eBPF核心技术与实战
0 参考资料
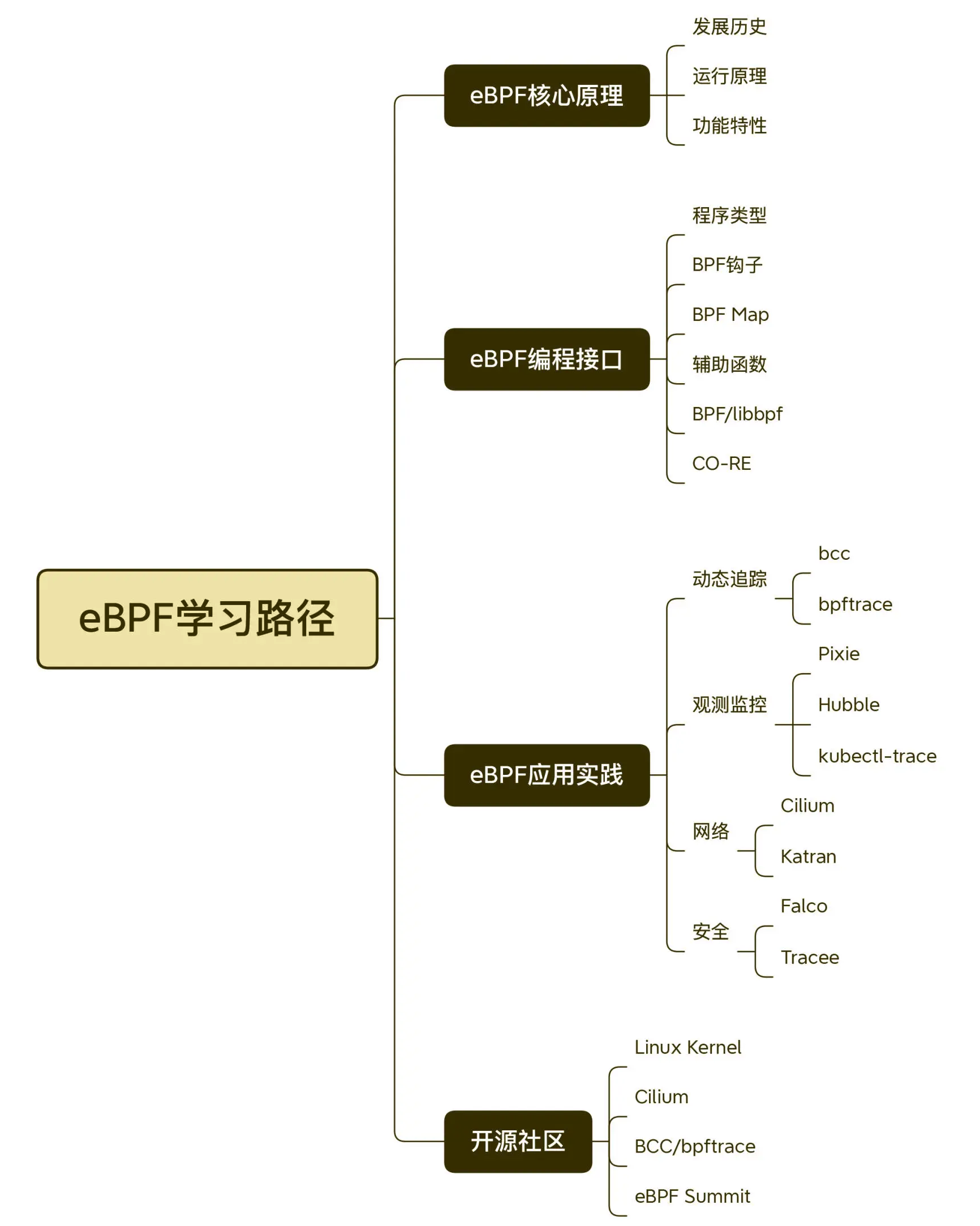
0.1 知识图
- eBPF系统知识
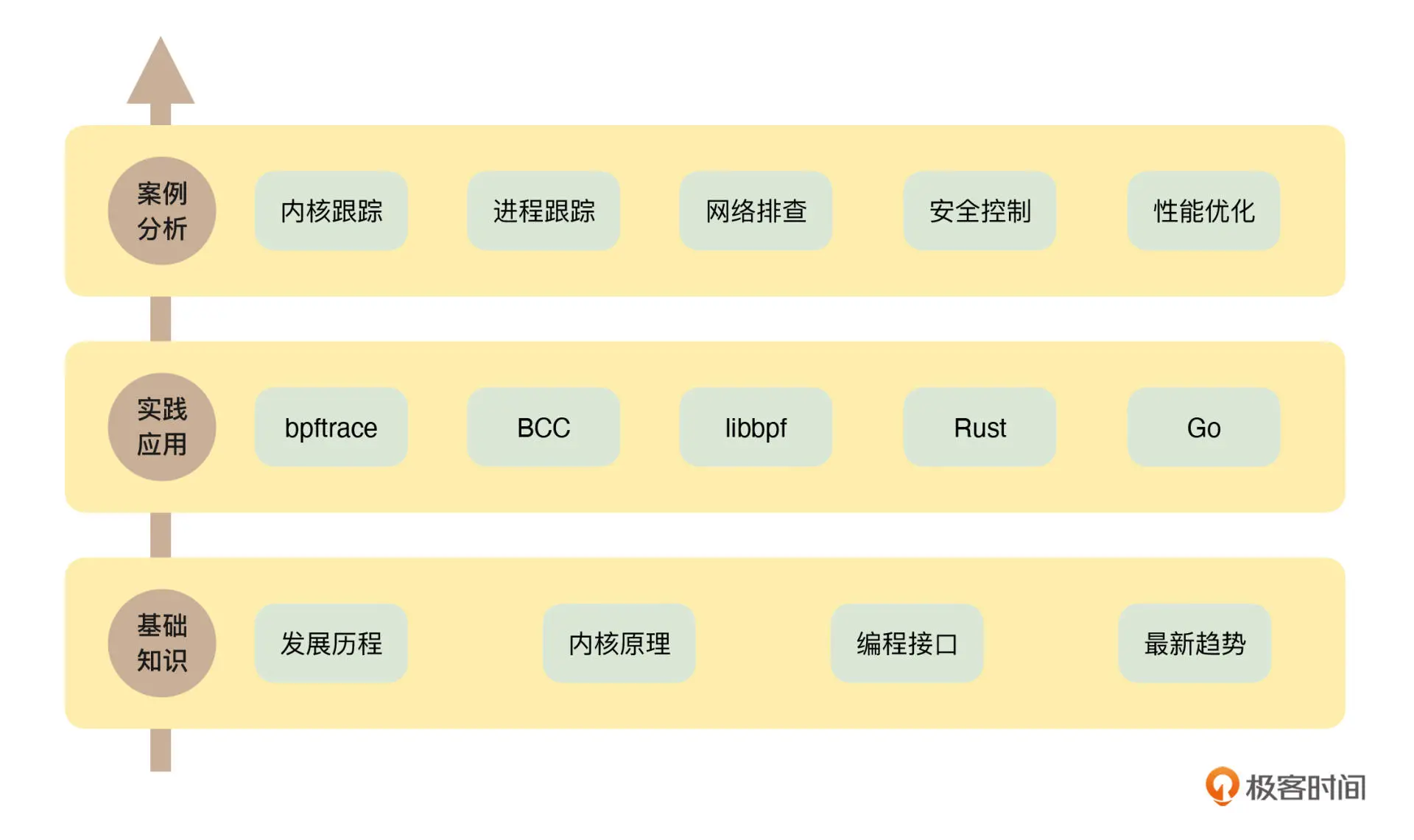
- eBPF学习路径
0.2 代码地址
https://github.com/feiskyer/ebpf-apps
1 eBPF工作原理
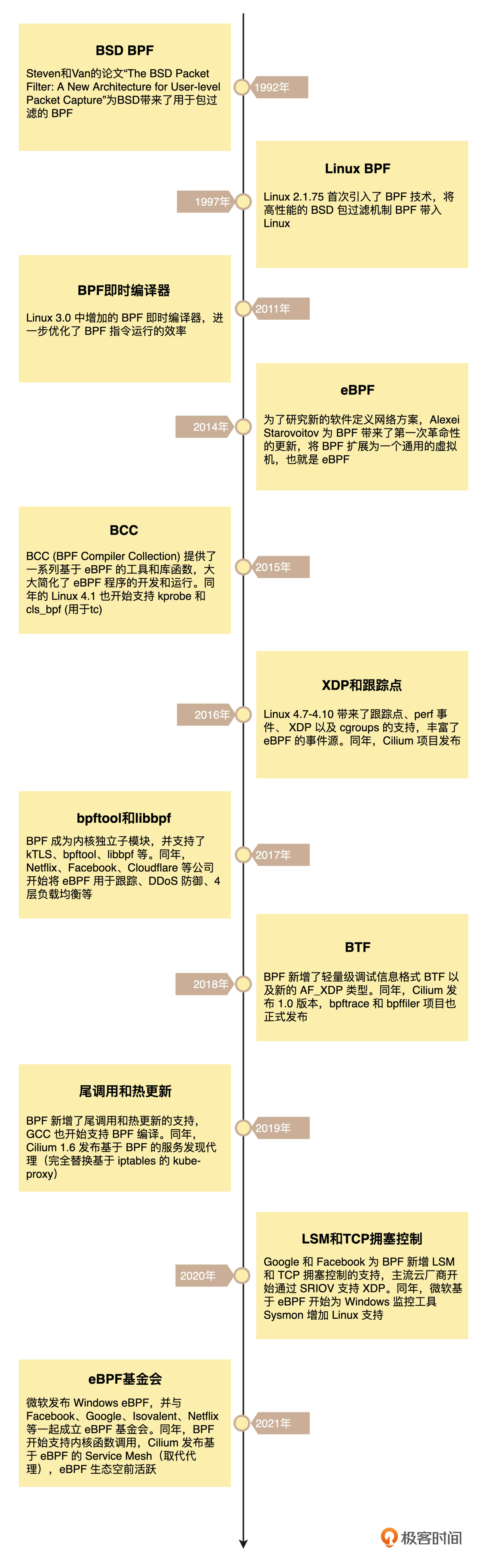
1.1 eBPF 的发展历程
eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统。
在内核发展的同时,eBPF 繁荣的生态也进一步促进了 eBPF 的蓬勃发展。这其中,最典型的就是 iovisor 带来的 BCC、bpftrace 等工具,成为 eBPF 在跟踪和排错领域的最佳实践。由于 eBPF 无需修改内核源码和重新编译内核就可以扩展内核的功能,Cilium、Katran、Falco 等一系列基于 eBPF 优化网络和安全的开源项目也逐步诞生。并且,越来越多的开源和商业解决方案开始借助 eBPF,优化其网络、安全以及观测的性能。比如,最流行的网络解决方案之一 Calico,就在最近的版本中引入了 eBPF 数据面网络,大大提升了网络的性能。
- eBPF发展历程
1.2 eBPF 是怎么工作的?
