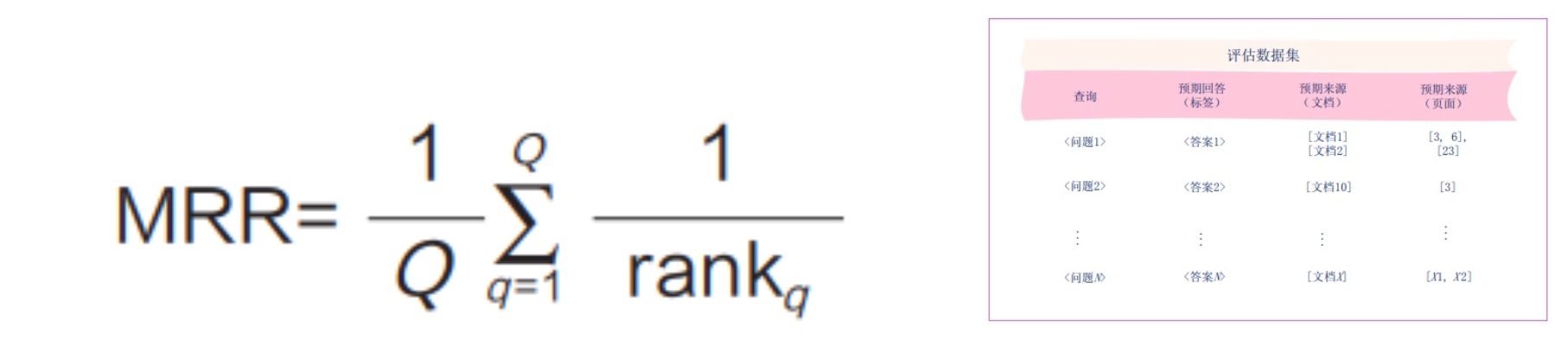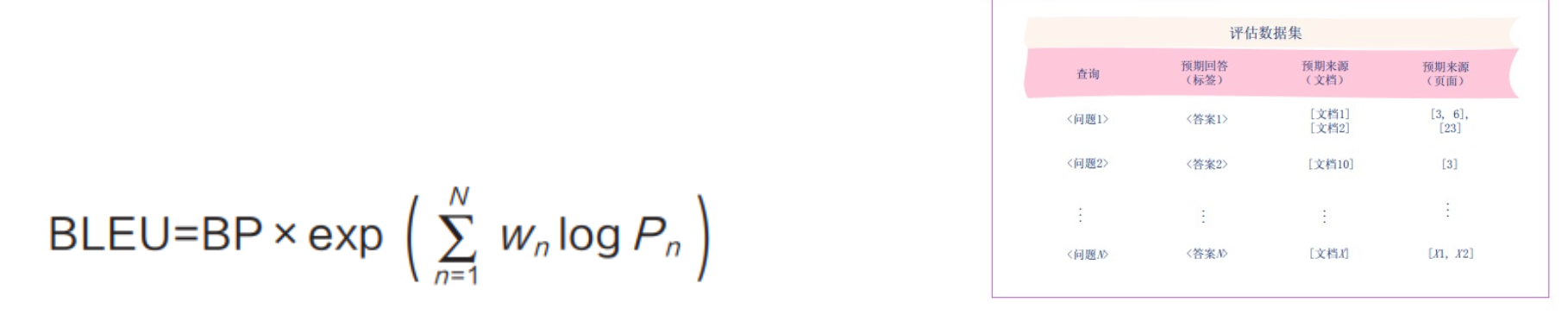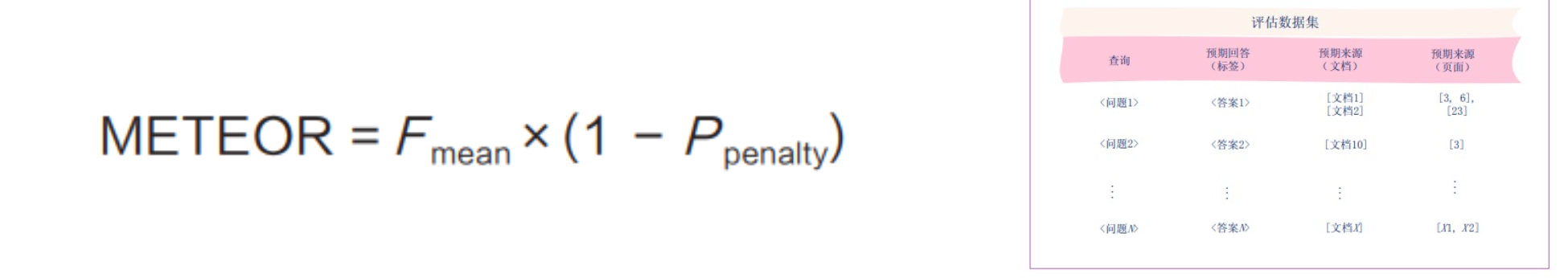P@K 衡量的是前 K 个检索结果的精确率,确保在展示的前几项结果中尽可能多地包含相关信息。 其中,分子表示前 K 个结果中相关文档的数量,分母中的 K 是固定的返回数量。