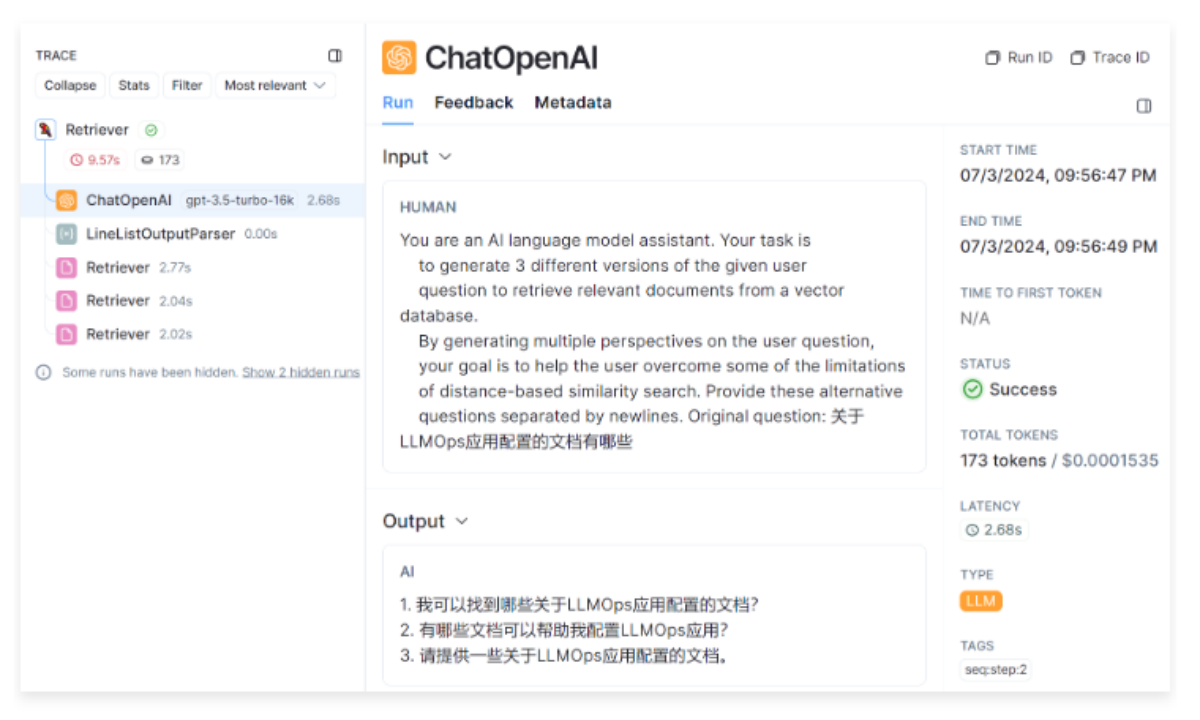
6.2.2 核心执行逻辑 从 LangSmith 平台记录的运行流程,可以很清晰看到这个检索器会先调用大语言模型生成 3 条与原始问题相关的 子问题,然后再逐个使用传递的检索器检索 3 个子问题,得到对应的文档列表,最后再将所有文档列表进行合并去重,得到最终的文档。
1 2 3 4 5 6 DEFAULT_QUERY_PROMPT = PromptTemplate( input_variables=["question" ], template="""You are an AI language model assistant. Your task is to generate 3 different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""" , )
在 LangChain 中,所有预设的 prompt 绝大部分场景都是使用 OpenAI 的大语言模型进行调试的,所以效果会比较好,对于其他的模型,例如国内的模型,一般来说还需要将对应的提示换成 中文语言,所以可以考虑使用 ChatGPT 翻译原有的 prompt,更新后
1 2 3 4 5 6 7 8 9 10 multi_query_retriever = MultiQueryRetriever.from_llm( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), prompt=ChatPromptTemplate.from_template( "你是一个AI语言模型助手。你的任务是生成给定用户问题的3个不同版本,以从向量数据库中检索相关文档。" "通过提供用户问题的多个视角,你的目标是帮助用户克服基于距离的相似性搜索的一些限制。" "请用换行符分隔这些替代问题。" "原始问题:{question}" ) )
基于中文 prompt 生成的问题列表如下
LLMOps应用配置的文档有哪些资源可供参考?
我可以在哪里找到关于LLMOps应用配置的文档?
有哪些文档可以帮助我了解LLMOps应用配置的相关信息?
对于该检索器,不同的模型生成的 query 格式可能并不一样,某些模型生成的多条 query 可能并不是按照 \n 进行分割,这个时候查询的效果可能不如原始问题,所以在使用该检索器时,一定要多次测试 prompt 的效果,或者设置 inclued_original 为 True,确保生成内容不符合规范时,仍然可以使用原始问题进行检索。
1 2 3 def _unique_documents (documents: Sequence [Document] ) -> List [Document]: return [doc for i, doc in enumerate (documents) if doc not in documents[:i]]
多查询策略是最基础+最简单的 RAG 优化,不涉及到复杂的逻辑与算法,会稍微影响单次对话的耗时。
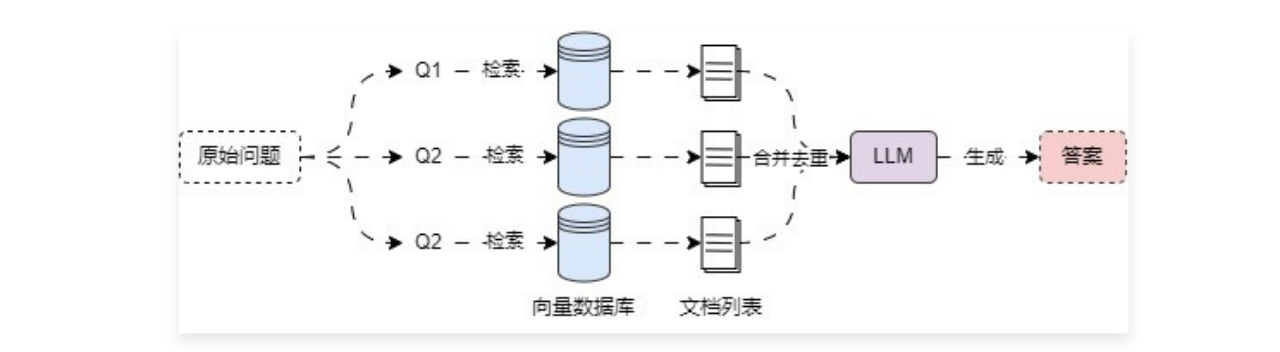
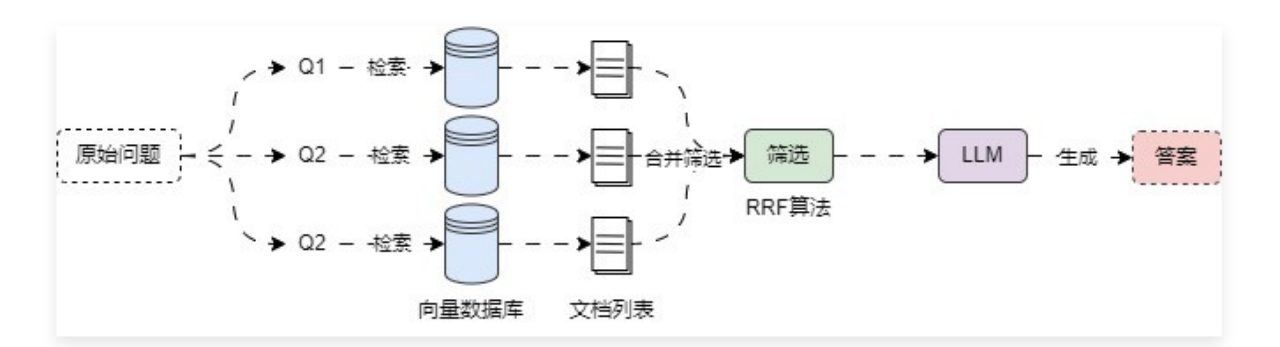
6.3 多查询结果融合 6.3.1 多查询结果融合策略及RRF 在 多查询重写策略 中,虽然可以生成多条查询并执行多次检索器检索,但是在合并数据的时候,并没有考虑最终结果的文档数,极端情况下,原始的 k 设置为 4,可能会返回 16 个文档(3 条子查询的文档,1 条原始问题查询的文档),除此之外,多查询重写策略 并不会考虑对应文档的权重,只按默认顺序进行合并。
6.3.2 多查询结果融合策略实现 在 LangChain 中并没有直接实现 RAG多查询结果融合策略 的检索器,所以可以考虑自定义实现,或者是继承 MultiQueryRetriever 并重写 retrieve_docments() 与 unique_union() 方法来实现对文档的 RRF 排名计算与合并。在方法内部将每次检索到的内容填充到一个两层列表中,然后传递给 RRF 函数即可。示例代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 from typing import List import dotenv import weaviate from langchain.load import dumps, loads from langchain.retrievers import MultiQueryRetriever from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() class RAGFusionRetriever (MultiQueryRetriever ): """RAG多查询结果融合策略检索器""" k: int = 4 def retrieve_documents ( self, queries: List [str ], run_manager: CallbackManagerForRetrieverRun ) -> List [List ]: """重写检索文档函数,返回值变成一个嵌套的列表""" documents = [] for query in queries: docs = self.retriever.invoke( query, config={"callbacks" : run_manager.get_child()} ) documents.append(docs) return documents def unique_union (self, documents: List [List ] ) -> List [Document]: """使用RRF算法来去重合并对应的文档,参数为嵌套列表,返回值为文档列表""" fused_result = {} for docs in documents: for rank, doc in enumerate (docs): doc_str = dumps(doc) if doc_str not in fused_result: fused_result[doc_str] = 0 fused_result[doc_str] += 1 / (rank + 60 ) reranked_results = [ (loads(doc), score) for doc, score in sorted (fused_result.items(), key=lambda x: x[1 ], reverse=True ) ] return [item[0 ] for item in reranked_results[:self.k]] db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever(search_type="mmr" ) rag_fusion_retriever = RAGFusionRetriever.from_llm( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), ) docs = rag_fusion_retriever.invoke("关于LLMOps应用配置的文档有哪些" ) print (docs) print (len (docs))
输出:
1 2 3 [Document(metadata={'source' : './项目API文档.md' , 'start_index' : 0.0}, page_content='LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态码共有 6 种,其中只有 success(成功) 代表业务操作成功,其他 5 种状态均代表失败,并且失败时会附加相关的信息:fail(通用失败)、not_found(未找到)、unauthorized(未授权)、forbidden(无权限)和validate_error(数据验证失败)。\n\n接口示例:\n\njson { "code": "success", "data": { "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail" }, "message": "" }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 5818.0}, page_content='json { "code": "success", "data": { "list": [ { "id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "conversation_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8", "query": "能详细讲解下LLM是什么吗?", "answer": "LLM 即 Large Language Model,大语言模型,是一种基于深度学习的自然语言处理模型,具有很高的语言理解和生成能力,能够处理各式各样的自然语言任务,例如文本生成、问答、翻译、摘要等。它通过在大量的文本数据上进行训练,学习到语言的模式、结构和语义知识' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 3042.0}, page_content='1.2 [todo]更新应用草稿配置信息\n\n接口说明:更新应用的草稿配置信息,涵盖:模型配置、长记忆模式等,该接口会查找该应用原始的草稿配置并进行更新,如果没有原始草稿配置,则创建一个新配置作为草稿配置。\n\n接口信息:授权+POST:/apps/:app_id/config\n\n接口参数:\n\n请求参数:\n\napp_id -> str:需要修改配置的应用 id。\n\nmodel_config -> json:模型配置信息。\n\ndialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\n请求示例:\n\njson { "model_config": { "dialog_round": 10 }, "memory_mode": "long_term_memory" }\n\n响应示例:\n\njson { "code": "success", "data": {}, "message": "更新AI应用配置成功" }\n\n1.3 [todo]获取应用调试长记忆' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 675.0}, page_content='json { "code": "success", "data": { "list": [ { "app_count": 0, "created_at": 1713105994, "description": "这是专门用来存储慕课LLMOps课程信息的知识库", "document_count": 13, "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/07/96b5e270-c54a-4424-aece-ff8a2b7e4331.png", "id": "c0759ca8-2d35-4480-83a8-1f41f29d1401", "name": "慕课LLMOps课程知识库", "updated_at": 1713106758, "word_count": 8850 } ], "paginator": { "current_page": 1, "page_size": 20, "total_page": 1, "total_record": 2 } }' )] 4
6.4 问题分解策略提升复杂问题检索正确率 6.4.1 复杂问题检索的难点与分解 在 RAG 应用开发中,对于一些提问相对复杂的原始问题来说,无论是使用原始问题进行检索,亦或者生成多个相关联的问题进行检索,往往都很难在向量数据库中找到关联性高的文档,导致 RAG 效果偏差。
1. 复杂问题由多个问题按顺序步骤组成,执行相似性搜索时,向量数据库存储的都是基础文档数据,往往相似度低,但是这些数据在现实世界又可能存在很大的关联(文本嵌入模型的限制,一条向量不可能无损记录段落信息)。
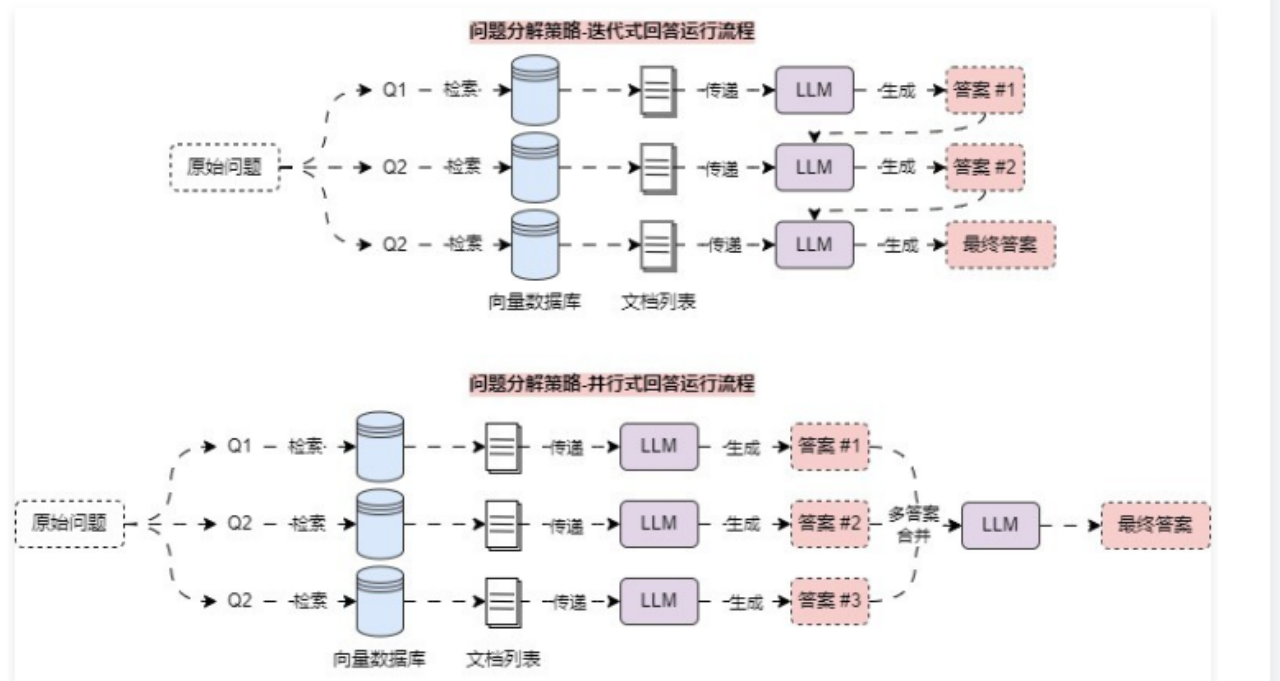
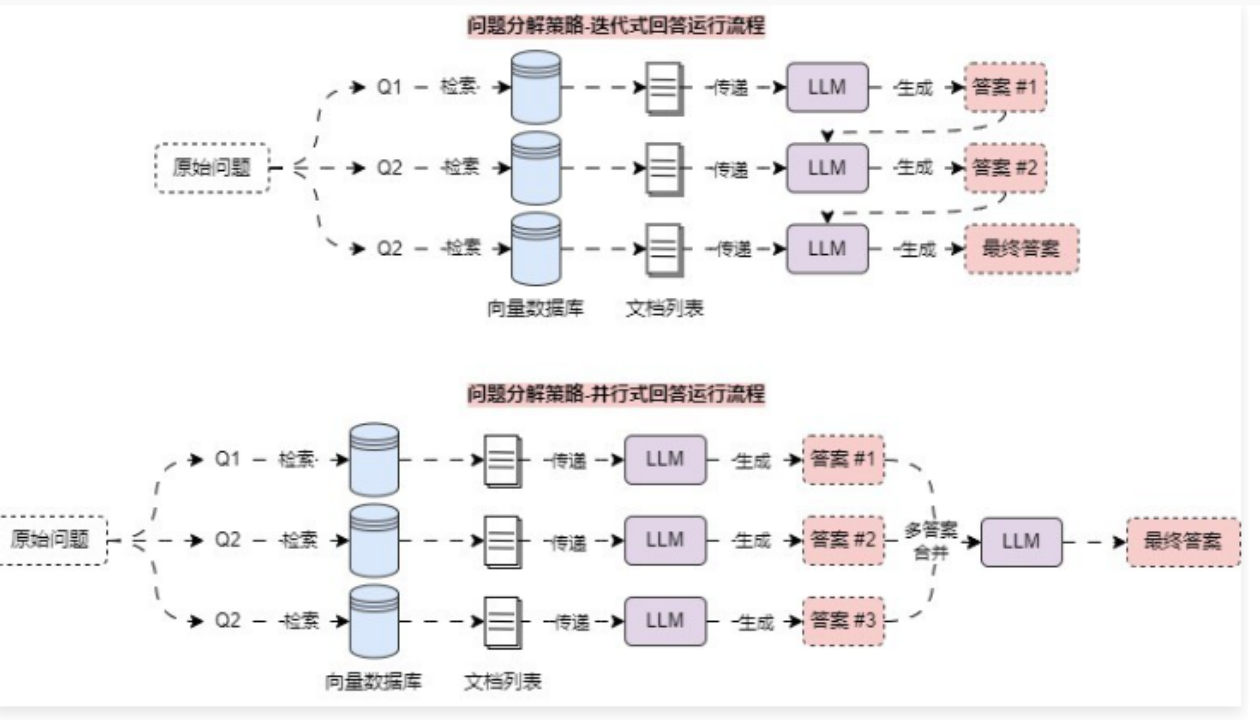
对于这类 RAG 应用场景,可以使用 问题分解策略,将一个复杂问题分解成多个子问题,和 多查询重写策略 不一样的是,这个策略生成的子问题使用的是 深度优先,即解决完第一个问题后,对应的资料传递给第二个问题,以此类推;亦或者是并行将每个问题的答案合并成最终问题。