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
通常我们借助 LLVM 把编写的 eBPF 程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行。
如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行。比如,下面就是一些典型的验证过程:
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
BPF 程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过 BPF 映射同运行在内核中的 BPF 程序进行交互。在性能观测中,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。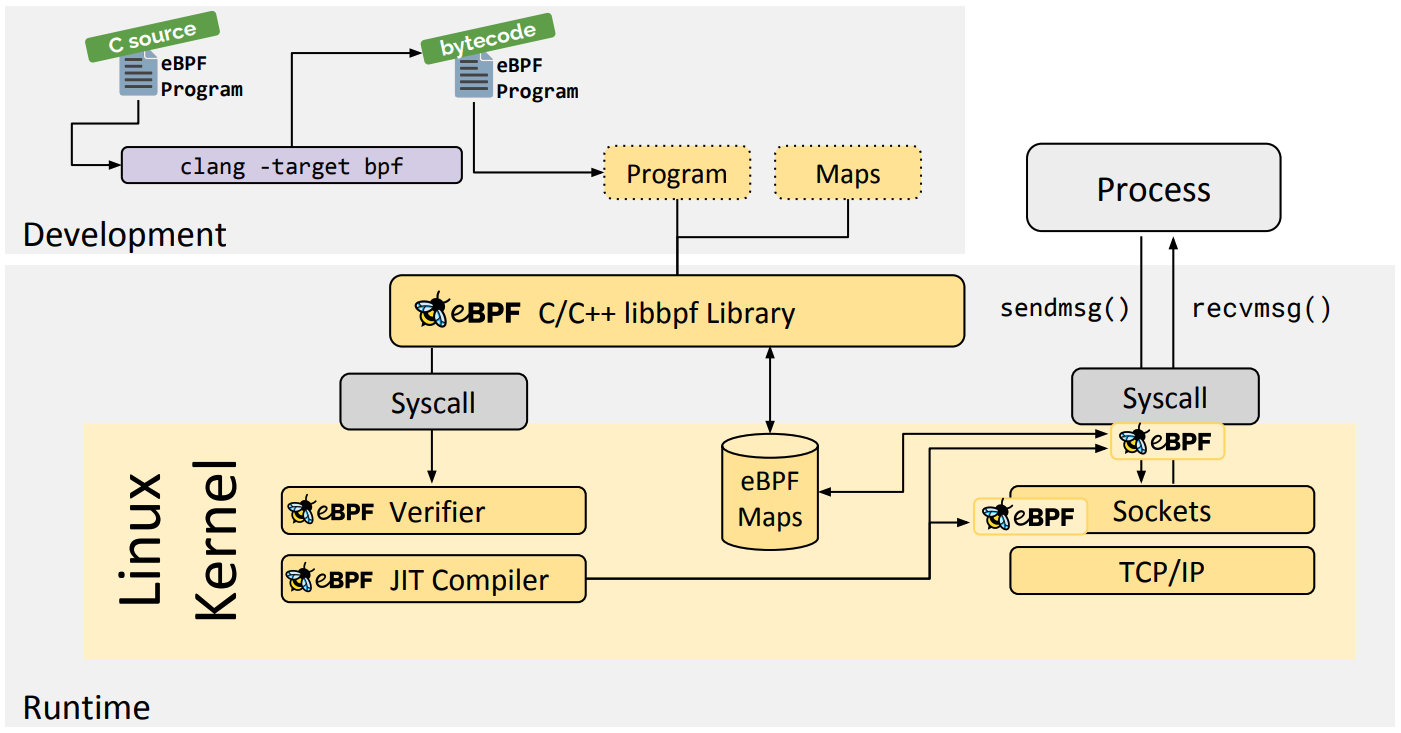
可以看到,eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
最常见的 eBPF 限制:
- eBPF 程序必须被验证器校验通过后才能执行,且不能包含无法到达的指令;
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数;
- eBPF 程序栈空间最多只有 512 字节,想要更大的存储,就必须要借助映射存储;
- 在内核 5.2 之前,eBPF 字节码最多只支持 4096 条指令,而 5.2 内核把这个限制提高到了 100 万条;
- 由于内核的快速变化,在不同版本内核中运行时,需要访问内核数据结构的 eBPF 程序很可能需要调整源码,并重新编译。
BCC 包含的所有工具都是基于eBPF开发的: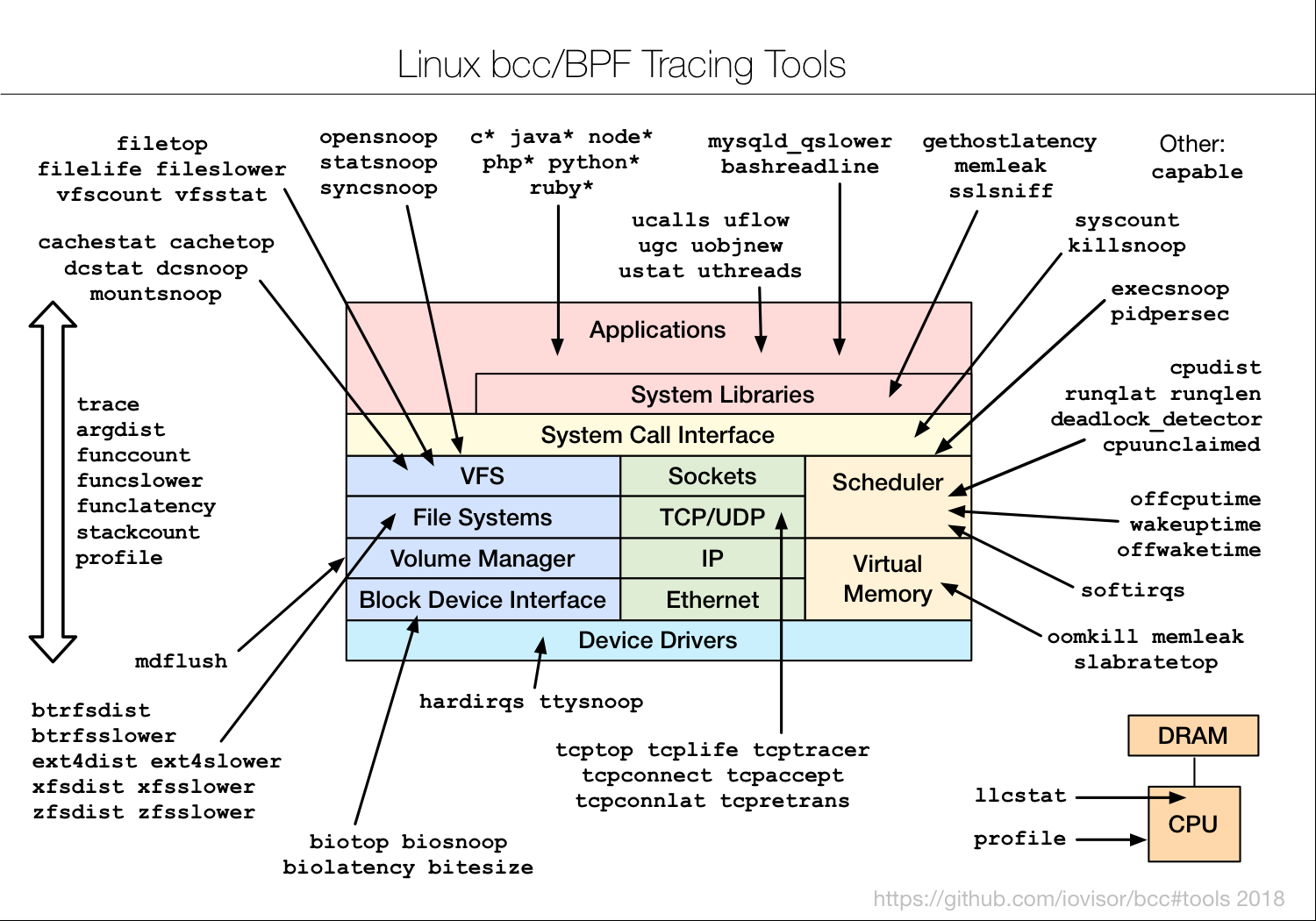
2 基础入门篇
2.1 开发运行第一个eBPF程序
2.1.1 搭建 eBPF 开发环境?