P@K 在用户特别关注前几项结果的场景中非常有用。例如,在新闻搜索系统中, P@K 可以确保用户在进行搜索时,查到的前几条新闻与查询主题高度相关,从而提升阅 读效率。
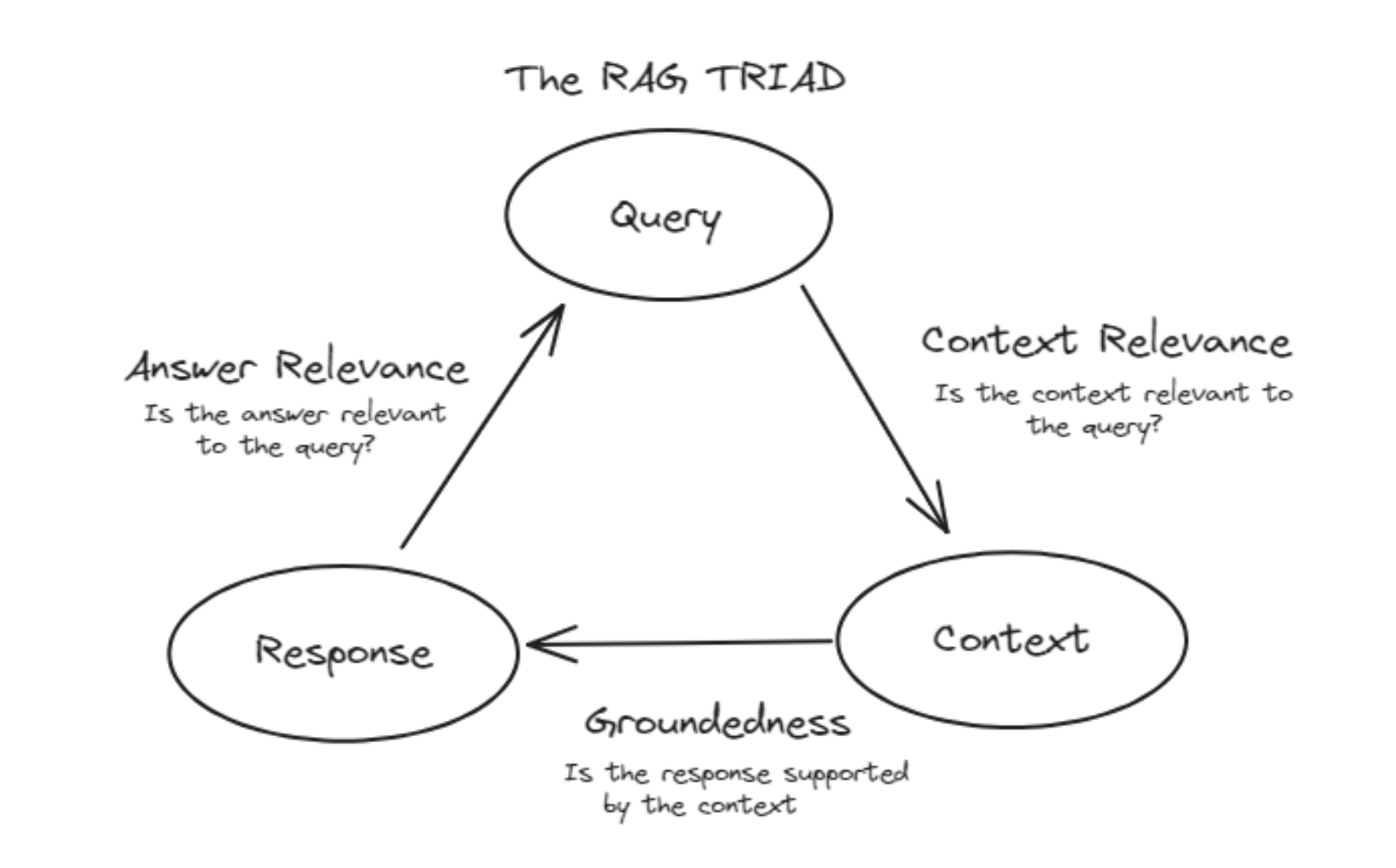
13.2.7 总结
指标
衡量内容
计算方法
回答的问题
精确率
检索结果的准确性
相关文档块数 / 检索到的总文档块数
在系统检索的所有文档块中,有多少是真正相关的?