6.4.2 迭代式回答实现 在 LangChain 中,并没有针对 问题分解策略 实现对应的 检索器 或者 预设链,所以只能自行实现这个优化策略,由于问题分解策略同样也是先生成对应的子问题(深入优先),所以需要单独构建一条链先进行问题的分解,然后迭代执行相应的检索,得到上下文,并使用 LLM 回复该问题,将得到的 迭代答案+问题,传递给下一个子问题。代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from operator import itemgetter import dotenv import weaviate from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() def format_qa_pair (question: str , answer: str ) -> str : """格式化传递的问题+答案为单个字符串""" return f"Question: {question} \nAnswer: {answer} \n\n" .strip() decomposition_prompt = ChatPromptTemplate.from_template( "你是一个乐于助人的AI助理,可以针对一个输入问题生成多个相关的子问题。\n" "目标是将输入问题分解成一组可以独立回答的子问题或者子任务。\n" "生成与一下问题相关的多个搜索查询:{question}\n" "并使用换行符进行分割,输出(3个子问题/子查询):" ) decomposition_chain = ( {"question" : RunnablePassthrough()} | decomposition_prompt | ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) | StrOutputParser() | (lambda x: x.strip().split("\n" )) ) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever(search_type="mmr" ) question = "关于LLMOps应用配置的文档有哪些" sub_questions = decomposition_chain.invoke(question) prompt = ChatPromptTemplate.from_template("""这是你需要回答的问题: --- {question} --- 这是所有可用的背景问题和答案对: --- {qa_pairs} --- 这是与问题相关的额外背景信息: --- {context} ---""" ) chain = ( { "question" : itemgetter("question" ), "qa_pairs" : itemgetter("qa_pairs" ), "context" : itemgetter("question" ) | retriever, } | prompt | ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) | StrOutputParser() ) qa_pairs = "" for sub_question in sub_questions: answer = chain.invoke({"question" : sub_question, "qa_pairs" : qa_pairs}) qa_pair = format_qa_pair(sub_question, answer) qa_pairs += "\n---\n" + qa_pair print (f"问题: {sub_question} " ) print (f"答案: {answer} " )
6.5 Step-Back 回答回退策略 6.5.1 少量示例模板 在与 LLM 的对话中,提供少量的示例被称为 少量示例,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型性能(与之对应的是零样本),少量示例可以降低 Prompt 的复杂度,快速告知 LLM 生成内容的规范。
在 LangChain 中,针对少量示例也封装对应的提示模板——FewShotPromptTemplate,这个提示模板只需要传递 示例列表 与 示例模板 即可快速构建 少量示例提示模板,使用示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate from langchain_openai import ChatOpenAI dotenv.load_dotenv() example_prompt = ChatPromptTemplate.from_messages([ ("human" , "{question}" ), ("ai" , "{answer}" ), ]) examples = [ {"question" : "帮我计算下2+2等于多少?" , "answer" : "4" }, {"question" : "帮我计算下2+3等于多少?" , "answer" : "5" }, {"question" : "帮我计算下20*15等于多少?" , "answer" : "300" }, ] few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) print ("少量示例模板:" , few_shot_prompt.format ()) prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个可以计算复杂数学问题的聊天机器人" ), few_shot_prompt, ("human" , "{question}" ), ]) llm = ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) chain = prompt | llm | StrOutputParser() print (chain.invoke("帮我计算下14*15等于多少" ))
输出:
1 2 3 4 5 6 7 少量示例模板: Human: 帮我计算下2+2等于多少? AI: 4 Human: 帮我计算下2+3等于多少? AI: 5 Human: 帮我计算下20*15等于多少? AI: 300 210
少量示例提示模板 在底层会根据传递的 示例模板 与 示例 格式化对应的 消息列表 或者 字符串,从而将对应的示例参考字符串信息添加到完整的提示模板中,简化了 Prompt 编写的繁琐程度。
6.5.2 Step-Back 回答回退策略 对于一些复杂的问题,除了使用 问题分解 来得到子问题亦或者依赖问题,还可以为复杂问题生成一个前置问题,通过前置问题来执行相应的检索,这就是 Setp-Back 回答回退策略(后退提示),这是一种用于增强语言模型的推理和问题解决能力的技巧,它鼓励 LLM 从一个给定的问题或问题后退一步,提出一个更抽象、更高级的问题,涵盖原始查询的本质。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 from typing import List import dotenv import weaviate from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from langchain_core.language_models import BaseLanguageModel from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate from langchain_core.retrievers import BaseRetriever from langchain_core.runnables import RunnablePassthrough from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() class StepBackRetriever (BaseRetriever ): """回答回退检索器""" retriever: BaseRetriever llm: BaseLanguageModel def _get_relevant_documents ( self, query: str , *, run_manager: CallbackManagerForRetrieverRun ) -> List [Document]: """根据传递的query执行问题回退并检索""" examples = [ {"input" : "慕课网上有关于AI应用开发的课程吗?" , "output" : "慕课网上有哪些课程?" }, {"input" : "慕小课出生在哪个国家?" , "output" : "慕小课的人生经历是什么样的?" }, {"input" : "司机可以开快车吗?" , "output" : "司机可以做什么?" }, ] example_prompt = ChatPromptTemplate.from_messages([ ("human" , "{input}" ), ("ai" , "{output}" ), ]) few_shot_prompt = FewShotChatMessagePromptTemplate( examples=examples, example_prompt=example_prompt, ) prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个世界知识的专家。你的任务是回退问题,将问题改述为更一般或者前置问题,这样更容易回答,请参考示例来实现。" ), few_shot_prompt, ("human" , "{question}" ), ]) chain = ( {"question" : RunnablePassthrough()} | prompt | self.llm | StrOutputParser() | self.retriever ) return chain.invoke(query) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever(search_type="mmr" ) step_back_retriever = StepBackRetriever( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), ) documents = step_back_retriever.invoke("人工智能会让世界发生翻天覆地的变化吗?" ) print (documents) print (len (documents))
输出:
1 2 3 [Document(metadata={'source' : './项目API文档.md' , 'start_index' : 5818.0}, page_content='json { "code": "success", "data": { "list": [ { "id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "conversation_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8", "query": "能详细讲解下LLM是什么吗?", "answer": "LLM 即 Large Language Model,大语言模型,是一种基于深度学习的自然语言处理模型,具有很高的语言理解和生成能力,能够处理各式各样的自然语言任务,例如文本生成、问答、翻译、摘要等。它通过在大量的文本数据上进行训练,学习到语言的模式、结构和语义知识' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 6359.0}, page_content='1.7 [todo]删除特定的调试消息\n\n接口说明:用于删除 AI 应用调试对话过程中指定的消息,该删除会在后端执行软删除操作,并且只有当会话 id 和消息 id 都匹配上时,才会删除对应的调试消息。\n\n接口信息:授权+POST:/apps/:app_id/messages/:message_id/delete\n\n接口参数:\n\n请求参数:\n\napp_id -> uuid:路由参数,需要删除消息归属的应用 id,格式为 uuid。\n\nmessage_id -> uuid:路由参数,需要删除的消息 id,格式为 uuid。\n\n请求示例:\n\njson { "app_id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "message_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8" }\n\n响应示例:\n\njson { "code": "success", "data": {}, "message": "删除调试信息成功" }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 490.0}, page_content='带有分页数据的接口会在 data 内固定传递 list 和 paginator 字段,其中 list 代表分页后的列表数据,paginator 代表分页的数据。\n\npaginator 内存在 4 个字段:current_page(当前页数) 、page_size(每页数据条数)、total_page(总页数)、total_record(总记录条数),示例数据如下:' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 2042.0}, page_content='dialog_round -> int:携带上下文轮数,类型为非负整型。\n\nmemory_mode -> string:记忆类型,涵盖长记忆 long_term_memory 和 none 代表无。\n\nstatus -> string:应用配置的状态,drafted 代表草稿、published 代表已发布配置。\n\nupdated_at -> int:应用配置的更新时间。\n\ncreated_at -> int:应用配置的创建时间。\n\nupdated_at -> int:应用的更新时间。\n\ncreated_at -> int:应用的创建时间。\n\n响应示例:' )] 4