安装 eBPF 开发和运行所需要的开发工具,这包括:
- 将 eBPF 程序编译成字节码的 LLVM;
- C 语言程序编译工具 make;
- 最流行的 eBPF 工具集 BCC 和它依赖的内核头文件;
- 与内核代码仓库实时同步的 libbpf;
- 同样是内核代码提供的 eBPF 程序管理工具 bpftool。
1 | # For Ubuntu20.10+ |
2.1.2 开发第一个eBPF程序
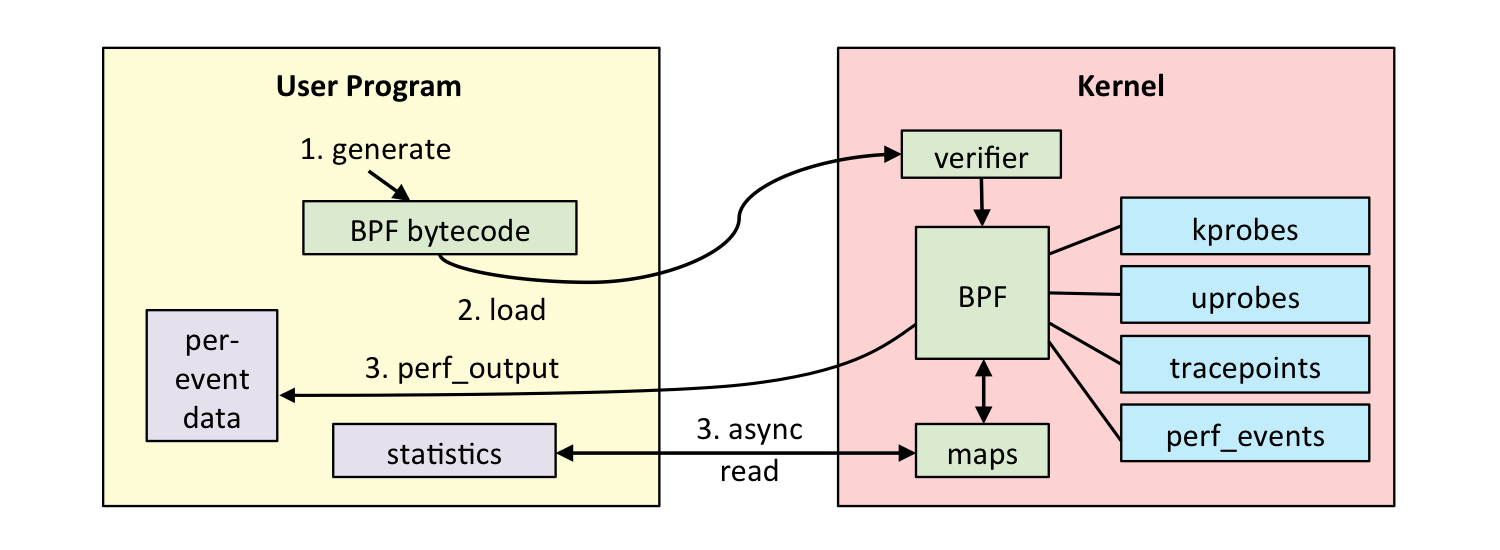
这个过程分为以下 5 步:
- 第一步,使用 C 语言开发一个 eBPF 程序;
- 第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
- 第三步,通过 bpf 系统调用,把 BPF 字节码提交给内核;
- 第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
- 第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态。
2.2 eBPF运行原理
2.2.1 eBPF 虚拟机如何工作的
eBPF 是一个运行在内核中的虚拟机,主要由5个模块组成: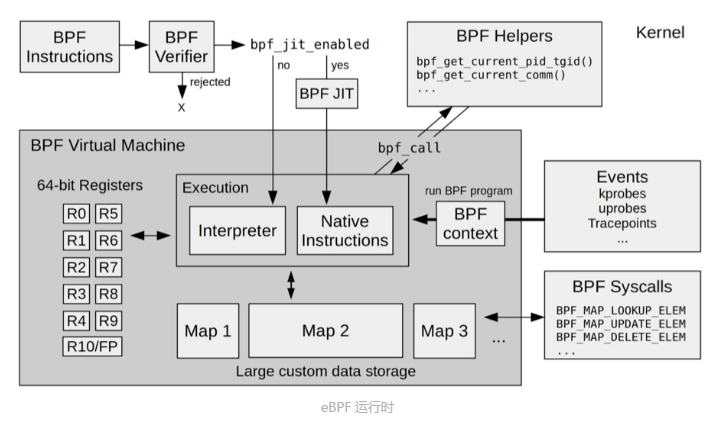
- 第一个模块是 eBPF 辅助函数。它提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
- 第二个模块是 eBPF 验证器。它用于确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令;接着再模拟指令的执行过程,确保不会执行无效指令。
- 第三个模块是由 11 个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块。这个模块用于控制 eBPF 程序的执行。其中,R0 寄存器用于存储函数调用和 eBPF 程序的返回值,这意味着函数调用最多只能有一个返回值;R1-R5 寄存器用于函数调用的参数,因此函数调用的参数最多不能超过 5 个;而 R10 则是一个只读寄存器,用于从栈中读取数据。
- 第四个模块是即时编译器,它将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行。
- 第五个模块是 **BPF映射(map)**,它用于提供大块的存储。这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
2.2.2 BPF 指令
使用 bpftool 查看 eBPF 程序的运行状态。如下所示: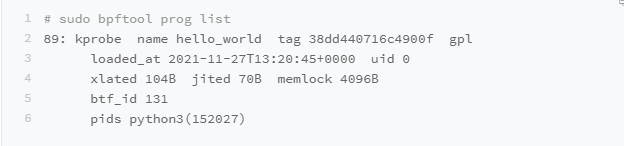
输出中,89 是这个eBPF程序的编号,kprobe 是程序的类型,而hello world 是程序的名字。
有了 eBPF 程序编号之后,执行下面的命令就可以导出这个 eBPF 程序的指令(注意把 89 替换成你查询到的编号):
1 | sudo bpftool prog dump xlated id 89 |
会看到如下输出:
这里边包括了众多BPF指令,一般并不会直接使用 BPF 指令开发程序,可以使用 C 语言开发 eBPF程序,而只把 BPF 指令作为排查 eBPF 程序疑难杂症时的参考。
2.2.3 eBPF 程序什么时候执行
在之前的示例代码中,BCC 负责了 eBPF 程序的编译和加载过程,可以通过跟踪 程序执行的系统调用查看执行过程:
1 | # -ebpf 表示只跟踪bpf系统调用 |