召回率
检索结果的完整性
检索到的相关文档块数 / 数据库中所有相关文档块数
在数据库中所有的相关文档块中,系统成功检索到了多少?
F1分数
精确率与召回率的平衡
2 * (精确率 * 召回率) / (精确率 + 召回率)
系统的精确性和完整性如何均衡?
平均倒数排名
系统快速检索到第一个相关文档块的能力
对多个查询的倒数排名取平均值
平均而言,系统多快能检索到第一个相关文档块?
平均精确率
精确性和相关文档块排序的综合评估
对多个查询的平均精确率取平均值
平均而言,系统检索的排名靠前的文档块有多精确?
P@K
前K个检索结果的精确度
前K个结果中的相关文档块数量 / K
在前K个检索结果中,有多少是相关的?
13.3 生成器的评估指标
响应评估:语义相似度、忠实度等
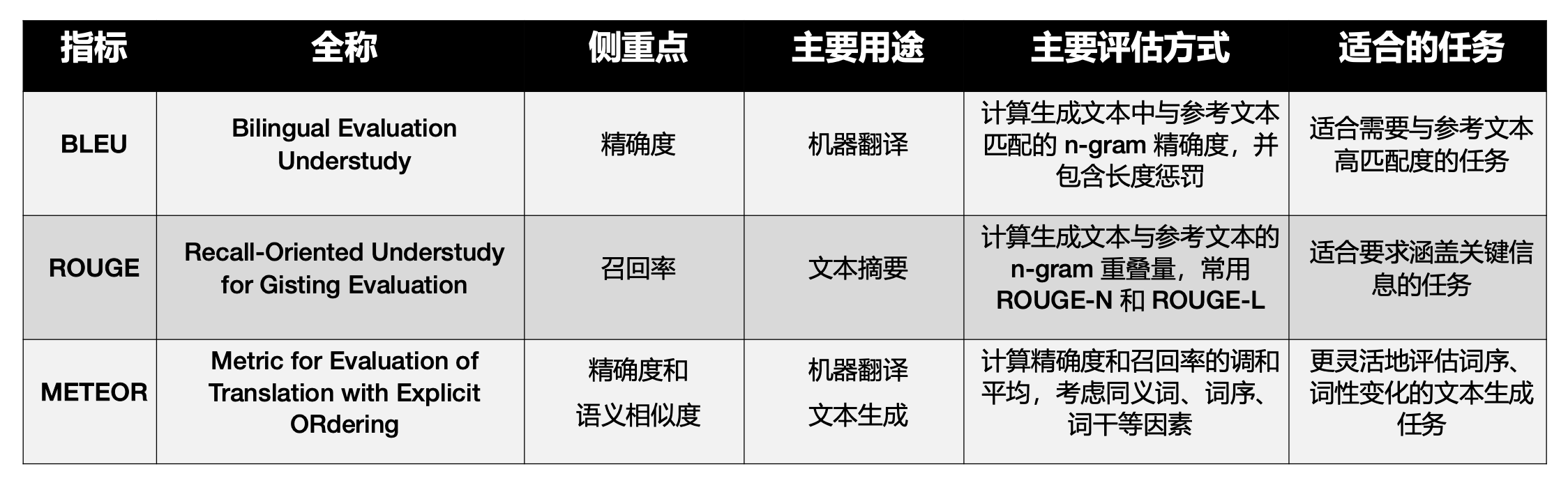
13.3.1 基于n-gram匹配程度的指标:BLEU
BLEU(Bilingual Evaluation Understudy,可译为“双语评估替代工具”)用于评 估生成的回答与参考答案之间 n-gram 的重叠情况,强调精确率。它通过 n-gram(即连 续的 n 个 token 构成的序列,n 可以为 1、2、3、4 等)的精确匹配来计算分数。 其中,BP 是长度惩罚(Brevity Penalty),用于防止生成的回答过短。若生成的回 答比参考答案短,则 BP 小于 1;否则,BP 等于 1。P n 是 n -gram 的精确率。w n 是每 个 n-gram 的权重,通常 w 1、w 2、w 3 和 w 4 的值相等。 例如,假设参考答案为“the cat is on mat”,而生成的回答为“the cat on mat”。 对 于BLEU-1(1-gram 精 确 度 ),1-gram( 单 词 ) 匹 配 项 包 括 “the”“cat”“on”“mat”4 个。生成的回答中有 4 个 1-gram。因此,1-gram 精确率 1。
13.3.2 基于n-gram匹配程度的指标:ROUGE
ROUGE(Recall-Oriented Understudy for Gisting Evaluation,一般译为“面 向召回的摘要评估替代工具”)用于计算生成的回答与参考答案之间 n-g ram 的重叠量, 并同时考虑了精确率和召回率,提供了较为平衡的评价方式。 继续使用前面的示例,假设参考答案为“the cat is on mat” ,而生成回答为“the cat on mat”。 对于 ROUGE-1(即 1-gram),匹配项包括“the”“cat”“on”和“mat”4 个。参考答案中有 5 个 1-gram。因此,ROUGE-1 为 0.8。 对于 ROUGE-2(即 2-gram),匹配项包括“the cat”和“on mat”2 个。参考 答案中有 4 个 2-gram。因此,ROUGE-2 为 0.5。
13.3.3 基于n-gram匹配程度的指标:METEOR
METEOR(Metric for Evaluation of Translation with Explicit Ordering,一般 译为“具有显式排序的翻译评估指标”)通过考量同义词、词干和词序等因素,提供了对 生成的回答与参考答案之间相似度更细致的评估。它不仅计算精确率和召回率的调和平均 值(F mean),还结合了一个惩罚机制来处理词序错误和其他不匹配的情况。METEOR 能 够比 BLEU 和 ROUGE 更好地捕捉语义特性。 其中,F mean 是精确度和召回率的调和平均值,用于综合衡量生成的回答与参考答案 的匹配程度。P penalty 是一个惩罚项,用于惩罚词序错误及其他类型的错误。
import os from dotenv import load_dotenv load_dotenv() import numpy as np from datasets import Dataset from ragas.metrics import Faithfulness, AnswerRelevancy from ragas.llms import LangchainLLMWrapper from ragas.embeddings import LangchainEmbeddingsWrapper from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_huggingface import HuggingFaceEmbeddings from ragas import evaluate from langchain_deepseek import ChatDeepSeek # 准备评估用的LLM(使用GPT-3.5) llm_deepseek = ChatDeepSeek(model="Pro/deepseek-ai/DeepSeek-V3", api_key=os.getenv("LLM_API_KEY"), api_base=os.getenv("LLM_BASE_URL")) llm = LangchainLLMWrapper(llm_deepseek) # llm = LangchainLLMWrapper(ChatOpenAI(model_name="gpt-3.5-turbo")) # 准备数据集 data = { "question": [ "Who is the main character in Black Myth: Wukong?", "What are the special features of the combat system in Black Myth: Wukong?", "How is the visual