对比 问题分解策略,回答回退策略 仅仅多调用一次 LLM,所以相应速度更快,性能更高,并且复杂度更低,对于一些参数量较小的模型,也可以实现不错的效果,对于 问题分解策略-迭代式回答,在一些极端的情况下,模型输出了有偏差的内容,每次都在有偏差的 问题+答案 生成新内容,很有可能会导致最后的输出完全偏离开始的预设。
6.6 混合策略实现 doc-doc 对称检索 6.6.1 HyDE 混合策略 在前面的课时中,学习的优化策略都是将对应的 查询 生成 新查询,通过 新查询 来执行相应的检索,但是在数据库中存储的数据一般都是 文档 层面上的,数据会远远比 查询 要大很多,所以 query 和 doc 之间是不对称检索,能找到的相似性文档相对来说也比较少。
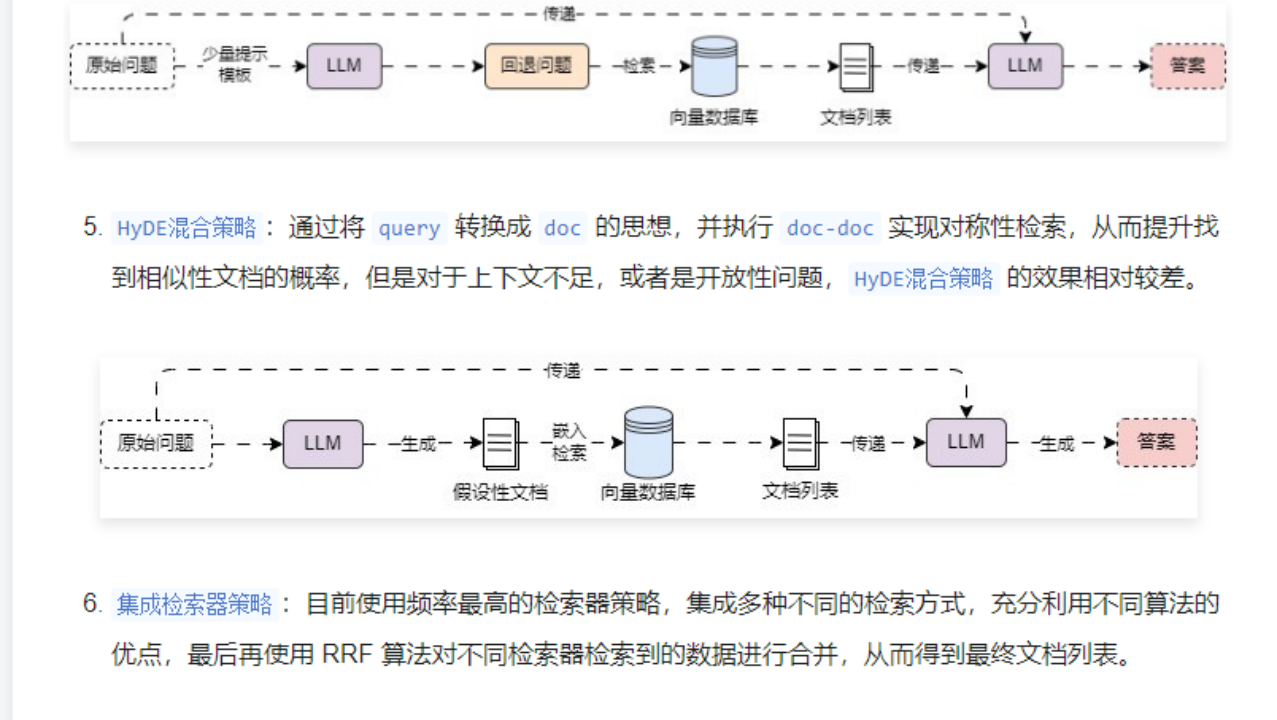
在这篇论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》中提出了一个 HyDE混合策略 的概念,首先利用 LLM 将问题转换为回答问题的假设性文档/假回答,然后使用嵌入的 假设性文档 去检索真实文档,前提是因为 doc-doc 这个模式执行相似性搜索可以尝试更多的匹配项。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 from typing import List import dotenv import weaviate from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from langchain_core.language_models import BaseLanguageModel from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.retrievers import BaseRetriever from langchain_core.runnables import RunnablePassthrough from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() class HyDERetriever (BaseRetriever ): """HyDE混合策略检索器""" retriever: BaseRetriever llm: BaseLanguageModel def _get_relevant_documents ( self, query: str , *, run_manager: CallbackManagerForRetrieverRun ) -> List [Document]: """传递检索query实现HyDE混合策略检索""" prompt = ChatPromptTemplate.from_template( "请写一篇科学论文来回答这个问题。\n" "问题: {question}\n" "文章: " ) chain = ( {"question" : RunnablePassthrough()} | prompt | self.llm | StrOutputParser() | self.retriever ) return chain.invoke(query) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="DatasetDemo" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = db.as_retriever(search_type="mmr" ) hyde_retriever = HyDERetriever( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), ) documents = hyde_retriever.invoke("关于LLMOps应用配置的文档有哪些?" ) print (documents) print (len (documents))
输出 :
1 2 3 [Document(metadata={'source' : './项目API文档.md' , 'start_index' : 0.0}, page_content='LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态码共有 6 种,其中只有 success(成功) 代表业务操作成功,其他 5 种状态均代表失败,并且失败时会附加相关的信息:fail(通用失败)、not_found(未找到)、unauthorized(未授权)、forbidden(无权限)和validate_error(数据验证失败)。\n\n接口示例:\n\njson { "code": "success", "data": { "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail" }, "message": "" }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 1621.0}, page_content='id -> uuid:应用 id,类型为 uuid。\n\nname -> string:应用名称。\n\nicon -> string:应用图标。\n\ndescription -> string:应用描述。\n\npublished_app_config_id -> uuid:已发布应用配置 id,如果不存在则为 null。\n\ndrafted_app_config_id -> uuid:草稿应用配置 id,如果不存在则为 null。\n\ndebug_conversation_id -> uuid:调试会话记录 id,如果不存在则为 null。\n\npublished_app_config/drafted_app_config -> json:应用配置信息,涵盖草稿配置、已发布配置,如果没有则为 null,两个配置的变量信息一致。\n\nid -> uuid:应用配置 id。\n\nmodel_config -> json:模型配置,类型为 json。\n\ndialog_round -> int:携带上下文轮数,类型为非负整型。' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 5818.0}, page_content='json { "code": "success", "data": { "list": [ { "id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "conversation_id": "2d7d3e3f-95c9-4d9d-ba9c-9daaf09cc8a8", "query": "能详细讲解下LLM是什么吗?", "answer": "LLM 即 Large Language Model,大语言模型,是一种基于深度学习的自然语言处理模型,具有很高的语言理解和生成能力,能够处理各式各样的自然语言任务,例如文本生成、问答、翻译、摘要等。它通过在大量的文本数据上进行训练,学习到语言的模式、结构和语义知识' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 490.0}, page_content='带有分页数据的接口会在 data 内固定传递 list 和 paginator 字段,其中 list 代表分页后的列表数据,paginator 代表分页的数据。\n\npaginator 内存在 4 个字段:current_page(当前页数) 、page_size(每页数据条数)、total_page(总页数)、total_record(总记录条数),示例数据如下:' )] 4
6.6.2 局限性 对于 doc-doc 类型的检索,虽然在语义空间上保持了一致,但是在 query->doc 的过程中,受限于各种因素,仍然可能产生错误信息。
6.7 集成多种检索器算法的混合检索 6.7.1 集成检索器的优势与使用 在 LangChain 中,封装了一个集成检索器 EnsembleRetriever,这个检索器接受一个检索器列表作为输入,并根据 RRF 算法对每个检索器的 get_relevant_documents() 方法产生的文档列表进行集成和重新排序。
混合检索器 被广泛应用于各类 AI 应用开发平台,例如:Dify、Coze、智谱 等平台,
例如使用 BM25关键词搜索 和 FAISS相似性搜索 进行结合,实现混合搜索,首先安装 rank_bm25 包,命令如下
1 pip install -U rank_bm25
代码示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import dotenv from langchain.retrievers import EnsembleRetriever from langchain_community.retrievers import BM25Retriever from langchain_community.vectorstores import FAISS from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings dotenv.load_dotenv() documents = [ Document(page_content="笨笨是一只很喜欢睡觉的猫咪" , metadata={"page" : 1 }), Document(page_content="我喜欢在夜晚听音乐,这让我感到放松。" , metadata={"page" : 2 }), Document(page_content="猫咪在窗台上打盹,看起来非常可爱。" , metadata={"page" : 3 }), Document(page_content="学习新技能是每个人都应该追求的目标。" , metadata={"page" : 4 }), Document(page_content="我最喜欢的食物是意大利面,尤其是番茄酱的那种。" , metadata={"page" : 5 }), Document(page_content="昨晚我做了一个奇怪的梦,梦见自己在太空飞行。" , metadata={"page" : 6 }), Document(page_content="我的手机突然关机了,让我有些焦虑。" , metadata={"page" : 7 }), Document(page_content="阅读是我每天都会做的事情,我觉得很充实。" , metadata={"page" : 8 }), Document(page_content="他们一起计划了一次周末的野餐,希望天气能好。" , metadata={"page" : 9 }), Document(page_content="我的狗喜欢追逐球,看起来非常开心。" , metadata={"page" : 10 }), ] bm25_retriever = BM25Retriever.from_documents(documents) bm25_retriever.k = 4 faiss_db = FAISS.from_documents(documents, embedding=OpenAIEmbeddings(model="text-embedding-3-small" )) faiss_retriever = faiss_db.as_retriever(search_kwargs={"k" : 4 }) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5 , 0.5 ], ) docs = ensemble_retriever.invoke("除了猫,你养了什么宠物呢?" ) print (docs) print (len (docs))
输出:
1 2 3 [Document(metadata={'page' : 10}, page_content='我的狗喜欢追逐球,看起来非常开心。' ), Document(metadata={'page' : 3}, page_content='猫咪在窗台上打盹,看起来非常可爱。' ), Document(metadata={'page' : 9}, page_content='他们一起计划了一次周末的野餐,希望天气能好。' ), Document(metadata={'page' : 1}, page_content='笨笨是一只很喜欢睡觉的猫咪' ), Document(metadata={'page' : 8}, page_content='阅读是我每天都会做的事情,我觉得很充实。' ), Document(metadata={'page' : 7}, page_content='我的手机突然关机了,让我有些焦虑。' ), Document(metadata={'page' : 5}, page_content='我最喜欢的食物是意大利面,尤其是番茄酱的那种。' )] 7
在实际的开发中,除了硬编码不同检索器与对应的权重,还可以在运行时配置检索器,在检索时动态控制某个检索器输出内容的数量、权重等,例如
1 2 3 4 5 6 7 8 9 10 faiss_retriever = faiss_db.as_retriever(search_kwargs={"k" : 4 }).configurable_fields( search_kwargs=ConfigurableField( id ="search_kwargs_faiss" , name="搜索参数" , description="要使用的搜索参数" , ) ) config = {"configurable" : {"search_kwargs_faiss" : {"k" : 1 }}} docs = ensemble_retriever.invoke("苹果" , config=config)
6.7.2 查询转换阶段优化策略总结 在 RAG 的 查询转换 阶段,目前市面上主流的优化策略其实我们都已经讲解完了,涵盖了:多查询重写、RAG 多查询结果融合、问题分解策略、回答回退策略、HyDE 混合策略、集成检索器策略 等,不同的优化策略有不同的优缺点:
6.8 检索器的逻辑路由缩减检索范围 – 逻辑路由阶段 在 RAG 应用开发中,想根据不同的问题检索不同的 检索器/向量数据库,其实只需要设定要对应的 Prompt,然后让 LLM 根据传递的问题返回需要选择的 检索器/向量数据库 的名称,然后根据得到的名称选择不同的 检索器 即可。
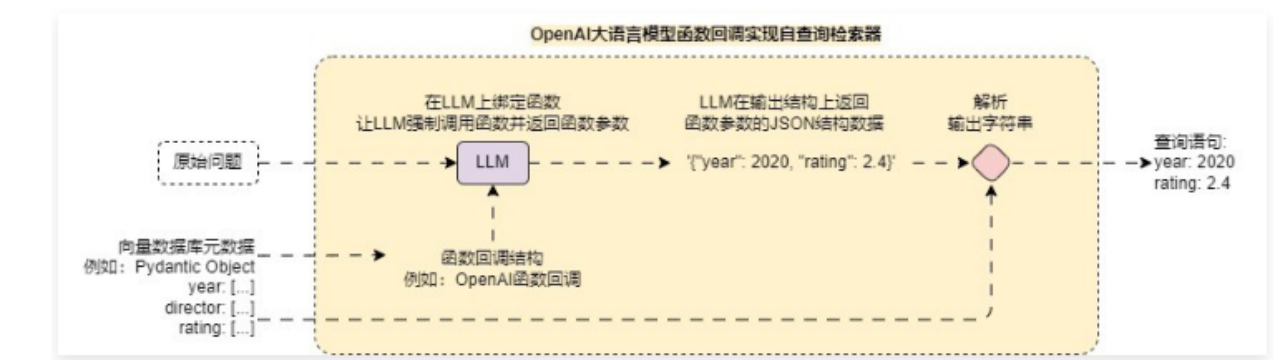
但是对于 LLM 来说,如果使用普通的 prompt 来约束输出内容的格式与规范,因为 LLM 的特性,很难保证输出格式符合特定的需求,所以可以考虑使用 函数回调 来实现,即设定一个 虚假的函数,告诉 LLM,这个函数有对应的参数,让 LLM 强制调用这个函数,这个时候 LLM 就会输出函数的调用参数,从而保证输出的统一性。
使用 函数回调 实现的检索器逻辑路由运行流程图如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from typing import Literal import dotenv from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI dotenv.load_dotenv() class RouteQuery (BaseModel ): """将用户查询映射到最相关的数据源""" datasource: Literal ["python_docs" , "js_docs" , "golang_docs" ] = Field( description="根据给定用户问题,选择哪个数据源最相关以回答他们的问题" ) def choose_route (result: RouteQuery ) -> str : """根据传递的路由结果选择不同的检索器""" if "python_docs" in result.datasource: return "chain in python_docs" elif "js_docs" in result.datasource: return "chain in js_docs" else : return "golang_docs" llm = ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) structured_llm = llm.with_structured_output(RouteQuery) prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个擅长将用户问题路由到适当的数据源的专家。\n请根据问题涉及的编程语言,将其路由到相关数据源" ), ("human" , "{question}" ) ]) router = {"question" : RunnablePassthrough()} | prompt | structured_llm | choose_route question = """为什么下面的代码不工作了,请帮我检查下: from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"]) prompt.invoke("中文")""" print (router.invoke(question))
输出:
1 2 datasource='python_docs' chain for python_docs
6.9 语义路由选择不同的 Prompt 模板 – 逻辑路由阶段 在 RAG 应用开发中,针对不同场景的问题使用 特定化的prompt模板 效果一般都会比通用模板会好一些,例如在 教培场景,制作一个可以教学 物理+数学 的授课机器人,如果使用通用的 prompt模板,会导致 prompt 编写变得非常复杂;反过来如果 prompt 写的简单,有可能没法起到很好的回复效果。代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import dotenv from langchain.utils.math import cosine_similarity from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_openai import OpenAIEmbeddings, ChatOpenAI dotenv.load_dotenv() physics_template = """你是一位非常聪明的物理教程。 你擅长以简洁易懂的方式回答物理问题。 当你不知道问题的答案时,你会坦率承认自己不知道。 这是一个问题: {query}""" math_template = """你是一位非常优秀的数学家。你擅长回答数学问题。 你之所以如此优秀,是因为你能将复杂的问题分解成多个小步骤。 并且回答这些小步骤,然后将它们整合在一起回来更广泛的问题。 这是一个问题: {query}""" embeddings = OpenAIEmbeddings(model="text-embedding-3-small" ) prompt_templates = [physics_template, math_template] prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router (input """根据传递的query计算返回不同的提示模板""" query_embedding = embeddings.embed_query(input ["query" ]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0 ] most_similar = prompt_templates[similarity.argmax()] print ("使用数学模板" if most_similar == math_template else "使用物理模板" ) return ChatPromptTemplate.from_template(most_similar) chain = ( {"query" : RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI(model="gpt-3.5-turbo-16k" ) | StrOutputParser() ) print (chain.invoke("黑洞是什么?" )) print ("======================" ) print (chain.invoke("能介绍下余弦计算公式么?" ))
6.10 自查询检索器实现动态元数据过滤 – 查询构建阶段 6.10.1 自查询检索器实现 在 RAG 应用开发中,检索外部数据时,前面的优化案例中,无论是生成的 子查询、问题分解、生成假设性文档,最后在执行检索的时候使用的都是固定的筛选条件(没有附加过滤的相似性搜索)。
但是在某些情况下,用户发起的原始提问其实隐式携带了 筛选条件,例如提问:
1 请帮我整理下关于2023年全年关于AI的新闻汇总。
在这段 原始提问 中,如果执行相应的向量数据库相似性搜索,其实是附加了 筛选条件 的,即 year=2023,但是在普通的相似性搜索中,是不会考虑 2023 年这个条件的(因为没有添加元数据过滤器,2022年和2023年数据在高维空间其实很接近),存在很大概率会将其他年份的数据也检索出来。
1 pip install --upgrade --quiet lark
定义好 带元数据的文档、支持过滤的元数据、包装的向量数据库、文档内容的描述 等信息,即可进行快速包装,示例代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 import dotenv from langchain.chains.query_constructor.schema import AttributeInfo from langchain.retrievers import SelfQueryRetriever from langchain_core.documents import Document from langchain_openai import ChatOpenAI from langchain_openai import OpenAIEmbeddings from langchain_pinecone import PineconeVectorStore dotenv.load_dotenv() documents = [ Document( page_content="肖申克的救赎" , metadata={"year" : 1994 , "rating" : 9.7 , "director" : "弗兰克·德拉邦特" }, ), Document( page_content="霸王别姬" , metadata={"year" : 1993 , "rating" : 9.6 , "director" : "陈凯歌" }, ), Document( page_content="阿甘正传" , metadata={"year" : 1994 , "rating" : 9.5 , "director" : "罗伯特·泽米吉斯" }, ), Document( page_content="泰坦尼克号" , metadat={"year" : 1997 , "rating" : 9.5 , "director" : "詹姆斯·卡梅隆" }, ), Document( page_content="千与千寻" , metadat={"year" : 2001 , "rating" : 9.4 , "director" : "宫崎骏" }, ), Document( page_content="星际穿越" , metadat={"year" : 2014 , "rating" : 9.4 , "director" : "克里斯托弗·诺兰" }, ), Document( page_content="忠犬八公的故事" , metadat={"year" : 2009 , "rating" : 9.4 , "director" : "莱塞·霍尔斯道姆" }, ), Document( page_content="三傻大闹宝莱坞" , metadat={"year" : 2009 , "rating" : 9.2 , "director" : "拉库马·希拉尼" }, ), Document( page_content="疯狂动物城" , metadat={"year" : 2016 , "rating" : 9.2 , "director" : "拜伦·霍华德" }, ), Document( page_content="无间道" , metadat={"year" : 2002 , "rating" : 9.3 , "director" : "刘伟强" }, ), ] db = PineconeVectorStore( index_name="llmops" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), namespace="dataset" , text_key="text" ) retriever = db.as_retriever() metadata_filed_info = [ AttributeInfo(name="year" , description="电影的年份" , type ="integer" ), AttributeInfo(name="rating" , description="电影的评分" , type ="float" ), AttributeInfo(name="director" , description="电影的导演" , type ="string" ), ] self_query_retriever = SelfQueryRetriever.from_llm( llm=ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ), vectorstore=db, document_contents="电影的名字" , metadata_field_info=metadata_filed_info, enable_limit=True , ) docs = self_query_retriever.invoke("查找下评分高于9.5分的电影" ) print (docs) print (len (docs)) print ("===================" ) base_docs = retriever.invoke("查找下评分高于9.5分的电影" ) print (base_docs) print (len (base_docs))