输出如下: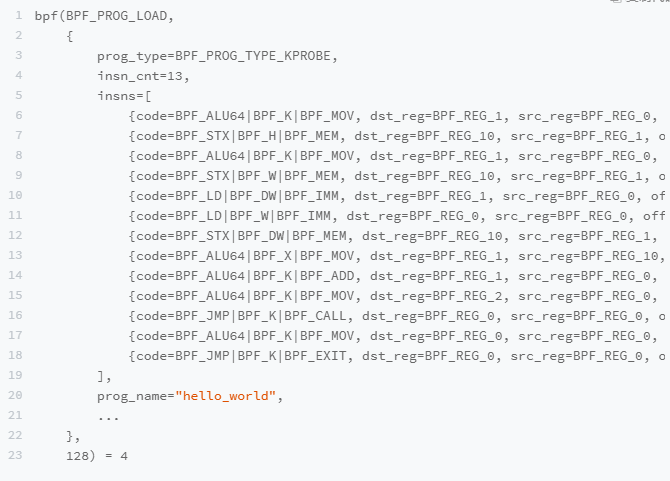
实际上 bpf 系统调用 可以通过 man bpf 命令查看,只需要三个参数:
1 | int bpf(int cmd, union bpf_attr *attr, unsigned int size); |
对应前面的 strace 输出结果,这三个参数的具体含义如下。
- 第一个参数是 BPF_PROG_LOAD,表示加载 BPF程序。
- 第二个参数是 bpf_attr 类型的结构体,表示 BPF 程序的属性。其中,有几个需要留意的参数,比如:
- prog_type 表示 BPF程序的类型,这儿是BPF_PROG_TYPE_KPROBE,跟Python代码中的 attach_kprobe -致
- insn_cnt (instructions count) 表示指令条数;
- insns(instructions) 包含了具体的每一条指令,这儿的 13 条指令跟我们前面 bpftool prog dump 的结果是一致的
- prog_name 则表示 BPF程序的名字,即 hello_world
- 第三个参数 128 表示属性的大小
BPF程序加载到内核后,并不会立刻执行,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件等。
之前的 示例 HelloWorld 程序,由于调用了 attach_kprobe 函数,所以这是一个内核跟踪事件:
1 | b.attach_kprobe(event="do_sys_openat2", fn_name="hello_world") |
所以,除了把 eBPF 程序加载到内核之外,还需要把加载后的程序跟具体的内核函数调用事件进行绑定。在 eBPF的实现中,诸如内核跟踪(kprobe)、用户跟踪(uprobe)等的事件绑定,都是通过 perf_event_open()来完成的。
同样,可以通过 strace 命令跟踪查看,这次不加 -ebpf 参数:
1 | sudo strace -v -f ./hello.py |
输出如下:
从输出中,你可以看出 BPF 与性能事件的绑定过程分为以下几步:
- 首先,借助 bpf 系统调用,加载 BPF程序,并记住返回的文件描述符
- 然后,查询 kprobe 类型的事件编号。BCC 实际上是通过
/sys/bus/event_source/devices/kprobe/type来查询的 - 接着,调用
perf_event_open创建性能监控事件。比如,事件类型(type 是上一步查询到的 6)、事件的参数(config1 包含了内核函数 do_sys_openat2)等; - 最后,再通过 ioctl 的
PERF_EVENT_IOC_SET_BPF命令,将 BPF 程序绑定到性能监控事件。
用高级语言开发的 eBPF 程序,需要首先编译为 BPF字节码(即 BPF指令),然后借助 bpf 系统调用加载到内核中,最后再通过性能监控等接口,与具体的内核事件进行绑定。这样,内核的性能监控模块才会在内核事件发生时,自动执行我们开发的eBPF程序。
2.3 eBPF 程序怎么与内核进行交互
2.3.1 BPF 系统调用
一个完整的 eBPF 程序通常包含用户态和内核态两部分。其中,用户态负责 eBPF程序的加载、事件绑定以及 eBPF 程序运行结果的汇总输出;内核态运行在 eBPF 虚拟机中,负责定制和控制系统的运行状态。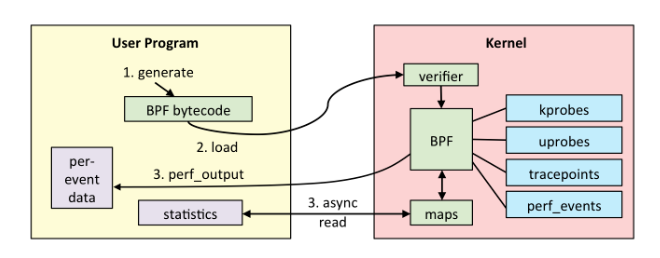
用户态程序与内核进行交互时必须通过系统调用来完成,在 eBPF 程序中,常用到的就是 BPF 系统调用:
1 | int bpf(int cmd, union bpf_attr *attr, unsigned int size); |
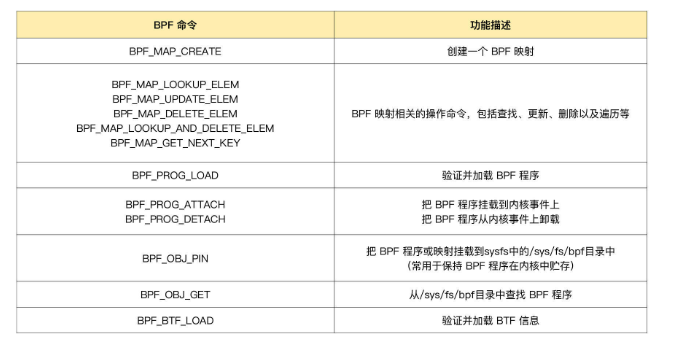
BPF 的一些指令在内核头文件include/uapi/linux/bpf.h 定义:
1 | enum bpf_cmd { |
2.3.2 BPF 辅助函数
eBPF 程序并不能随意调用内核函数,因此,内核定义了一系列的辅助函数,用于 eBPF 程序与内核其他模块进行交互。比如,上一讲的 Hello World 示例中使用的 bpf_trace_printk()就是最常用的一个辅助函数,用于向调试文件系统(/sys/kernel/debug/tracing/trace_pipe)写入调试信息。
需要注意的是,并不是所有的辅助函数都可以在 eBPF 程序中随意使用,不同类型的 eBPF 程序所支持的辅助函数是不同的。比如,对于 Helo World 示例这类内核探针(kprobe)类型的 eBPF 程序,你可以在命令行中执行 bpftool feature probe ,来查询当前系统支持的辅助函数列表:
对于这些辅助函数的详细定义,可以在命令行中执行 man bpf-helpers,或者参考内核头文件 include/uapi/linux/bpf.h,来查看它们的详细定义和使用说明。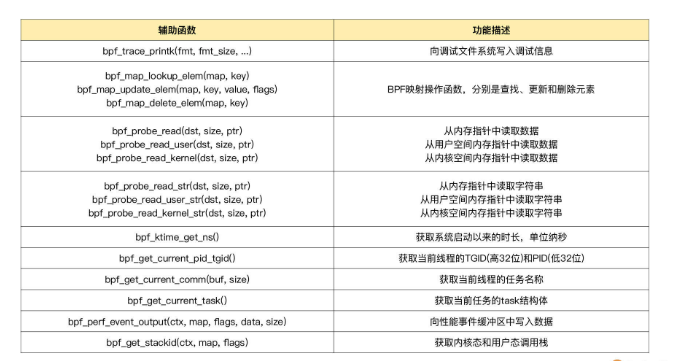
这其中,需要特别注意的是以 bpf_probe_read 开头的一系列函数。我在上一讲中已经提到,eBPF 内部的内存空间只有寄存器和栈。所以,要访问其他的内核空间或用户空间地址,就需要借助 bpf_probe_read 这一系列的辅助函数。这些函数会进行安全性检查,并禁止缺页中断的发生。
而在 eBPF 程序需要大块存储时,就不能像常规的内核代码那样去直接分配内存了,而是必须通过 BPF 映射(BPF Map)来完成。
2.3.3 BPF 映射
BPF 映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取 eBPF 程序的运行状态。eBPF 程序最多可以访问 64 个不同的 BPF 映射,并且不同的 eBPF 程序也可以通过相同的 BPF 映射来共享它们的状态。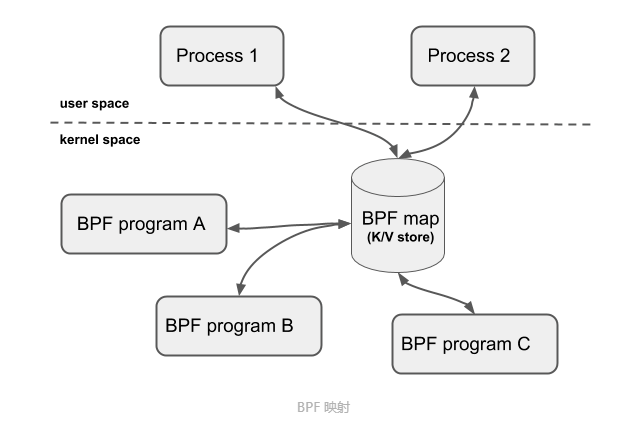
BPF 辅助函数中并没有 BPF 映射的创建函数,BPF 映射只能通过用户态程序的系统调用来创建。比如,可以通过下面的示例代码来创建一个 BPF 映射,并返回映射的文件描述符:
这其中,最关键的是设置映射的类型。内核头文件 include/uapi/linux/bpf.h 中的bpf_map_type 定义了所有支持的映射类型,可以使用如下的 bpftool 命令,来查询当前系统支持哪些映射类型。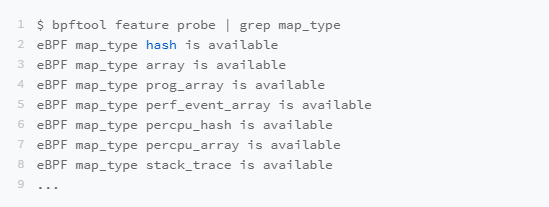
下边时几种最常用的映射类型及其功能和使用场景: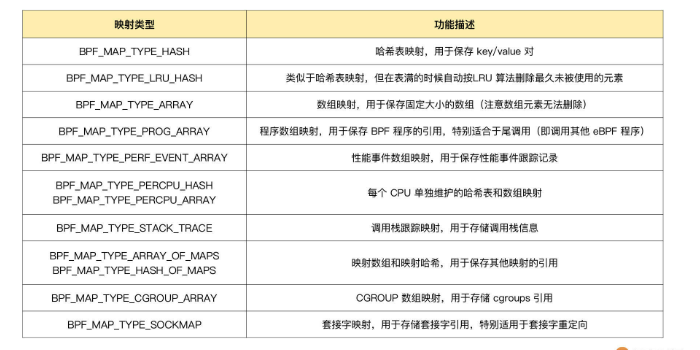
如果你的 eBPF 程序使用了 BCC库,还可以使用预定义的宏来简化 BPF 映射的创建过程。比如,对哈希表映射来说,BCC定义了BPFHASH(name,key_type=u64,leaf_type=u64,size=10240),因此,就可以通过下面的几种方法来创建一个哈希表映射:
BPF 系统调用中并没有删除映射的命令,这是因为 BPF 映射会在用户态程序关闭文件描述符的时候自动删除(即close(fd))。如果你想在程序退出后还保留映射,就需要调用 BPF_0BJ_PIN 命令,将映射挂载到 /sys/fs/bpf 中