quality of Black Myth: Wukong?", ], "answer": [ "The main character in Black Myth: Wukong is Sun Wukong, based on the Chinese classic 'Journey to the West' but with a new interpretation. This version of Sun Wukong is more mature and brooding, showing a different personality from the traditional character.", "Black Myth: Wukong's combat system combines Chinese martial arts with Soulslike game features, including light and heavy attack combinations, technique transformations, and magic systems. Notably, Wukong can transform between different weapon forms during combat, such as his iconic staff and nunchucks, and use various mystical abilities.", "Black Myth: Wukong is developed using Unreal Engine 5, showcasing stunning visual quality. The game's scene modeling, lighting effects, and character details are all top-tier, particularly in its detailed recreation of traditional Chinese architecture and mythological settings.", ], "contexts": [ [ "Black Myth: Wukong is an action RPG developed by Game Science, featuring Sun Wukong as the protagonist based on 'Journey to the West' but with innovative interpretations. In the game, Wukong has a more composed personality and carries a special mission.", "The game is set in a mythological world, telling a new story that presents a different take on the traditional Sun Wukong character." ], [ "The game's combat system is heavily influenced by Soulslike games while incorporating traditional Chinese martial arts elements. Players can utilize different weapon forms, including the iconic staff and other transforming weapons.", "During combat, players can unleash various mystical abilities, combined with light and heavy attacks and combo systems, creating a fluid and distinctive combat experience. The game also features a unique transformation system." ], [ "Black Myth: Wukong demonstrates exceptional visual quality, built with Unreal Engine 5, achieving extremely high graphical fidelity. The game's environments and character models are meticulously crafted.", "The lighting effects, material rendering, and environmental details all reach AAA-level standards, perfectly capturing the atmosphere of an Eastern mythological world." ] ] } dataset = Dataset.from_dict(data) print("\n=== Ragas评估指标说明 ===") print("\n1. Faithfulness(忠实度)") print("- 评估生成的答案是否忠实于上下文内容") print("- 通过将答案分解为简单陈述,然后验证每个陈述是否可以从上下文中推断得出") print("- 该指标仅依赖LLM,不需要embedding模型") # 评估Faithfulness faithfulness_metric = [Faithfulness(llm=llm)] # 