输出:
1 2 3 [Document(metadata={'director' : '陈凯歌' , 'rating' : 9.6 , 'year' : 1993.0 }, page_content='霸王别姬' ), Document(metadata={'director' : '弗兰克·德拉邦特' , 'rating' : 9.7 , 'year' : 1994.0 }, page_content='肖申克的救赎' )] 2
自查询检索器 对于面向特定领域的专用 Agent 效果相对较好 (对通用 Agent 来说效果较差 ),因为这些领域的文档一般相对来说比较规范,例如:财报、新闻、自媒体文章、教培 等行业,这些行业的数据都能剥离出通用支持过滤与筛选的 元数据/字段,使用自查询检索器能抽象出对应的检索字段信息。
6.10.2 自查询检索器执行逻辑 在 LangChain 中,涉及调用第三方服务或者调用本地自定义工具的,例如课程中学习的 自查询检索器、检索器逻辑路由 等,在底层都是通过一个预设好的 Prompt 生成符合相应规则的内容(字符串、JSON),然后通过 解析器 解析生成的内容,并将解析出来的结构化内容调用特定的接口、服务亦或者本地函数实现。原始问题如下:
生成的查询语句原文如下:
1 2 3 4 { "query" : "" , "filter" : "gt(\"rating\", 9.5)" }
接下来使用特定的转换器,将生成的查询语句转换成适配向量数据库的 过滤器,并在检索时传递该参数,从而完成自查询构建的全过程,不同的向量数据库对应的转换器差异也非常大。
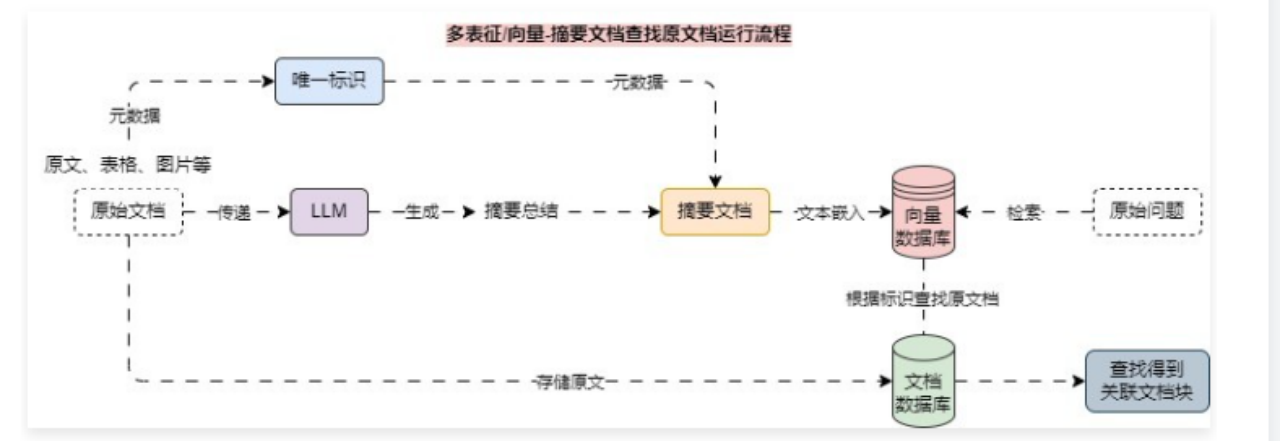
6.11 MultiVector 实现多向量检索文档 – 索引阶段 6.11.1 多表征/向量索引 如果能从多个维度记录该文档块的信息,会大大增加该文档块被检索到的概率,多个维度记录信息 等同于为文档块生成 多个向量,支持的方法如下:在检索时能提升关联文档被检索到的概率 ,多向量检索的运行流程其实也非常简单,以 摘要文档 检索 原文档 为例,运行流程图如下:
6.11.2 多向量索引示例 在 LangChain 中,为多向量索引的集成封装了 MultiVectorRetriever 类,实例化该类只需要传递 向量数据库、字节存储数据库(文档数据库)、id标识(关联标识) 即可快速完成整个运行流程的集成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import uuid import dotenv from langchain.retrievers import MultiVectorRetriever from langchain.storage import LocalFileStore from langchain_community.document_loaders import UnstructuredFileLoader from langchain_community.vectorstores import FAISS from langchain_core.documents import Document from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_text_splitters import RecursiveCharacterTextSplitter dotenv.load_dotenv() loader = UnstructuredFileLoader("./电商产品数据.txt" ) text_splitter = RecursiveCharacterTextSplitter(chunk_size=500 , chunk_overlap=50 ) docs = loader.load_and_split(text_splitter) summary_chain = ( {"doc" : lambda x: x.page_content} | ChatPromptTemplate.from_template("请总结以下文档的内容:\n\n{doc}" ) | ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) | StrOutputParser() ) summaries = summary_chain.batch(docs, {"max_concurrency" : 5 }) doc_ids = [str (uuid.uuid4()) for _ in summaries] summary_docs = [ Document(page_content=summary, metadata={"doc_id" : doc_ids[idx]}) for idx, summary in enumerate (summaries) ] byte_store = LocalFileStore("./multy-vector" ) db = FAISS.from_documents( summary_docs, embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) retriever = MultiVectorRetriever( vectorstore=db, byte_store=byte_store, id_key="doc_id" , ) retriever.docstore.mset(list (zip (doc_ids, docs))) search_docs = retriever.invoke("推荐一些潮州特产?" ) print (search_docs) print (len (search_docs))
输出:
1 2 3 [Document(metadata={'source' : './电商产品数据.txt' }, page_content='产品名称: 潮汕鱼丸\n\n电商网址: shop.example.com/fishballs\n\n产品描述: 潮汕鱼丸采用新鲜鱼肉,加入少量淀粉和调味料,手工捶打成丸,Q弹爽滑,鱼香浓郁。\n\n产品特点:\n\n原材料: 新鲜鱼肉、淀粉、盐、胡椒粉\n\n制作工艺: 传统手工捶打\n\n口感: Q弹爽滑,鲜美可口\n\n净重: 500克/袋、1000克/袋\n\n保质期: 6个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n鱼丸火锅: 搭配各类蔬菜、菌类,煮至鱼丸浮起即可。\n\n鱼丸煮汤: 与蔬菜同煮,味道鲜美。\n\n价格:\n\n500克: 55元/袋\n\n1000克: 100元/袋\n\n6. 潮汕豆腐花\n\n产品名称: 潮汕豆腐花\n\n电商网址: shop.example.com/tofupudding\n\n产品描述: 潮汕豆腐花使用优质黄豆,传统工艺制作,质地细腻,入口即化,豆香浓郁。\n\n产品特点:\n\n原材料: 黄豆、水、石膏\n\n制作工艺: 传统手工点浆\n\n口感: 细腻嫩滑,豆香浓郁\n\n净重: 450克/盒\n\n保质期: 5天(冷藏保存)' ), Document(metadata={'source' : './电商产品数据.txt' }, page_content='产品特点:\n\n原材料: 猪后腿肉、香料、盐、糖\n\n制作工艺: 精细切割,手工卷制\n\n口感: 鲜嫩多汁,咸香可口\n\n净重: 400克/袋、800克/袋\n\n保质期: 3个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n猪肉卷煎烤: 切片后煎至金黄,外脆里嫩。\n\n猪肉卷炖煮: 切块后与蔬菜同炖,风味更佳。\n\n价格:\n\n400克: 58元/袋\n\n800克: 108元/袋\n\n3. 潮汕三宝(酱油、甜醋、虾酱)\n\n产品名称: 潮汕三宝\n\n电商网址: shop.example.com/chaoshanthree\n\n产品描述: 潮汕三宝包含酱油、甜醋和虾酱。酱油由大豆、麦子自然发酵而成,甜醋以糯米酿制,虾酱选用新鲜海虾发酵,是潮汕菜肴必备调味品。\n\n产品特点:\n\n酱油: 大豆、麦子自然发酵,500ml/瓶\n\n甜醋: 糯米酿制,500ml/瓶\n\n虾酱: 新鲜海虾发酵,200克/瓶\n\n保质期: 酱油和甜醋12个月,虾酱6个月\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:' ), Document(metadata={'source' : './电商产品数据.txt' }, page_content='口感: 鲜嫩多汁,味道浓郁\n\n净重: 500克/袋、1000克/袋\n\n保质期: 3个月(冷冻保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n红烧狮子头: 加热后直接食用,适合作为主菜。\n\n狮子头炖菜: 与蔬菜同炖,味道更佳。\n\n价格:\n\n500克: 60元/袋\n\n1000克: 110元/袋\n\n10. 潮汕香菇肉酱\n\n产品名称: 潮汕香菇肉酱\n\n电商网址: shop.example.com/mushroomsauce\n\n产品描述: 潮汕香菇肉酱采用香菇和猪肉为主要原料,加入特制酱料炒制而成,香气扑鼻,味道鲜美。\n\n产品特点:\n\n原材料: 香菇、猪肉、酱料\n\n制作工艺: 精细切割,炒制均匀\n\n口感: 鲜香可口,酱香浓郁\n\n净重: 200克/瓶、400克/瓶\n\n保质期: 6个月(常温保存)\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n拌饭: 加入米饭中,提升口感。\n\n拌面: 加入面条中,风味独特。\n\n价格:\n\n200克: 35元/瓶\n\n400克: 65元/瓶' ), Document(metadata={'source' : './电商产品数据.txt' }, page_content='口感: 细腻嫩滑,豆香浓郁\n\n净重: 450克/盒\n\n保质期: 5天(冷藏保存)\n\n发货方式: 顺丰冷链配送,确保新鲜\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n甜食: 加糖水、红豆、芝麻食用。\n\n咸食: 加入虾米、葱花、酱油食用。\n\n价格: 25元/盒\n\n7. 潮汕鱼露\n\n产品名称: 潮汕鱼露\n\n电商网址: shop.example.com/fishsauce\n\n产品描述: 潮汕鱼露以新鲜小鱼为原料,经过发酵、过滤而成,味道鲜美,是潮汕菜肴必备调味品。\n\n产品特点:\n\n原材料: 小鱼、盐\n\n制作工艺: 自然发酵,传统工艺\n\n口感: 鲜美咸香\n\n净重: 500ml/瓶\n\n保质期: 12个月\n\n发货方式: 顺丰配送,确保完好\n\n物流信息: 24小时内发货,预计2\n\n3天到货\n\n推荐菜系:\n\n凉拌菜: 作为调味料使用,提升菜肴鲜味。\n\n炒菜: 适合炒菜提鲜。\n\n价格: 38元/瓶\n\n8. 潮汕糯米肠\n\n产品名称: 潮汕糯米肠\n\n电商网址: shop.example.com/glutinousrice' )] 4
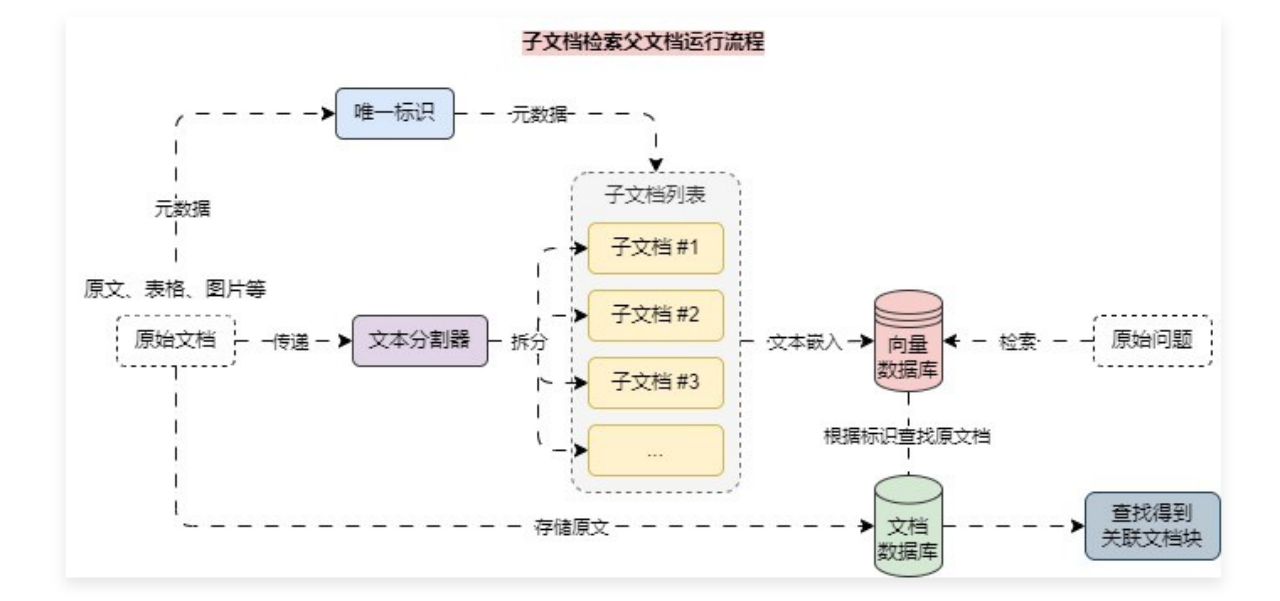