在调试 BPF 映射相关的问题时,你还可以通过 bpftool 来查看或操作映射的具体内容。比如,可以通过下面这些命令创建、更新、输出以及删除映射: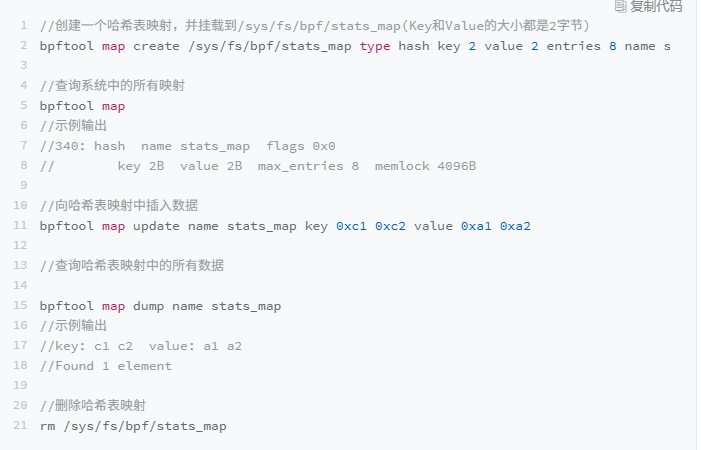
2.3.4 BPF 类型格式(BTF)
在安装 BCC 工具的时候,内核头文件 linux-headers-$(uname -r)也是必须要安装的一个依赖项。这是因为 BCC在编译 eBPF 程序时,需要从内核头文件中找到相应的内核数据结构定义。这样,在调用 bpf_probe_read 时,才能从内存地址中提取到正确的数据类型。
但是,编译时依赖内核头文件也会带来很多问题。主要有这三个方面:
- 首先,在开发 eBPF 程序时,为了获得内核数据结构的定义,就需要引入一大堆的内核头文件;
- 其次,内核头文件的路径和数据结构定义在不同内核版本中很可能不同。因此,你在升级内核版本时,就会遇到找不到头文件和数据结构定义错误的问题;
- 最后,在很多生产环境的机器中,出于安全考虑,并不允许安装内核头文件,这时就无法得到内核数据结构的定义。在程序中重定义数据结构虽然可以暂时解决这个问题,但也很容易把使用着错误数据结构的 eBPF 程序带入新版本内核中运行。
以上的问题,在BPF类型格式的诞生被解决。从内核5.2开始,只要开启了CONFIG_DEBUG_INFO_BTF,在编译内核时,内核数据结构的定义就会自动内嵌在内核二进制文件 vmlinux 中。并且,你还可以借助下面的命令,把这些数据结构的定义导出到一个头文件中(通常命名为vmlinux.h):
1 | bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h |
在开发eBPF 程序时只需要引入一个 vmlinux.h 即可,不用再引入一大堆的内核头文件了。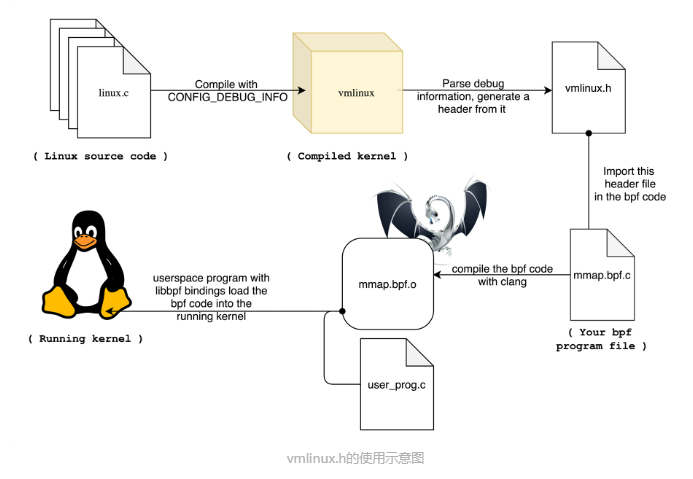
同时,借助 BTF、bpftool 等工具,我们也可以更好地了解 BPF 程序的内部信息,这也会让调试变得更加方便。比如,在查看 BPF映射的内容时,你可以直接看到结构化的数据,而不只是十六进制数值:
1 | # bpftool map dump id 386 |
解决了内核数据结构的定义问题,接下来的问题就是,如何让 eBPF 程序在内核升级之后,不需要重新编译就可以直接运行。eBPF的一次编译到处执行(Compile Once RunEverywhere,简称 CO-RE)项目借助了 BTF 提供的调试信息,再通过下面的两个步骤,使得eBPF 程序可以适配不同版本的内核:
- 第一,通过对 BPF 代码中的访问偏移量进行重写,解决了不同内核版本中数据结构偏移量不同的问题;
- 第二,在 libbpf 中预定义不同内核版本中的数据结构的修改,解决了不同内核中数据结构不兼容的问题。
BTF 和一次编译到处执行带来了很多的好处,但也需要注意这一点:它们都要求比较新的内核版本(>=5.2),并且需要非常新的发行版(如 Ubuntu 20.10+、RHEL8.2+ 等)才会默认打开内核配置 CONFIG_DEBUG_INFO_BTF。对于旧版本的内核,虽然它们不会再去内置BTF 的支持,但开源社区正在尝试通过 BTFHub 项目等方法,为它们提供 BTF 调试信息。
2.4 eBPF 程序的触发机制
2.4.1 eBPF 程序的分类
根据内核头文件 include/uapi/linux/bpf.h 中 bpf_prog_type 的定义,Linux 内核 v5.13 已经支持 30 种不同类型的 eBPF 程序(注意, BPF_PROG_TYPE_UNSPEC表示未定义):