只需要提供生成模型 print("\n正在评估忠实度...") faithfulness_result = evaluate(dataset, faithfulness_metric) scores = faithfulness_result['faithfulness'] mean_score = np.mean(scores) ifisinstance(scores, (list, np.ndarray)) else scores print(f"忠实度评分: {mean_score:.4f}") # print("\n2. AnswerRelevancy(答案相关性)") # print("- 评估生成的答案与问题的相关程度") # print("- 使用embedding模型计算语义相似度") # print("- 我们将比较开源embedding模型和OpenAI的embedding模型") # 设置两种embedding模型 opensource_embedding = LangchainEmbeddingsWrapper( HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") ) openai_embedding = LangchainEmbeddingsWrapper(OpenAIEmbeddings(model="text-embedding-ada-002")) # 创建答案相关性评估指标 opensource_relevancy = [AnswerRelevancy(llm=llm, embeddings=opensource_embedding)] openai_relevancy = [AnswerRelevancy(llm=llm, embeddings=openai_embedding)] print("\n正在评估答案相关性...") print("\n使用开源Embedding模型评估:") opensource_result = evaluate(dataset, opensource_relevancy) scores = opensource_result['answer_relevancy'] opensource_mean = np.mean(scores) ifisinstance(scores, (list, np.ndarray)) else scores print(f"相关性评分: {opensource_mean:.4f}") print("\n使用OpenAI Embedding模型评估:") openai_result = evaluate(dataset, openai_relevancy) scores = openai_result['answer_relevancy'] openai_mean = np.mean(scores) ifisinstance(scores, (list, np.ndarray)) else scores print(f"相关性评分: {openai_mean:.4f}") # 比较两种embedding模型的结果 print("\n=== Embedding模型比较 ===") diff = openai_mean - opensource_mean print(f"开源模型评分: {opensource_mean:.4f}") print(f"OpenAI模型评分: {openai_mean:.4f}") print(f"差异: {diff:.4f} ({'OpenAI更好'if diff > 0else'开源模型更好'if diff < 0else'相当'})") ''' 我做了以下修改: 移除了 ragas.embeddings.base 中的 HuggingfaceEmbeddings 导入 改为导入 LangChain 的 HuggingFaceEmbeddings使用 LangchainEmbeddingsWrapper 来包装 LangChain 的 HuggingFaceEmbeddings这样做的原因是: LangChain 的 HuggingFaceEmbeddings 是一个完整的实现,包含了所有必要的方法 LangchainEmbeddingsWrapper 会将 LangChain 的嵌入模型适配到 RAGAS 的接口 这个包装器会自动处理同步和异步方法的转换 1. Faithfulness(忠实度) - 评估生成的答案是否忠实于上下文内容 - 通过将答案分解为简单陈述,然后验证每个陈述是否可以从上下文中推断得出 - 该指标仅依赖LLM,不需要embedding模型 正在评估忠实度... Evaluating: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:05<00:00, 1.87s/it] 忠实度评分: 0.6071 正在评估答案相关性... 使用开源Embedding模型评估: Evaluating: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:01<00:00, 1.54it/s] 相关性评分: 0.8565 使用OpenAI Embedding模型评估: Evaluating: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:06<00:00, 2.11s/it] 相关性评分: 0.9426 === Embedding模型比较 ===开源模型评分: 0.8565 OpenAI模型评分: 0.9426 差异: 0.0861 (OpenAI更好) '''