6.11.3 假设性查询检索原文档 除了使用 摘要 来检索全文,多向量检索一般还适用于 子文档检索父文档 和 假设性查询检索,其中 假设性查询检索 是利用 LLM 对切块后的文档生成多个 假设性标题,在向量数据库中存储 假设性标题 文档块,使用检索到的数据查找 原始文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from typing import List import dotenv from langchain_core.documents import Document from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_openai import ChatOpenAI dotenv.load_dotenv() class HypotheticalQuestions (BaseModel ): """生成假设性问题""" questions: List [str ] = Field( description="假设性问题列表,类型为字符串列表" , ) prompt = ChatPromptTemplate.from_template("生成一个包含3个假设性问题的列表,这些问题可以用于回答下面的文档:\n\n{doc}" ) llm = ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) structured_llm = llm.with_structured_output(HypotheticalQuestions) chain = ( {"doc" : lambda x: x.page_content} | prompt | structured_llm ) hypothetical_questions: HypotheticalQuestions = chain.invoke( Document(page_content="我叫慕小课,我喜欢打篮球,游泳" ) ) print (hypothetical_questions)
输出:
1 questions=['如果你不能打篮球,你会选择什么运动?' , '如果你不能游泳,你会选择什么运动?' , '如果你不能进行任何体育运动,你会选择什么爱好?' ]
接下来针对每个文档生成的 假设性查询 创建 Document列表,并添加 doc_id,添加到向量数据库中,并将 doc_id 与原始文档进行绑定,存储到 文档数据库/字节数据库 即可。
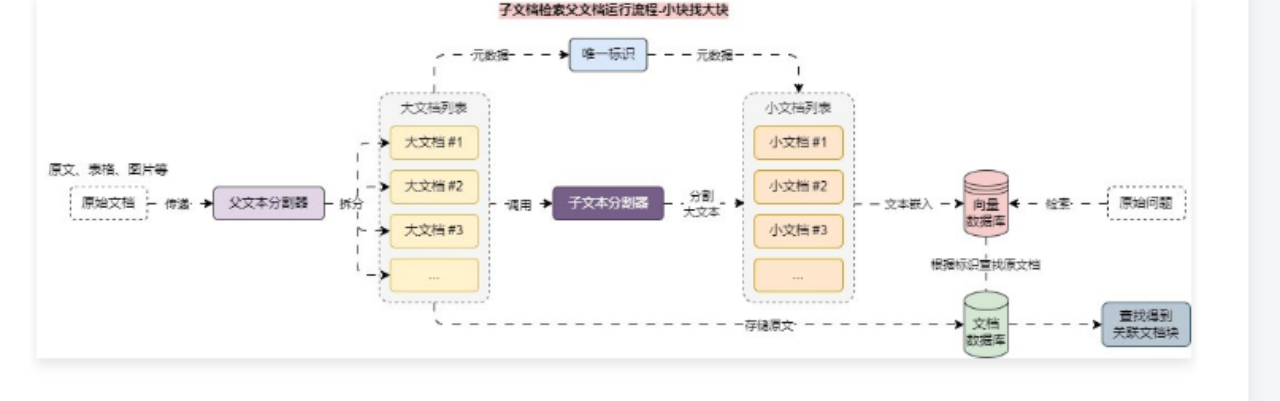
6.12 父文档检索器实现拆分和存储平衡 – 索引阶段 6.12.1 拆分文档与检索的冲突 在 RAG 应用开发中,文档拆分 和 文档检索 通常存在相互冲突的愿望,例如:
这个时候就可以考虑通过 拆分子文档块,检索 父文档块 的策略来实现这种平衡,即在检索中,首先获取小块,然后再根据小块元数据中存储的 id,使用 id 来查找这些块的父文档,并返回那些更大的文档,该策略适合一些不是特别能拆分的文档,或者是文档上下文关联性很强的场景。
请注意,这里的“父文档”指的是小块来源的文档,可以是整个原始文档,也可以是切割后比较大的文档块。
小文档块检索大文挡块,代码示例 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import dotenv import weaviate from langchain.retrievers import ParentDocumentRetriever from langchain.storage import LocalFileStore from langchain_community.document_loaders import UnstructuredFileLoader from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() loaders = [ UnstructuredFileLoader("./电商产品数据.txt" ), UnstructuredFileLoader("./项目API文档.md" ), ] docs = [] for loader in loaders: docs.extend(loader.load()) parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000 ) child_splitter = RecursiveCharacterTextSplitter(chunk_size=500 , chunk_overlap=50 ) vector_store = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="ParentDocument" , text_key="text" , embedding=OpenAIEmbeddings(model="text-embedding-3-small" ), ) store = LocalFileStore("./parent-document" ) retriever = ParentDocumentRetriever( vectorstore=vector_store, byte_store=store, parent_splitter=parent_splitter, child_splitter=child_splitter, ) retriever.add_documents(docs, ids=None ) search_docs = retriever.invoke("分享关于LLMOps的一些应用配置" ) print (search_docs) print (len (search_docs))
6.13 递归文档树检索高级RAG优化 – 索引阶段 6.13.1 RAPTOR 递归文档树策略 在传统的 RAG 中,我们通常依靠检索短的连续文本块来进行检索。但是,当我们处理的是长上下文时,我们就不能仅仅将文档分块嵌入到其中,或者仅仅使用上下文填充所有文档。相反,我们希望为 LLM 的长下文找到一种好的最小化分块方法,这就是 RAPTOR 的用武之地,在 RAPTOR 中,均衡了多文档、超长上下文、高准确性、超低成本 等特性。
RAPTOR 其实是一种用树状组织检索的递归抽象处理技术,它采用了一种自下而上的方法,通过对文本片段(块)进行聚类和归纳来形成一种分层结构,该技术在 https://arxiv.org/pdf/2401.18059 论文中被首次提出。
RAPTOR 的运行流程其实很简单,主要步骤如下:可视化其运行流程后如下:
树遍历: 方法从树的根节点开始,逐层向下进行检索,在每一层它根据查询向量与节点嵌入的余弦相似性选择最相关的前 k 个节点,然后将这些节点的子节点作为下一层的候选节点集,并重复选择过程,直到达到叶节点,最终将所有选中的节点文本进行拼接,形成检索到的上下文。折叠树: 方法会先将整个 RAPTOR 树展平为单个层,即所有节点在同一层级上进行比较,计算查询向量与所有节点嵌入的余弦相似性,并选择最相关的前 k 个节点。对于树状结构,一般的更新策略有:
6.13.2 RAPTOR 递归文档树的实现 在 LangChain 中并没有针对 RAPTOR 的实现,并且在该策略中涵盖了 高维数据降维、低维数据聚类、递归检索 等内容,对于该检索策略,目前使用得较少(更新与新增缺陷导致外挂文档增加时复杂度成倍递增),所以仅需要了解 RAPTOR 的运行流程即可。
1 pip install -U umap-learn scikit-learn tiktoken
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 from typing import Optional import dotenv import numpy as np import pandas import pandas as pd import umap import weaviate from langchain_community.document_loaders import UnstructuredFileLoader from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_huggingface import HuggingFaceEmbeddings from langchain_openai import ChatOpenAI from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_weaviate import WeaviateVectorStore from sklearn.mixture import GaussianMixture from weaviate.auth import AuthApiKey dotenv.load_dotenv() RANDOM_SEED = 224 embd = HuggingFaceEmbeddings( model_name="thenlper/gte-small" , cache_folder="./embeddings/" , encode_kwargs={"normalize_embeddings" : True }, ) model = ChatOpenAI(model="gpt-3.5-turbo-16k" , temperature=0 ) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="RaptorRAG" , text_key="text" , embedding=embd, ) def global_cluster_embeddings ( embeddings: np.ndarray, dim: int , n_neighbors: Optional [int ] = None , metric: str = "cosine" , """ 使用UMAP对传递嵌入向量进行全局降维 :param embeddings: 需要降维的嵌入向量 :param dim: 降低后的维度 :param n_neighbors: 每个向量需要考虑的邻居数量,如果没有提供默认为嵌入数量的开方 :param metric: 用于UMAP的距离度量,默认为余弦相似性 :return: 一个降维到指定维度的numpy嵌入数组 """ if n_neighbors is None : n_neighbors = int ((len (embeddings) - 1 ) ** 0.5 ) return umap.UMAP(n_neighbors=n_neighbors, n_components=dim, metric=metric).fit_transform(embeddings) def local_cluster_embeddings ( embeddings: np.ndarray, dim: int , n_neighbors: int = 10 , metric: str = "cosine" , """ 使用UMAP对嵌入进行局部降维处理,通常在全局聚类之后进行。 :param embeddings: 需要降维的嵌入向量 :param dim: 降低后的维度 :param n_neighbors: 每个向量需要考虑的邻居数量 :param metric: 用于UMAP的距离度量,默认为余弦相似性 :return: 一个降维到指定维度的numpy嵌入数组 """ return umap.UMAP( n_neighbors=n_neighbors, n_components=dim, metric=metric, ).fit_transform(embeddings) def get_optimal_clusters ( embeddings: np.ndarray, max_clusters: int = 50 , random_state: int = RANDOM_SEED, int : """ 使用高斯混合模型结合贝叶斯信息准则(BIC)确定最佳的聚类数目。 :param embeddings: 需要聚类的嵌入向量 :param max_clusters: 最大聚类数 :param random_state: 随机数 :return: 返回最优聚类数 """ max_clusters = min (max_clusters, len (embeddings)) n_clusters = np.arange(1 , max_clusters) bics = [] for n in n_clusters: gm = GaussianMixture(n_components=n, random_state=random_state) gm.fit(embeddings) bics.append(gm.bic(embeddings)) return n_clusters[np.argmin(bics)] def gmm_cluster (embeddings: np.ndarray, threshold: float , random_state: int = 0 ) -> tuple [list , int ]: """ 使用基于概率阈值的高斯混合模型(GMM)对嵌入进行聚类。 :param embeddings: 需要聚类的嵌入向量(降维) :param threshold: 概率阈值 :param random_state: 用于可重现的随机性种子 :return: 包含聚类标签和确定聚类数目的元组 """ n_clusters = get_optimal_clusters(embeddings) gm = GaussianMixture(n_components=n_clusters, random_state=random_state) gm.fit(embeddings) probs = gm.predict_proba(embeddings) labels = [np.where(prob > threshold)[0 ] for prob in probs] return labels, n_clusters def perform_clustering (embeddings: np.ndarray, dim: int , threshold: float ) -> list [np.ndarray]: """ 对嵌入进行聚类,首先全局降维,然后使用高斯混合模型进行聚类,最后在每个全局聚类中进行局部聚类。 :param embeddings: 需要执行操作的嵌入向量列表 :param dim: 指定的降维维度 :param threshold: 概率阈值 :return: 包含每个嵌入的聚类ID的列表,每个数组代表一个嵌入的聚类标签。 """ if len (embeddings) <= dim + 1 : return [np.array([0 ]) for _ in range (len (embeddings))] reduced_embeddings_global = global_cluster_embeddings(embeddings, dim) global_clusters, n_global_clusters = gmm_cluster(reduced_embeddings_global, threshold) all_local_clusters = [np.array([]) for _ in range (len (embeddings))] total_clusters = 0 for i in range (n_global_clusters): global_cluster_embeddings_ = embeddings[ np.array([i in gc for gc in global_clusters]) ] if len (global_cluster_embeddings_) == 0 : continue if len (global_cluster_embeddings_) <= dim + 1 : local_clusters = [np.array([0 ]) for _ in global_cluster_embeddings_] n_local_clusters = 1 else : reduced_embeddings_local = local_cluster_embeddings(global_cluster_embeddings_, dim) local_clusters, n_local_clusters = gmm_cluster(reduced_embeddings_local, threshold) for j in range (n_local_clusters): local_cluster_embeddings_ = global_cluster_embeddings_[ np.array([j in lc for lc in local_clusters]) ] indices = np.where( (embeddings == local_cluster_embeddings_[:, None ]).all (-1 ) )[1 ] for idx in indices: all_local_clusters[idx] = np.append(all_local_clusters[idx], j + total_clusters) total_clusters += n_local_clusters return all_local_clusters def embed (texts: list [str ] ) -> np.ndarray: """ 将传递的的文本列表转换成嵌入向量列表 :param texts: 需要转换的文本列表 :return: 生成的嵌入向量列表并转换成numpy数组 """ text_embeddings = embd.embed_documents(texts) return np.array(text_embeddings) def embed_cluster_texts (texts: list [str ] ) -> pandas.DataFrame: """ 对文本列表进行嵌入和聚类,并返回一个包含文本、嵌入和聚类标签的数据框。 该函数将嵌入生成和聚类结合成一个步骤。 :param texts: 需要处理的文本列表 :return: 返回包含文本、嵌入和聚类标签的数据框 """ text_embeddings_np = embed(texts) cluster_labels = perform_clustering(text_embeddings_np, 10 , 0.1 ) df = pd.DataFrame() df["text" ] = texts df["embd" ] = list (text_embeddings_np) df["cluster" ] = cluster_labels return df def fmt_txt (df: pd.DataFrame ) -> str : """ 将数据框中的文本格式化成单个字符串 :param df: 需要处理的数据框,内部涵盖text、embd、cluster三个字段 :return: 返回合并格式化后的字符串 """ unique_txt = df["text" ].tolist() return "--- --- \n --- ---" .join(unique_txt) def embed_cluster_summarize_texts (texts: list [str ], level: int ) -> tuple [pd.DataFrame, pd.DataFrame]: """ 对传入的文本列表进行嵌入、聚类和总结。 该函数首先问文本生成嵌入,基于相似性对他们进行聚类,扩展聚类分配以便处理,然后总结每个聚类中的内容。 :param texts: 需要处理的文本列表 :param level: 一个整数,可以定义处理的深度 :return: 包含两个数据框的元组 - 第一个 DataFrame (df_clusters) 包括原始文本、它们的嵌入以及聚类分配。 - 第二个 DataFrame (df_summary) 包含每个聚类的摘要信息、指定的处理级别以及聚类标识符。 """ df_clusters = embed_cluster_texts(texts) expanded_list = [] for index, row in df_clusters.iterrows(): for cluster in row["cluster" ]: expanded_list.append( {"text" : row["text" ], "embd" : row["embd" ], "cluster" : cluster} ) expanded_df = pd.DataFrame(expanded_list) all_clusters = expanded_df["cluster" ].unique() template = """Here is a sub-set of LangChain Expression Language doc. LangChain Expression Language provides a way to compose chain in LangChain. Give a detailed summary of the documentation provided. Documentation: {context} """ prompt = ChatPromptTemplate.from_template(template) chain = prompt | model | StrOutputParser() summaries = [] for i in all_clusters: df_cluster = expanded_df[expanded_df["cluster" ] == i] formatted_txt = fmt_txt(df_cluster) summaries.append(chain.invoke({"context" : formatted_txt})) df_summary = pd.DataFrame( { "summaries" : summaries, "level" : [level] * len (summaries), "cluster" : list (all_clusters), } ) return df_clusters, df_summary def recursive_embed_cluster_summarize ( texts: list [str ], level: int = 1 , n_levels: int = 3 , dict [int , tuple [pd.DataFrame, pd.DataFrame]]: """ 递归地嵌入、聚类和总结文本,直到达到指定的级别或唯一聚类数变为1,将结果存储在每个级别处。 :param texts: 要处理的文本列表 :param level: 当前递归级别(从1开始) :param n_levels: 递归地最大深度(默认为3) :return: 一个字典,其中键是递归级别,值是包含该级别处聚类DataFrame和总结DataFrame的元组。 """ results = {} df_clusters, df_summary = embed_cluster_summarize_texts(texts, level) results[level] = (df_clusters, df_summary) unique_clusters = df_summary["cluster" ].nunique() if level < n_levels and unique_clusters > 1 : new_texts = df_summary["summaries" ].tolist() next_level_results = recursive_embed_cluster_summarize( new_texts, level + 1 , n_levels ) results.update(next_level_results) return results loaders = [ UnstructuredFileLoader("./流浪地球.txt" ), UnstructuredFileLoader("./电商产品数据.txt" ), UnstructuredFileLoader("./项目API文档.md" ), ] text_splitter = RecursiveCharacterTextSplitter( chunk_size=500 , chunk_overlap=0 , separators=["\n\n" , "\n" , "。|!|?" , "\.\s|\!\s|\?\s" , ";|;\s" , ",|,\s" , " " , "" ], is_separator_regex=True , ) docs = [] for loader in loaders: docs.extend(loader.load_and_split(text_splitter)) leaf_texts = [doc.page_content for doc in docs] results = recursive_embed_cluster_summarize(leaf_texts, level=1 , n_levels=3 ) all_texts = leaf_texts.copy() for level in sorted (results.keys()): summaries = results[level][1 ]["summaries" ].tolist() all_texts.extend(summaries) db.add_texts(all_texts) retriever = db.as_retriever(search_type="mmr" ) search_docs = retriever.invoke("流浪地球中的人类花了多长时间才流浪到新的恒星系?" ) print (search_docs) print (len (search_docs))
输出:
1 2 3 [Document(page_content='我们的船继续航行,到了地球黑夜的部分,在这里,阳光和地球发动机的光柱都照不到,在大西洋清凉的海风中,我们这些孩子第一次看到了星空。天啊,那是怎样的景象啊,美得让我们心醉。小星老师一手搂着我们,一手指着星空,看,孩子们,那就是半人马座,那就是比邻星,那就是我们的新家!说完她哭了起来,我们也都跟着哭了,周围的水手和船长,这些铁打的汉子也流下了眼泪。所有的人都用泪眼探望着老师指的方向,星空在泪水中扭曲抖动,唯有那个星星是不动的,那是黑夜大海狂浪中远方陆地的灯塔,那是冰雪荒原中快要冻死的孤独旅人前方隐现的火光,那是我们心中的太阳,是人类在未来一百代人的苦海中惟一的希望和支撑……\n\n在回家的航程中,我们看到了启航的第一个信号:夜空中出现了一个巨大的彗星,那是月球。人类带不走月球,就在月球上也安装了行星发动机,把它推离地球轨道,以免在地球加速时相撞。月球上行星发动机产生的巨大彗尾使大海笼罩在一片蓝光之中,群星看不见了。月球移动产生的引力潮汐使大海巨浪冲天,我们改乘飞机向南半球的家飞去。\n\n启航的日子终于到了!' ), Document(page_content='离开木星时,地球已达到了逃逸速度,它不再需要返回潜藏着死亡的太阳,向广漠的外太空飞去,漫长的流浪时代开始了。\n\n就在木星暗红色的阴影下,我的儿子在地层深处出生了。\n\n第3章 叛乱\n\n离开木星后,亚洲大陆上一万多台地球发动机再次全功率开动,这一次它们要不停地运行500年,不停地加速地球。这500年中,发动机将把亚洲大陆上一半的山脉用做燃料消耗掉。\n\n从四个多世纪死亡的恐惧中解脱出来,人们长出了一口气。但预料中的狂欢并没有出现,接下来发生的事情出乎所有人的想像。\n\n在地下城的庆祝集会后,我一个人穿上密封服来到地面。童年时熟悉的群山已被超级挖掘机夷为平地,大地上只有裸露的岩石和坚硬的冻土,冻土上到处有白色的斑块,那是大海潮留下的盐渍。面前那座爷爷和爸爸度过了一生的曾有千万人口的大城市现在已是一片废墟,高楼钢筋外露的残骸在地球发动机光柱的蓝光中拖着长长的影子,好像是史前巨兽的化石……一次次的洪水和小行星的撞击已摧毁了地面上的一切,各大陆上的城市和植被都荡然无存,地球表面已变成火星一样的荒漠。' ), Document(page_content='“可老师,我们来不及的,地球来不及的,它还来不及加速到足够快,航行足够远,太阳就爆炸了!”\n\n“时间是够的,要相信联合政府!这我说了多少遍,如果你们还不相信,我们就退一万步说:人类将自豪地去死,因为我们尽了最大的努力!”\n\n人类的逃亡分为五步:第一步,用地球发动机使地球停止转动,使发动机喷口固定在地球运行的反方向;第二步,全功率开动地球发动机,使地球加速到逃逸速度,飞出太阳系;第三步,在外太空继续加速,飞向比邻星;第四步,在中途使地球重新自转,掉转发动机方向,开始减速;第五步,地球泊入比邻星轨道,成为这颗恒星的卫星。人们把这五步分别称为刹车时代、逃逸时代、流浪时代I(加速)、流浪时代II(减速)、新太阳时代。\n\n整个移民过程将延续两千五百年时间,一百代人。' ), Document(page_content='我们很快到达了海边,看到城市摩天大楼的尖顶伸出海面,退潮时白花花的海水从大楼无数的窗子中流出,形成一道道瀑布……刹车时代刚刚结束,其对地球的影响已触目惊心:地球发动机加速造成的潮汐吞没了北半球三分之二的大城市,发动机带来的全球高温融化了极地冰川,更给这大洪水推波助澜,波及到南半球。爷爷在三十年前亲眼目睹了百米高的巨浪吞没上海的情景,他现在讲这事的时候眼还直勾勾的。事实上,我们的星球还没启程就已面目全非了,谁知道在以后漫长的外太空流浪中,还有多少苦难在等着我们呢?' )] 4
6.13.3 索引阶段优化策略总结 索引阶段优化策略 涵盖了 分割策略(语义分割、递归字符分割)、多向量/表征检索、RAPTOR递归文档树检索,其中 特定Embeddings 即考虑使用维度更高的文本嵌入模型,并没有复杂的使用技巧。
6.14 ReRank 重排序提升RAG系统 – 筛选阶段 6.14.1 ReRank 重排序 进一步优化筛选阶段,一般涵盖了 重排序、纠正性RAG 两种策略,其中 重排序 是使用频率最高,性价比最高,通常与 混合检索 一起搭配使用,也是目前主流的优化策略(Dify、Coze、智谱、绝大部分开源 Agent 项目都在使用)。
在 LangChain 中,使用重排工具很简单,可以单独使用,也可以利用 ContextualCompressionRetriever 检索器进行二次包装合并,并传递检索器+重排工具,这样检索输出得到的结果就是经过重排的了。
6.14.2 Cohere 重排序 目前可用的重新排序模型并不多,一种是选择 Cohere 提供的在线模型,可以通过 API 访问,此外还有一些开源模型,如:bge-rerank-base 和 bge-rerank-large 等,体验与评分最好的是 Cohere 的在线模型,不过它是一项付费服务(注册账号提供免费额度),并且由于 Cohere 服务部署在海外,国内访问速度并没有这么快。
对于学习,我们可以使用 Cohere 的在线模型,如果是部署企业内部的服务,可以使用 bge-rerank-large,链接如下:https://cohere.com/ https://huggingface.co/BAAI/bge-reranker-large
安装依赖:
1 pip install langchain-cohere
在 weaviate 向量数据库中,使用 Cohere 在线模型集成重排序示例代码(使用 weaviate 数据库的 DatasetDemo 集合,存储了 项目API文档.md 文档的内容,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import dotenv import weaviate from langchain.retrievers import ContextualCompressionRetriever from langchain_cohere import CohereRerank from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore from weaviate.auth import AuthApiKey dotenv.load_dotenv() embedding = OpenAIEmbeddings(model="text-embedding-3-small" ) db = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud" , auth_credentials=AuthApiKey("ZltPVa9ZSOxUcfafelsggGyyH6tnTYQYJvBx" ), ), index_name="DatasetDemo" , text_key="text" , embedding=embedding, ) rerank = CohereRerank(model="rerank-multil ingual-v3.0" ) retriever = ContextualCompressionRetriever( base_retriever=db.as_retriever(search_type="mmr" ), base_compressor=rerank, ) search_docs = retriever.invoke("关于LLMOps应用配置的信息有哪些呢?" ) print (search_docs) print (len (search_docs))
输出 :
1 2 3 [Document(metadata={'source' : './项目API文档.md' , 'start_index' : 2324.0, 'relevance_score' : 0.9298237}, page_content='json { "code": "success", "data": { "id": "5e7834dc-bbca-4ee5-9591-8f297f5acded", "name": "慕课LLMOps聊天机器人", "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/23/e4422149-4cf7-41b3-ad55-ca8d2caa8f13.png", "description": "这是一个慕课LLMOps的Agent应用", "published_app_config_id": null, "drafted_app_config_id": null, "debug_conversation_id": "1550b71a-1444-47ed-a59d-c2f080fbae94", "published_app_config": null, "drafted_app_config": { "id": "755dc464-67cd-42ef-9c56-b7528b44e7c8"' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 0.0, 'relevance_score' : 0.7358315}, page_content='LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字段:code、data 和 message,分别代表业务状态码、业务数据和接口附加信息。\n\n业务状态码共有 6 种,其中只有 success(成功) 代表业务操作成功,其他 5 种状态均代表失败,并且失败时会附加相关的信息:fail(通用失败)、not_found(未找到)、unauthorized(未授权)、forbidden(无权限)和validate_error(数据验证失败)。\n\n接口示例:\n\njson { "code": "success", "data": { "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail" }, "message": "" }' ), Document(metadata={'source' : './项目API文档.md' , 'start_index' : 675.0, 'relevance_score' : 0.098772585}, page_content='json { "code": "success", "data": { "list": [ { "app_count": 0, "created_at": 1713105994, "description": "这是专门用来存储慕课LLMOps课程信息的知识库", "document_count": 13, "icon": "https://imooc-llmops-1257184990.cos.ap-guangzhou.myqcloud.com/2024/04/07/96b5e270-c54a-4424-aece-ff8a2b7e4331.png", "id": "c0759ca8-2d35-4480-83a8-1f41f29d1401", "name": "慕课LLMOps课程知识库", "updated_at": 1713106758, "word_count": 8850 } ], "paginator": { "current_page": 1, "page_size": 20, "total_page": 1, "total_record": 2 } }' )] 3
通过 LangSmith 观察该检索器的运行流程,可以发现,原始检索器找到了 4 条数据,但是经过重排序后,只返回了相关性高的 3 条(可设置),有一条被剔除了,这也是 压缩器 和 文档转换器 的区别(不过在旧版本的 LangChain 中,两个没有区别,所以在很多文档转换器的文档中都可以看到压缩器的存在)。
6.15 纠正性索引增强生成 CRAG 优化策略 6.15.1 纠正性检索增强 纠正性检索增强生成(Corrective Retrieval-Augmented Generation,CRAG)是一种先进的自然语言处理技术,旨在提高检索的生成方法的鲁棒性和准确性。在 CRAG 中引入了一个轻量级的检索评估器来评估检索到的文档的质量,并根据评估结果触发不同的知识检索动作,以确保生成结果的准确性。
1. 检索文档 :首先,基于用户的查询,系统执行检索操作以获取相关的文档或信息。评估检索质量 :CRAG 使用一个轻量级的检索评估器对检索到的每个文档进行质量评估,计算出一个量化的置信度分数。触发知识检索动作 :根据置信度分数,CRAG 将触发以下二个动作之一:正确 :如果评估器认为文档与查询高度相关,将采用该文档进行知识精炼。错误 :如果文档被评估为不相关或误导性,CRAG将利用网络搜索寻找更多知识来源。知识精炼 :对于评估为正确的文档,CRAG将进行知识精炼,抽取关键信息并过滤掉无关信息。网络搜索 :在需要时,CRAG会执行网络搜索以寻找更多高质量的知识来源,以纠正或补充检索结果。分解-重组 :CRAG采用一种分解-重组算法,将检索到的文档解构为关键信息块,筛选重要信息,并重新组织成结构化知识。生成文本 :最后,利用经过优化和校正的知识,传递给 LLM,生成对应文本。
运行流程如下:
需要借助 LangGraph 实现循环处理
6.16 使用 Self-RAG 纠正低质量的检索生成 这里我们从一个常见的生活场景入手——参加开卷考试,一般来说我们通常会采用以下两种作答策略:
· 方法一:对于熟悉的题目,直接快速作答;对于不熟悉的题目,快速翻阅参考书,找到相关部分,在脑海中整理分类和总结后,再在试卷上作答。
显然,方法一 大家用的更多一些,是首选方法。方法二不仅耗时,还有可能引入无关的或错误的信息,导致出现混淆和错误,甚至在考生原本擅长的领域也不例外。直接输出答案、重新检索、剔除不相关的内容、检测生成内容是否存在幻觉、检测生成内容是否有帮助 等,可以把 Self-RAG 看成是一个拥有自我反思能力的智能体,这个智能体主要用来依据相关知识库回复用户问题,自我迭代,直到输出满意的结果。
一个 Self-RAG 应用主要有三大步骤组成:
拆分成流程图后,Self-RAG 的运行流程如下:
在 LangChain 官网的示例中,提供了一个 Self-RAG 的 LangSmith 日志运行流程,我们可以通过这个日志的运行流程来深入理解。https://smith.langchain.com/public/55d6180f-aab8-42bc-8799-dadce6247d9b/r