1 | enum bpf_prog_type { |
通过已下的命令,查询当前系统支持的程序类型:
1 | bpftool feature probe | grep program_type |
执行后,输出如下:
1 | eBPF program_type socket_filter is available |
看到当前内核支持 kprobe、xdp、perf_event 等程序类型,而不支持 ext、lsm 等程序类型。
根据具体功能和应用场景的不同,这些程序类型大致可以划分为三类:
- 第一类是跟踪,即从内核和程序的运行状态中提取跟踪信息,来了解当前系统正在发生什么。
- 第二类是网络,即对网络数据包进行过滤和处理,以便了解和控制网络数据包的收发过程。
- 第三类是除跟踪和网络之外的其他类型,包括安全控制、BPF 扩展等等。
2.4.2 跟踪类 eBPF 程序
跟踪类 eBPF 程序主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。
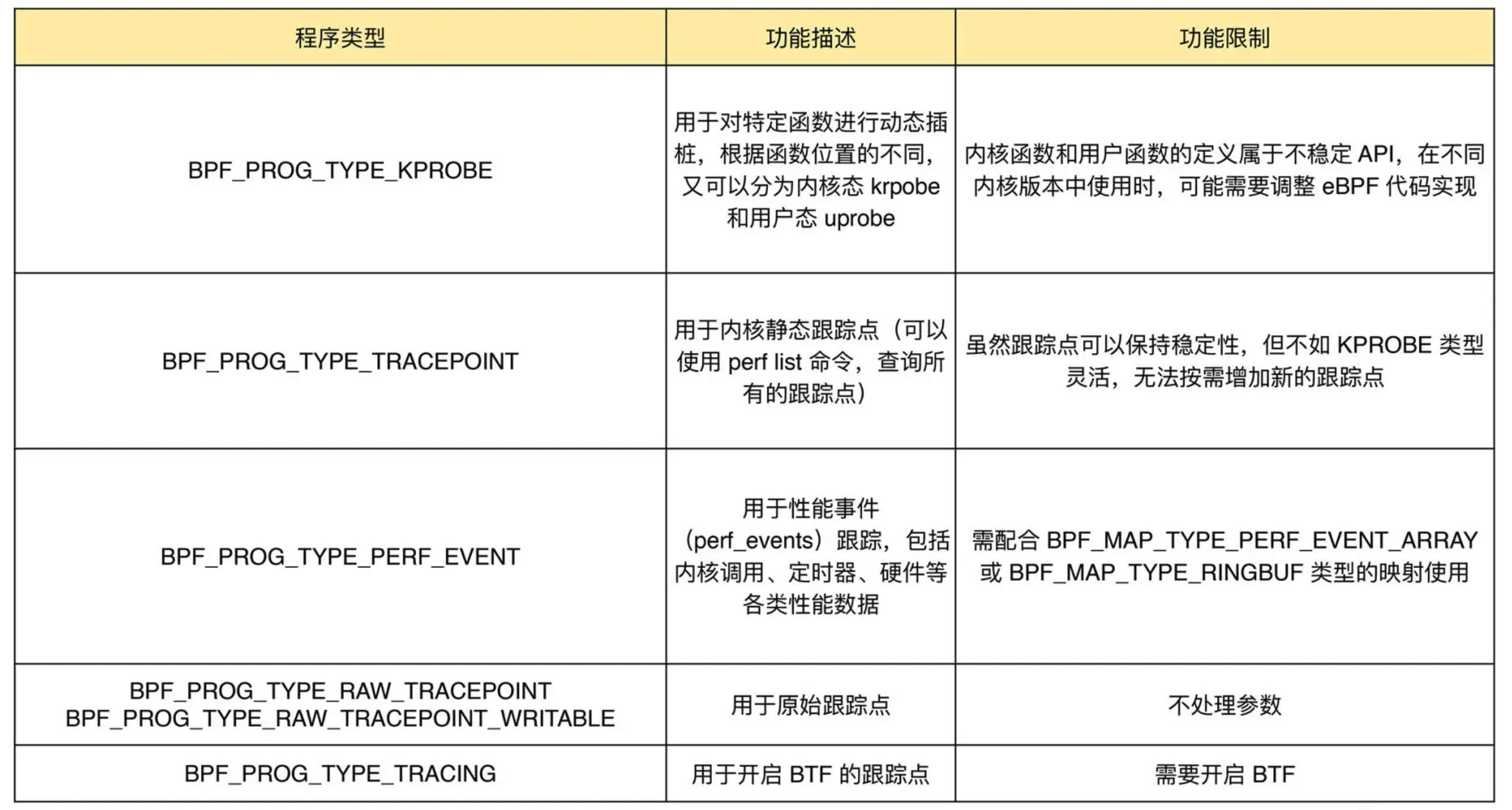
KPROBE、TRACEPOINT 以及 PERF_EVENT 都是最常用的 eBPF 程序类型,大量应用于监控跟踪、性能优化以及调试排错等场景中。
2.4.3 网络类 eBPF 程序
网络类 eBPF 程序主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。根据事件触发位置的不同,网络类 eBPF 程序又可以分为 XDP(eXpress Data Path,高速数据路径)程序、TC(Traffic Control,流量控制)程序、套接字程序以及 cgroup 程序。
2.4.3.1 XDP 程序
XDP 程序的类型定义为 BPF_PROG_TYPE_XDP,它在网络驱动程序刚刚收到数据包时触发执行。由于无需通过繁杂的内核网络协议栈,XDP 程序可用来实现高性能的网络处理方案,常用于 DDoS 防御、防火墙、4 层负载均衡等场景。
XDP 程序并不是绕过了内核协议栈,它只是在内核协议栈之前处理数据包,而处理过的数据包还可以正常通过内核协议栈继续处理。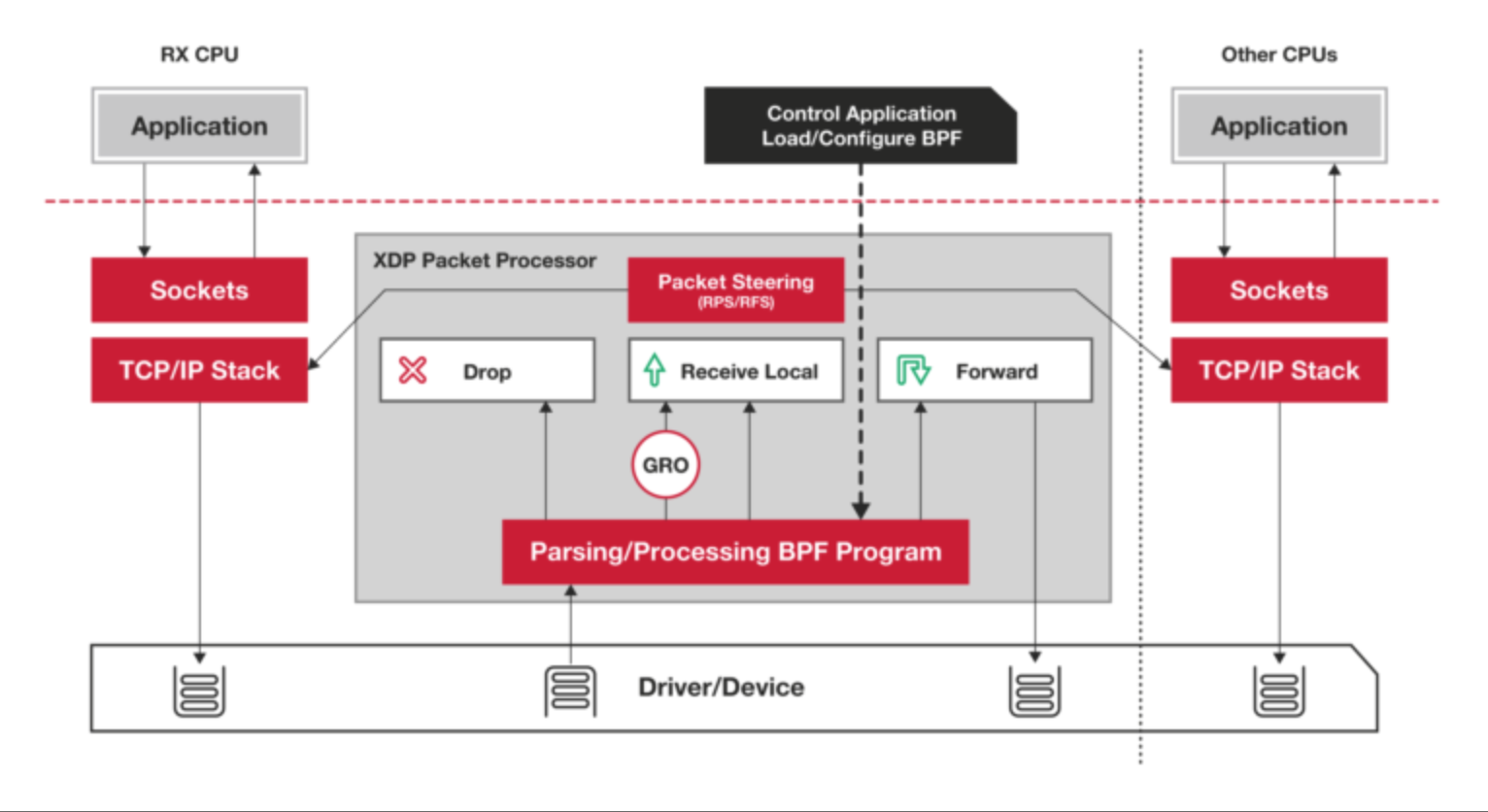
根据网卡和网卡驱动是否原生支持 XDP 程序,XDP 运行模式可以分为下面这三种:
- 通用模式。它不需要网卡和网卡驱动的支持,XDP 程序像常规的网络协议栈一样运行在内核中,性能相对较差,一般用于测试;
- 原生模式。它需要网卡驱动程序的支持,XDP 程序在网卡驱动程序的早期路径运行;
- 卸载模式。它需要网卡固件支持 XDP 卸载,XDP 程序直接运行在网卡上,而不再需要消耗主机的 CPU 资源,具有最好的性能。
无论哪种模式,XDP 程序在处理过网络包之后,都需要根据 eBPF 程序执行结果,决定数据包的去处。这些执行结果对应以下 5 种 XDP 程序结果码: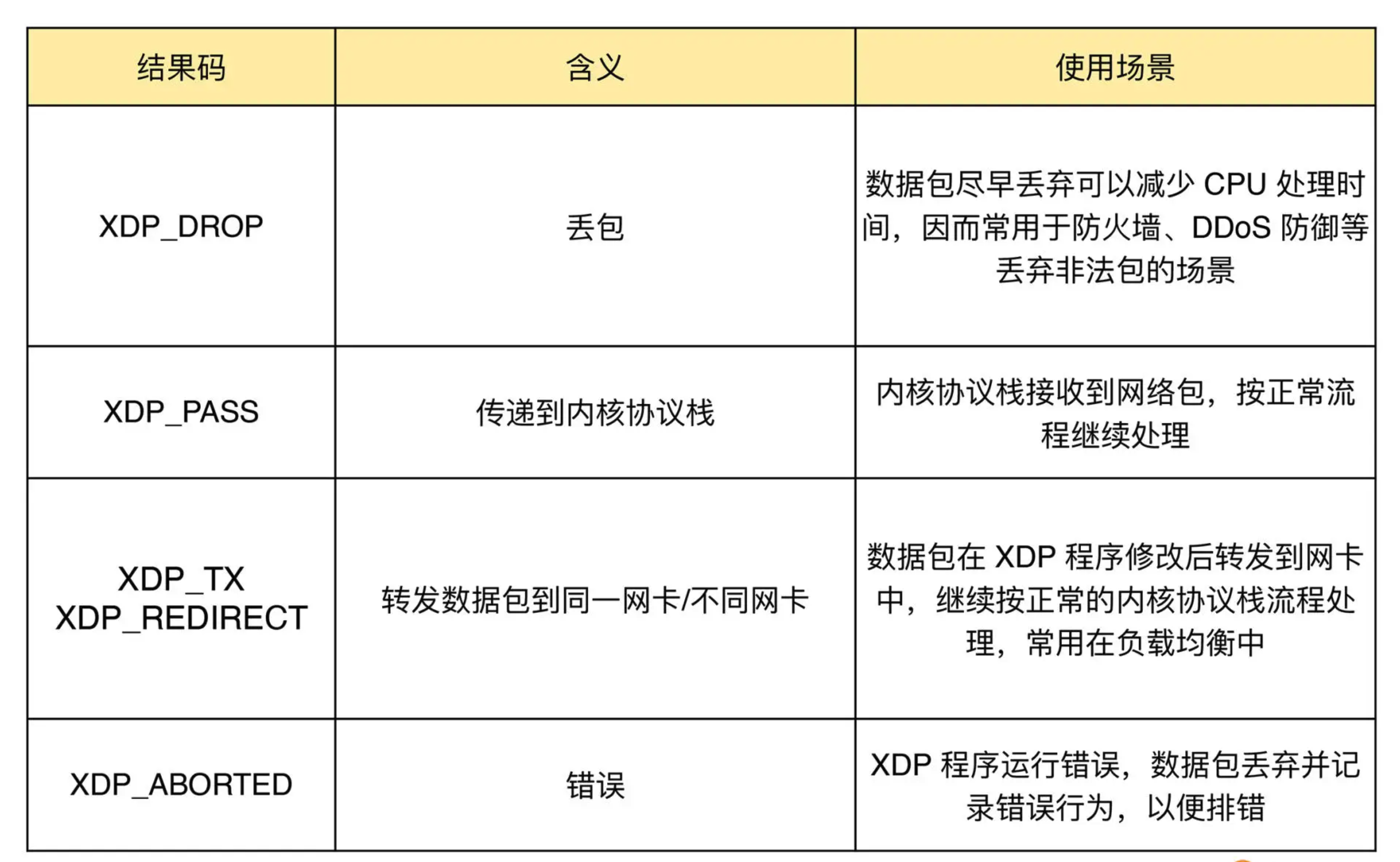
XDP 程序通过 ip link 命令加载到具体的网卡上,加载格式为:
1 | # eth1 为网卡名 |
而卸载 XDP 程序也是通过 ip link 命令,具体参数如下:
1 | sudo ip link set veth1 xdpgeneric off |
除了 ip link之外, BCC 也提供了方便的库函数,让我们可以在同一个程序中管理 XDP 程序的生命周期:
1 | from bcc import BPF |
2.4.3.2 TC 程序
TC 程序的类型定义为 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT,分别作为 Linux 流量控制 的分类器和执行器。Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器等,实现了对网络流量的整形调度和带宽控制。
下图展示了 HTB(Hierarchical Token Bucket,层级令牌桶)流量控制的工作原理: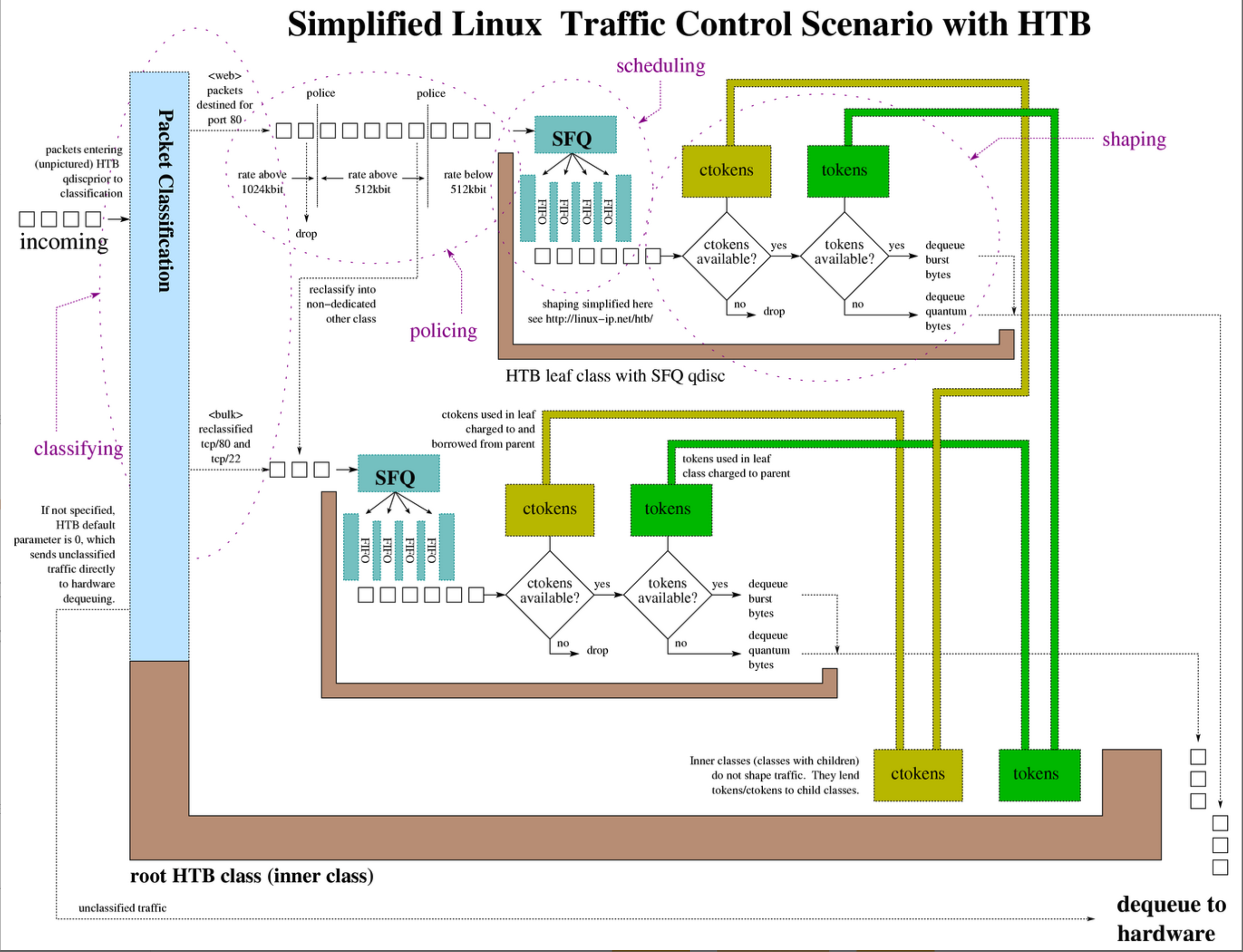
TC 程序可以直接在一个程序内完成分类和执行的动作,而无需再调用其他的 TC 排队规则和分类器,具体如下图所示: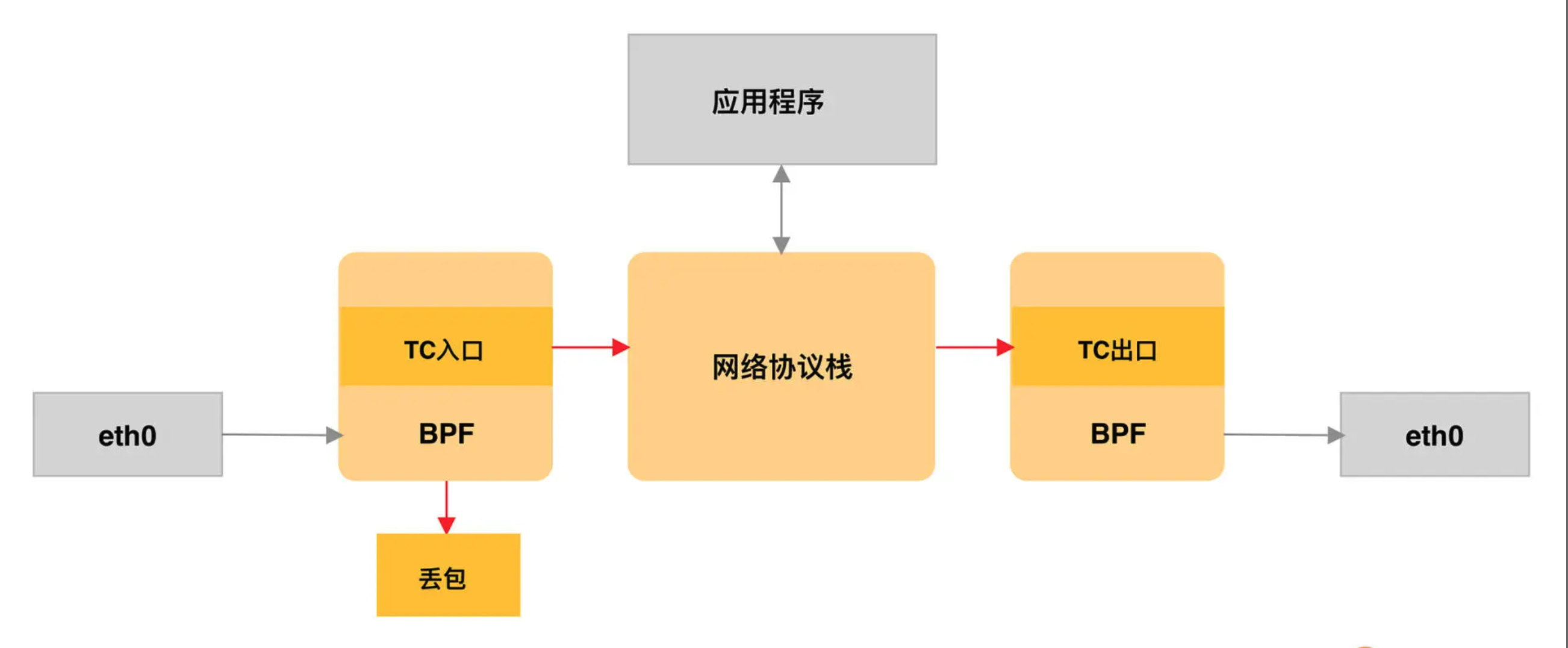
同 XDP 程序相比,TC 程序可以直接获取内核解析后的网络报文数据结构sk_buff(XDP 则是 xdp_buff),并且可在网卡的接收和发送两个方向上执行(XDP 则只能用于接收)。下面我们来具体看看 TC 程序的执行位置:
- 对于接收的网络包,TC 程序在网卡接收(GRO)之后、协议栈处理(包括 IP 层处理和 iptables 等)之前执行;
- 对于发送的网络包,TC 程序在协议栈处理(包括 IP 层处理和 iptables 等)之后、数据包发送到网卡队列(GSO)之前执行。
由于 TC 运行在内核协议栈中,不需要网卡驱动程序做任何改动,因而可以挂载到任意类型的网卡设备(包括容器等使用的虚拟网卡)上。
同 XDP 程序一样,TC eBPF 程序也可以通过 Linux 命令行工具来加载到网卡上,不过相应的工具要换成 tc。你可以通过下面的命令,分别加载接收和发送方向的 eBPF 程序:
1 | # 创建 clsact 类型的排队规则 |
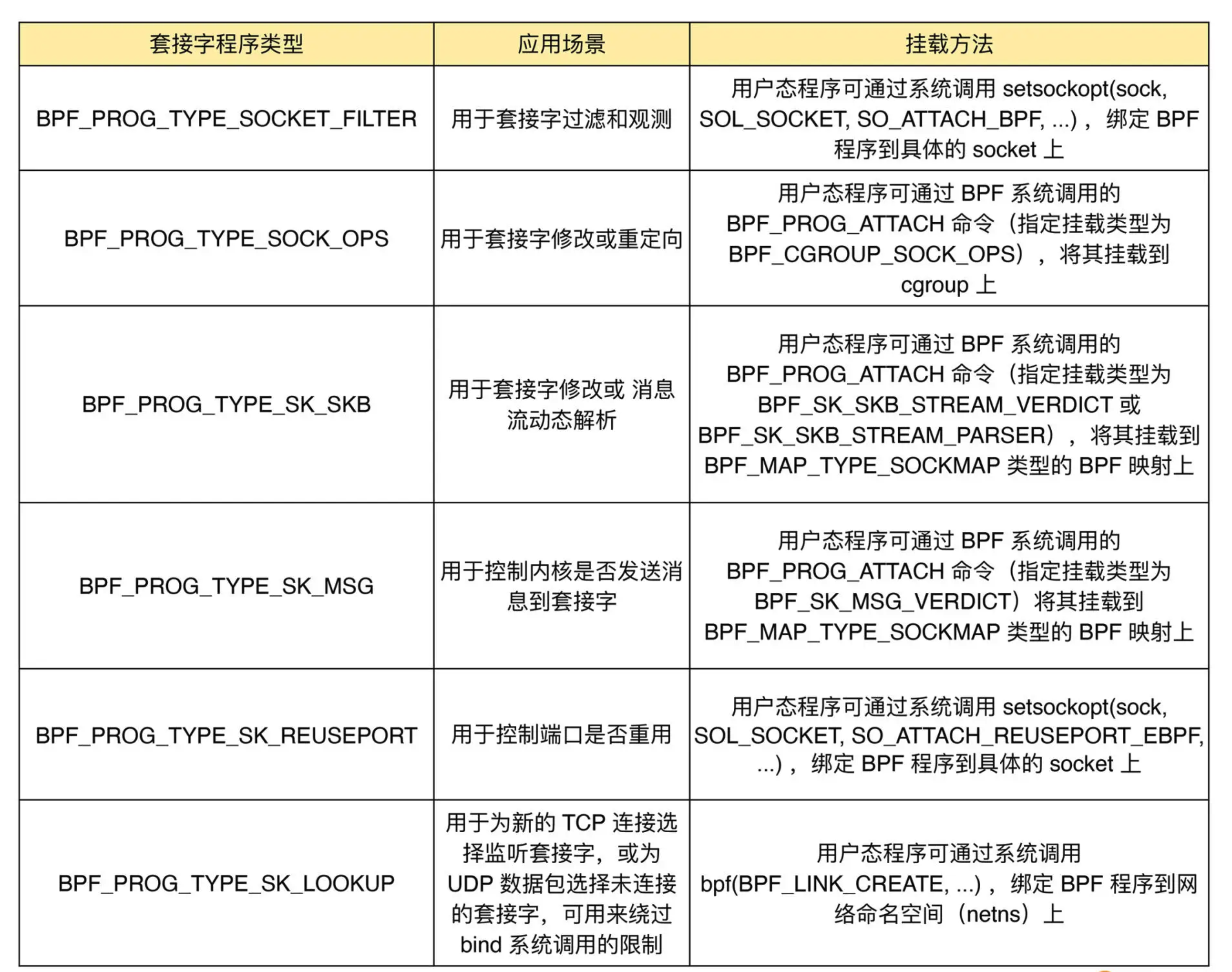
2.4.3.3 套接字程序
套接字程序用于过滤、观测或重定向套接字网络包,具体的种类也比较丰富。根据类型的不同,套接字 eBPF 程序可以挂载到套接字(socket)、控制组(cgroup )以及网络命名空间(netns)等各个位置。
2.4.3.4 cgroup 程序
cgroup 程序用于对 cgroup 内所有进程的网络过滤、套接字选项以及转发等进行动态控制,它最典型的应用场景是对容器中运行的多个进程进行网络控制。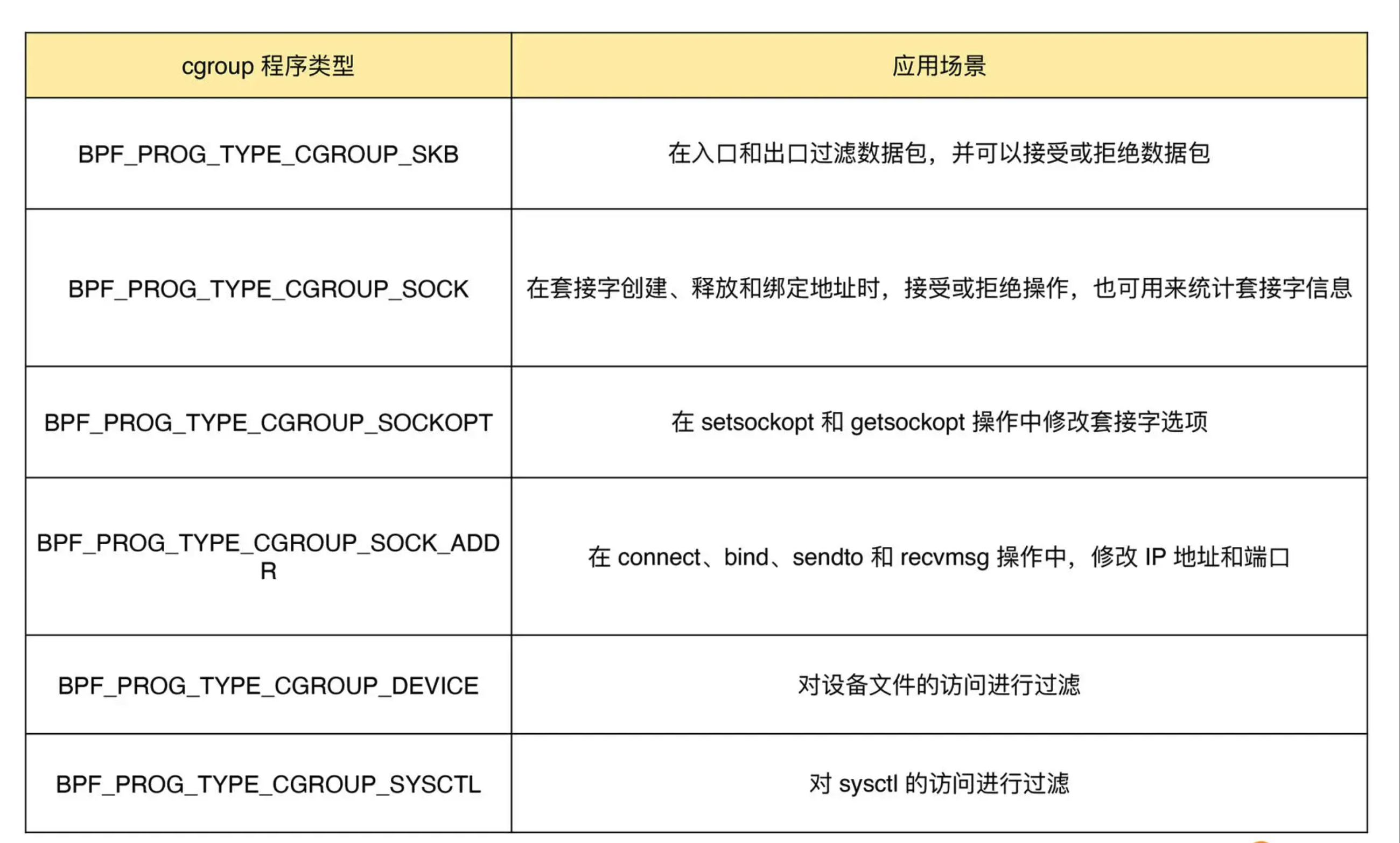
这些类型的 BPF 程序都可以通过 BPF 系统调用的 BPF_PROG_ATTACH 命令来进行挂载,并设置挂载类型为匹配的 BPF_CGROUP_xxx 类型。比如,在挂载 BPF_PROG_TYPE_CGROUP_DEVICE 类型的 BPF 程序时,需要设置 bpf_attach_type 为 BPF_CGROUP_DEVICE:
1 | union bpf_attr attr = {}; |
这几类网络 eBPF 程序是在不同的事件触发时执行的,因此,在实际应用中通常可以把多个类型的 eBPF 程序结合起来,一起使用,来实现复杂的网络控制功能。比如,最流行的 Kubernetes 网络方案 Cilium 就大量使用了 XDP、TC 和套接字 eBPF 程序,如下图(图片来自 Cilium 官方文档,图中黄色部分即为 Cilium eBPF 程序)所示: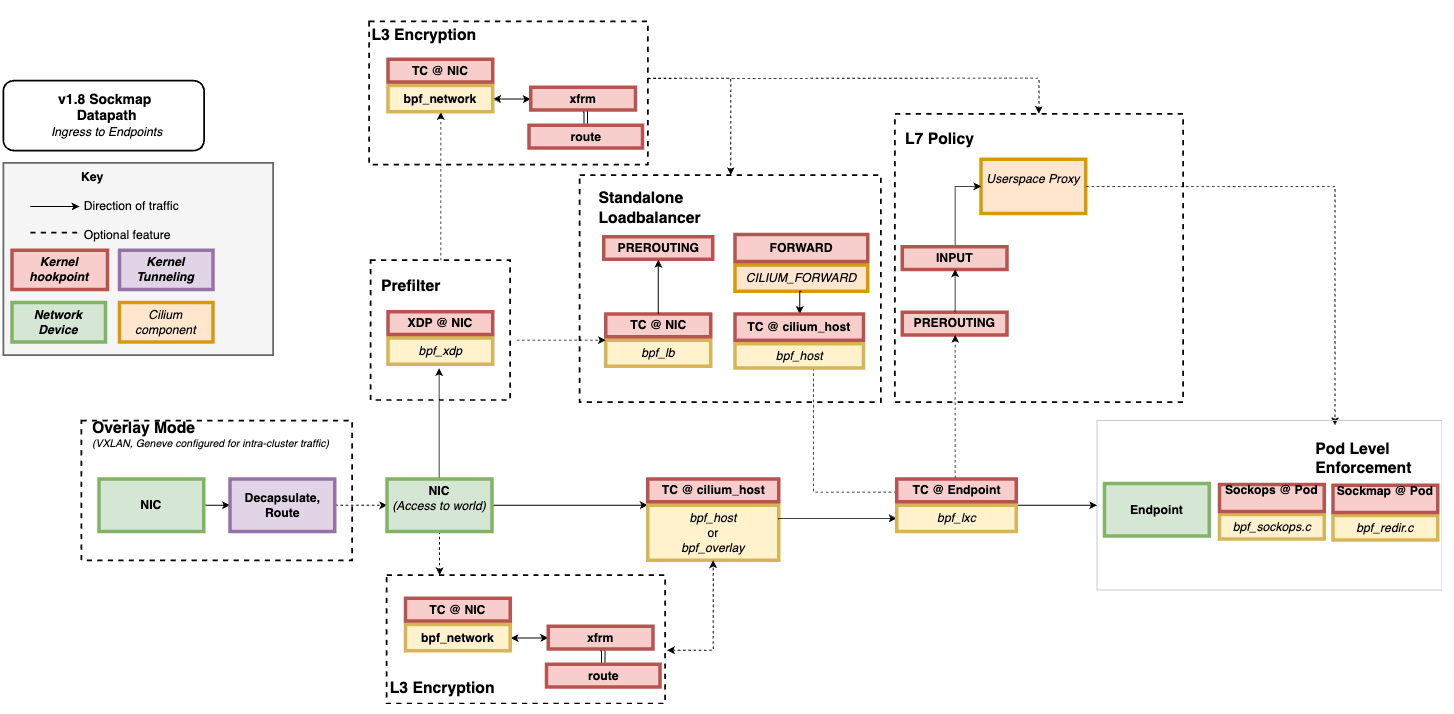
2.4.3.5 其他类 eBPF 程序
除了上面的跟踪和网络 eBPF 程序之外,Linux 内核还支持很多其他的类型。这些类型的 eBPF 程序虽然不太常用,但在需要的时候也可以帮解决很多特定的问题。